
Python開發基礎--- Event對象、隊列和多進程基礎
Event對象
用於線程間通信,即程序中的其一個線程需要通過判斷某個線程的狀態來確定自己下一步的操作,就用到了event對象
event對象默認為假(Flase),即遇到event對象在等待就阻塞線程的執行。
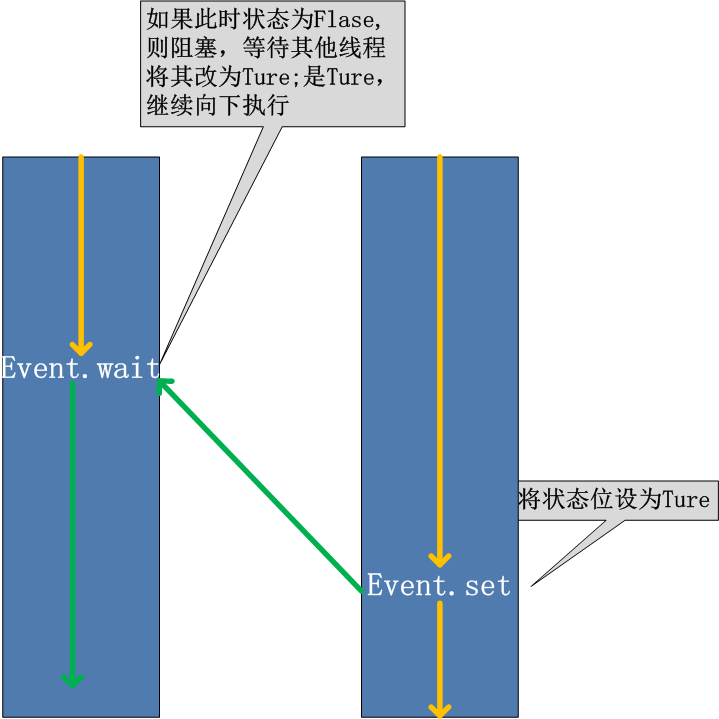
示例1:主線程和子線程間通信,代碼模擬連接服務器

1 import threading 2 import time 3 event=threading.Event() 4 5 def foo(): 6 print(‘wait server...‘) 7 event.wait() #括號裏可以帶數字執行,數字表示等待的秒數,不帶數字表示一直阻塞狀態 8 print(‘connect to server‘) 9 10 t=threading.Thread(target=foo,args=()) #子線程執行foo函數 11 t.start() 12 time.sleep(3) 13 print(‘start server successful‘) 14 time.sleep(3) 15 event.set() #默認為False,set一次表示True,所以子線程裏的foo函數解除阻塞狀態繼續執行
示例2:子線程與子線程間通信
1 import threading 2 import time 3 event=threading.Event() 4 5 def foo(): 6 print(‘wait server...‘) 7 event.wait() #括號裏可以帶數字執行,數字表示等待的秒數,不帶數字表示一直阻塞狀態 8 print(‘connect to server‘) 9 def start(): 10 time.sleep(3) 11 print(‘start server successful‘) 12 time.sleep(3) 13 event.set() #默認為False,set一次表示True,所以子線程裏的foo函數解除阻塞狀態繼續執行 14 t=threading.Thread(target=foo,args=()) #子線程執行foo函數 15 t.start() 16 t2=threading.Thread(target=start,args=()) #子線程執行start函數 17 t2.start()
示例3: 多線程阻塞
1 import threading
2 import time
3
4 event=threading.Event()
5 def foo():
6 while not event.is_set(): #返回event的狀態值,同isSet
7 print("wait server...")
8 event.wait(2) #等待2秒,如果狀態為False,打印一次提示繼續等待
9 print("connect to server")
10
11 for i in range(5): #5個子線程同時等待
12 t=threading.Thread(target=foo,args=())
13 t.start()
14
15 print("start server successful")
16 time.sleep(10)
17 event.set() # 設置標誌位為True,event.clear()是回復event的狀態值為False
queue隊列
隊列是一只數據結構,數據存放方式類似於列表,但是取數據的方式不同於列表。
隊列的數據有三種方式:
1、先進先出(FIFO),即哪個數據先存入,取數據的時候先取哪個數據,同生活中的排隊買東西
2、先進後出(LIFO),同棧,即哪個數據最後存入的,取數據的時候先取,同生活中手槍的彈夾,子彈最後放入的先打出
3、優先級隊列,即存入數據時候加入一個優先級,取數據的時候優先級最高的取出

代碼實現
先進先出:put存入和get取出
1 import queue 2 import threading 3 import time 4 q=queue.Queue(5) #加數字限制隊列的長度,最多能夠存入5個數據,有取出才能繼續存入 5 def put(): 6 for i in range(100): #順序存入數字0到99 7 q.put(i) 8 time.sleep(1) #延遲存入數字,當隊列中沒有數據的時候,get函數取數據的時候會阻塞,直到有數據存入後才從阻塞狀態釋放取出新數據 9 def get(): 10 for i in range(100): #從第一個數字0開始取,直到99 11 print(q.get()) 12 13 t1=threading.Thread(target=put,args=()) 14 t1.start() 15 t2=threading.Thread(target=get,args=()) 16 t2.start()
先進先出:join阻塞和task_done信號
1 import queue 2 import threading 3 import time 4 q=queue.Queue(5) #加數字限制長度 5 def put(): 6 for i in range(100): 7 q.put(i) 8 q.join() #阻塞進程,直到所有任務完成,取多少次數據task_done多少次才行,否則最後的ok無法打印 9 print(‘ok‘) 10 11 def get(): 12 for i in range(100): 13 print(q.get()) 14 q.task_done() #必須每取走一個數據,發一個信號給join 15 # q.task_done() #放在這沒用,因為join實際上是一個計數器,put了多少個數據, 16 #計數器就是多少,每task_done一次,計數器減1,直到為0才繼續執行 17 18 t1=threading.Thread(target=put,args=()) 19 t1.start() 20 t2=threading.Thread(target=get,args=()) 21 t2.start()
先進後出:
1 import queue 2 import threading 3 import time 4 5 q=queue.LifoQueue() 6 def put(): 7 for i in range(100): 8 q.put(i) 9 q.join() 10 print(‘ok‘) 11 12 def get(): 13 for i in range(100): 14 print(q.get()) 15 q.task_done() 16 17 t1=threading.Thread(target=put,args=()) 18 t1.start() 19 t2=threading.Thread(target=get,args=()) 20 t2.start()
按優先級:不管是數字、字母、列表、元組等(字典、集合沒測),使用優先級存數據取數據,隊列中的數據必須是同一類型,都是按照實際數據的ascii碼表的順序進行優先級匹配,漢字是按照unicode表(親測)
列表
1 import queue 2 q=queue.PriorityQueue() 3 q.put([1,‘aaa‘]) 4 q.put([1,‘ace‘]) 5 q.put([4,333]) 6 q.put([3,‘afd‘]) 7 q.put([5,‘4asdg‘]) 8 #1是級別最高的, 9 while not q.empty():#不為空時候執行 10 print(q.get())
元組
1 import queue 2 q=queue.PriorityQueue() 3 q.put((1,‘aaa‘)) 4 q.put((1,‘ace‘)) 5 q.put((4,333)) 6 q.put((3,‘afd‘)) 7 q.put((5,‘4asdg‘)) 8 while not q.empty():#不為空時候執行 9 print(q.get())
漢字
1 import queue 2 q=queue.PriorityQueue() 3 q.put(‘我‘) 4 q.put(‘你‘) 5 q.put(‘他‘) 6 q.put(‘她‘) 7 q.put(‘ta‘) 8 while not q.empty(): 9 print(q.get())
生產者與消費者模型
在線程世界裏,生產者就是生產數據的線程,消費者就是消費數據的線程。在多線程開發當中,如果生產者處理速度很快,而消費者處理速度很慢,那麽生產者就必須等待消費者處理完,才能繼續生產數據。同樣的道理,如果消費者的處理能力大於生產者,那麽消費者就必須等待生產者。為了解決這個問題於是引入了生產者和消費者模式。
生產者消費者模式是通過一個容器來解決生產者和消費者的強耦合問題。生產者和消費者彼此之間不直接通訊,而通過阻塞隊列來進行通訊,所以生產者生產完數據之後不用等待消費者處理,直接扔給阻塞隊列,消費者不找生產者要數據,而是直接從阻塞隊列裏取,阻塞隊列就相當於一個緩沖區,平衡了生產者和消費者的處理能力。
這就像,在餐廳,廚師做好菜,不需要直接和客戶交流,而是交給前臺,而客戶去飯菜也不需要不找廚師,直接去前臺領取即可,這也是一個結耦的過程。
1 import time,random
2 import queue,threading
3
4 q = queue.Queue()
5
6 def Producer(name):
7 count = 0
8 while count <10:
9 print("making........")
10 time.sleep(random.randrange(3))
11 q.put(count)
12 print(‘Producer %s has produced %s baozi..‘ %(name, count))
13 count +=1
14 #q.task_done()
15 #q.join()
16 print("ok......")
17 def Consumer(name):
18 count = 0
19 while count <10:
20 time.sleep(random.randrange(4))
21 if not q.empty():
22 data = q.get()
23 #q.task_done()
24 #q.join()
25 print(data)
26 print(‘\033[32;1mConsumer %s has eat %s baozi...\033[0m‘ %(name, data))
27 else:
28 print("-----no baozi anymore----")
29 count +=1
30
31 p1 = threading.Thread(target=Producer, args=(‘A‘,))
32 c1 = threading.Thread(target=Consumer, args=(‘B‘,))
33 # c2 = threading.Thread(target=Consumer, args=(‘C‘,))
34 # c3 = threading.Thread(target=Consumer, args=(‘D‘,))
35 p1.start()
36 c1.start()
37 # c2.start()
38 # c3.start()
多進程基礎
由於GIL的存在,python中的多線程其實並不是真正的多線程,如果想要充分地使用多核CPU的資源,在python中大部分情況需要使用多進程
多進程優點:可以利用多核、實現並行運算
多進程缺點:切換開銷太大、進程間通信困難
multiprocessing模塊
multiprocessing包是Python中的多進程管理包。與threading.Thread類似,它可以利用multiprocessing.Process對象來創建一個進程。該進程可以運行在Python程序內部編寫的函數。該Process對象與Thread對象的用法相同,也有start(), run(), join()的方法。此外multiprocessing包中也有Lock/Event/Semaphore/Condition類 (這些對象可以像多線程那樣,通過參數傳遞給各個進程),用以同步進程,其用法與threading包中的同名類一致。所以,multiprocessing的很大一部份與threading使用同一套API,只不過換到了多進程的環境。
計算密集型串行計算:計算結果大概25秒左右
1 import time 2 3 def foo(n): #計算0到1億的和 4 ret=0 5 for i in range(n): 6 ret+=i 7 print(ret) 8 9 def bar(n): #計算1到10萬的乘積 10 ret=1 11 for i in range(1,n): 12 ret*=i 13 print(ret) 14 if __name__ == ‘__main__‘: 15 s=time.time() 16 foo(100000000) 17 bar(100000) 18 print(time.time()-s)
計算密集型多進程計算:計算結果13秒左右
1 import multiprocessing 2 import time 3 4 def foo(n): 5 ret=0 6 for i in range(n): 7 ret+=i 8 print(ret) 9 10 def bar(n): 11 ret=1 12 for i in range(1,n): 13 ret*=i 14 print(ret) 15 16 if __name__ == ‘__main__‘: 17 s=time.time() 18 p1 = multiprocessing.Process(target=foo,args=(100000000,)) #創建子進程,target: 要執行的方法;name: 進程名(可選);args/kwargs: 要傳入方法的參數。 19 p1.start() #同樣調用的是類的run方法 20 p2 = multiprocessing.Process(target=bar,args=(100000,) ) #創建子進程 21 p2.start() 22 p1.join() 23 p2.join() 24 print(time.time()-s)
繼承類用法
1 from multiprocessing import Process 2 import time 3 4 class MyProcess(Process): 5 def __init__(self): 6 super(MyProcess, self).__init__() 7 # self.name = name 8 9 def run(self): 10 print (‘hello‘, self.name,time.ctime()) 11 time.sleep(1) 12 13 if __name__ == ‘__main__‘: 14 p_list=[] 15 for i in range(3): 16 p = MyProcess() 17 p.start() 18 p_list.append(p) 19 20 for p in p_list: 21 p.join() 22 23 print(‘end‘)
方法示例
1 from multiprocessing import Process
2 import os
3 import time
4
5 def info(name):
6 print("name:",name)
7 print(‘parent process:‘, os.getppid()) #獲取父進程的id號
8 print(‘process id:‘, os.getpid()) #獲取當前進程pid
9 print("------------------")
10 time.sleep(5)
11 if __name__ == ‘__main__‘:
12 info(‘main process‘) #第一次獲取的是ide工具的進程和該代碼文件的進程
13 p1 = Process(target=info, args=(‘alvin‘,)) #該代碼文件的進程和p1的進程
14 p1.start()
15 p1.join()
對象實例的方法
實例方法: is_alive():返回進程是否在運行。 join([timeout]):阻塞當前上下文環境的進程程,直到調用此方法的進程終止或到達指定的timeout(可選參數)。 start():進程準備就緒,等待CPU調度 run():strat()調用run方法,如果實例進程時未制定傳入target,這star執行t默認run()方法。 terminate():不管任務是否完成,立即停止工作進程 屬性: daemon:和線程的setDeamon功能一樣 name:進程名字。 pid:進程號。
Python開發基礎--- Event對象、隊列和多進程基礎