
極限存儲--歷史拉鏈表(上)
在數據倉庫的數據模型設計過程中,經常會遇到這樣的需求:
1. 數據量比較大;
2. 表中的部分字段會被update,如用戶的地址,產品的描述信息,訂單的狀態等等;
3. 需要查看某一個時間點或者時間段的歷史快照信息,比如,查看某一個訂單在歷史某一個時間點的狀態,
比如,查看某一個用戶在過去某一段時間內,更新過幾次等等;
4. 變化的比例和頻率不是很大,比如,總共有1000萬的會員,每天新增和發生變化的有10萬左右;
5. 如果對這邊表每天都保留一份全量,那麽每次全量中會保存很多不變的信息,對存儲是極大的浪費;
拉鏈歷史表,既能滿足反應數據的歷史狀態,又可以最大程度的節省存儲;
舉個簡單例子,比如有一張訂單表,6月20號有3條記錄:

到6月21日,表中有5條記錄:

到6月22日,表中有6條記錄:

數據倉庫中對該表的保留方法:
1. 只保留一份全量,則數據和6月22日的記錄一樣,如果需要查看6月21日訂單001的狀態,則無法滿足;
2. 每天都保留一份全量,則數據倉庫中的該表共有14條記錄,但好多記錄都是重復保存,沒有任務變化,如訂單002,004,數據量大了,會造成很大的存儲浪費;
如果在數據倉庫中設計成歷史拉鏈表保存該表,則會有下面這樣一張表:
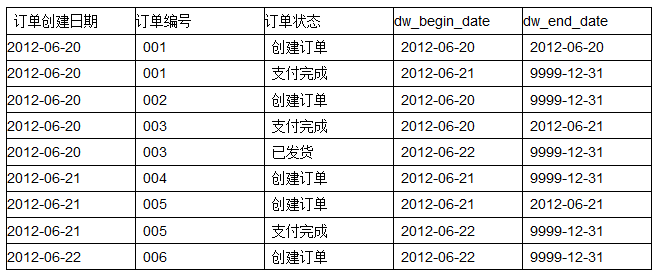
說明:
1. dw_begin_date表示該條記錄的生命周期開始時間,dw_end_date表示該條記錄的生命周期結束時間;
2. dw_end_date = ‘9999-12-31‘表示該條記錄目前處於有效狀態;
3. 如果查詢當前所有有效的記錄,則select * from order_his where dw_end_date = ‘9999-12-31‘
4. 如果查詢2012-06-21的歷史快照,則select * from order_his where dw_begin_date <= ‘2012-06-21‘ and end_date >= ‘2012-06-21‘,這條語句會查詢到以下記錄: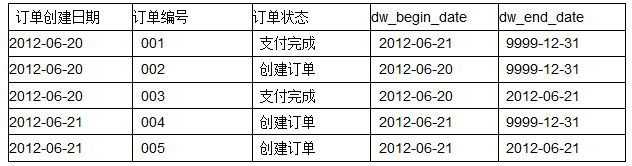
和源表在6月21日的記錄完全一致:

可以看出,這樣的歷史拉鏈表,既能滿足對歷史數據的需求,又能很大程度的節省存儲資源;
極限存儲--歷史拉鏈表(上)