
『cs231n』Faster_RCNN(待續)
前言
研究了好一陣子深度學習在計算機視覺方面的實際應用意義不大的奇技淫巧,感覺基本對研究生生涯的工作沒啥直接的借鑒意義,硬說收獲的話倒是加深了對tensorflow的理解,是時候回歸最初的興趣點——物體檢測了,實際上對cs231n的Faster RCNN講解理解的不是很好,當然這和課上講的比較簡略也是有關系的,所以特地重新學習一下,參考文章鏈接在這,另:
Faster RCNN github : https://github.com/rbgirshick/py-faster-rcnn
Faster RCNN paper : https://arxiv.org/abs/1506.01497
綜述
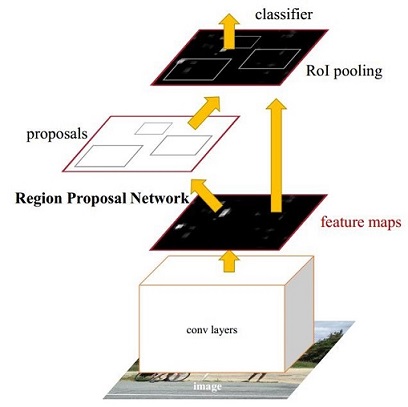
圖1 Faster CNN基本結構(來自原論文)
如圖1,Faster RCNN可以分為四個部分:
- Conv layers: Faster RCNN首先使用CNN網絡提取image的feature maps;
- Region Proposal Networks: RPN網絡用於生成region proposals,該層通過softmax判斷anchors屬於foreground或者background,再利用bounding box regression修正anchors獲得精確的proposals;
- Roi Pooling: 該層收集輸入的feature maps和proposals,綜合這些信息後提取proposal feature maps,送入後續全連接層判定目標類別;
- Classification: 利用proposal feature maps計算proposal的類別,同時再次bounding box regression獲得檢測框最終的精確位置。
所以本文以上述4個內容作為切入點介紹Faster RCNN網絡。
圖2展示了Python版本中的VGG16模型中的faster_rcnn_test.pt的網絡結構:
- 對於任意大小PxQ的圖像,首先縮放至固定大小MxN,然後將MxN圖像送入網絡;
- Conv layers中包含了13個conv層+13個relu層+4個pooling層;
- RPN網絡首先經過3x3卷積,再分別生成foreground anchors與bounding box regression偏移量,然後計算出proposals;
- Roi Pooling層則利用proposals從feature maps中提取proposal feature送入後續全連接和softmax網絡作classification(即分類proposal到底是什麽object)。
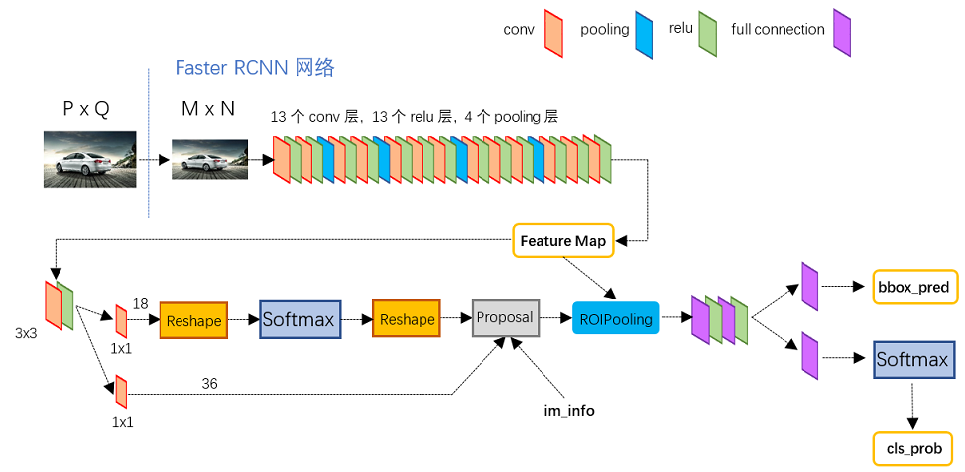
圖2 faster_rcnn_test.pt網絡結構
網絡結構介紹
1、Conv layers
對於VGG16模型(原論文使用的模型),所有的卷積層使用了3*3的卷積核,既是最優的卷積核大小並padding,然後poling層使用的2*2大小過濾器,步長取2,也就是每一次池化後尺寸縮短1/2,Conv layers部分共有13個conv層,13個relu層,4個pooling層,這樣MxN大小的矩陣經過Conv layers固定變為(M/16)x(N/16),當然這本身並沒什麽值得介紹的,主要是這揭示了Conv layers生成的feature map和原圖對應的關系實際上是簡單的映射過來的。
2、Region Proposal Networks(RPN)
傳統的滑動窗口+圖像金字塔生成檢測框以及RCNN使用SS(Selective Search)方法生成檢測框的過程是十分耗時的,Faster RCNN的主要創新之處也正在於此:RPN生成檢測框的方法能極大提升檢測框的生成速度。

圖3 RPN網絡結構
上圖3展示了RPN網絡的具體結構,可以看到RPN網絡實際分為2條線:
- 上面一條通過softmax分類anchors獲得foreground和background(檢測目標是foreground);
- 下面一條用於計算對於anchors的bounding box regression偏移量,以獲得精確的proposal。
而最後的Proposal層則負責綜合foreground anchors和bounding box regression偏移量獲取proposals,同時剔除太小和超出邊界的proposals。其實整個網絡到了Proposal Layer這裏,就完成了相當於目標定位的功能。
2.1 anchors
提到RPN網絡,就不能不說anchors。所謂anchors,實際上就是一組由rpn/generate_anchors.py生成的矩形。直接運行demo中的generate_anchors.py可以得到以下輸出:
[[ -84. -40. 99. 55.]
[-176. -88. 191. 103.]
[-360. -184. 375. 199.]
[ -56. -56. 71. 71.]
[-120. -120. 135. 135.]
[-248. -248. 263. 263.]
[ -36. -80. 51. 95.]
[ -80. -168. 95. 183.]
[-168. -344. 183. 359.]]
其中每行的4個值[x1,y1,x2,y2]代表矩形左上和右下角點坐標。9個矩形共有3種形狀,長寬比為大約為:width:height = [1:1, 1:2, 2:1]三種,如圖4,實際上通過anchors就引入了檢測中常用到的多尺度方法:

圖4 anchors示意圖
【註】:關於上面的anchors size,是根據網絡輸入圖像設置的,在python demo中,會把任意大小的輸入圖像reshape成800x600(即圖2中的M=800,N=600),再看anchors的大小,anchors中長寬1:2中最大為352x704,長寬2:1中最大736x384,基本是cover了800x600的各個尺度和形狀。

圖5
解釋一下圖5:
- Conv Layers最後生成256張特征圖,所以相當於feature map每個點都是256-d;
- Conv Layers之後,做了rpn_conv/3x3卷積且輸出深度256,相當於每個點又融合了周圍3x3的空間信息,同時256-d不變,註意卷積層不改變圖片大小,即(M/16)x(N/16)不變;
- 假設在conv5 feature map中每個點上有k個anchor(默認k=9),而每個anhcor要分foreground和background,所以每個點由256d feature轉化為cls=2k scores,而每個anchor都有[x, y, w, h]對應4個偏移量,所以reg=4k coordinates;
- 補充一點,全部anchors拿去訓練太多了,訓練程序會在合適的anchors中隨機選取128個postive anchors+128個negative anchors進行訓練。
【註1】:之前了解Faster RCNN時最為費解的部分就是上面的第3條,實際上結合cs231n課程中介紹的定位任務(單目標)就比較容易理解了,這實際上和把定位任務分化為分類+回歸是一個原理,對於同一個輸入分別設計得分網絡(分類)和坐標網絡進行學習。
【註2】:在本文講解中使用的VGG conv5 num_output=512,所以是512d,其他類似.....
2.2 softmax判定foreground與background
接上面的參數,RPN網絡輸入為(M/16)x(N/16),設W=M/16,H=N/16。這一步實際就是一個1x1卷積或者是全連接,如圖6:

圖6 RPN中判定fg/bg網絡結構
1x1卷積其輸出深度18(相當於全連接層),也就是經過該卷積的輸出圖像為WxHx18大小,對應了feature maps每一個點都有9個anchors,同時每個anchors又有可能是foreground和background。
2.4 bounding box regression原理
3、Roi Pooling
『cs231n』Faster_RCNN(待續)