
淺談Key-value 存儲——SILT
摘要:本文以文章SILT: A Memory Efficient High Performance Key-Value Store 為基礎,探討SILT存儲系統是如何實現內存占用低和高性能的設計目標,從SILT系統架構入手,依次簡述系統的三個基本組成部分Logstore、Hashstore和SortedStore。
- 前言
現代操作系統提供了文件系統作為存取和管理信息的機構,文件的邏輯組織形式分流式文件和記錄式文件,文件的物理組織結構可分為連續文件、串聯文件和隨機文件[1],在我認為SILT存儲系統是隨機文件結構的一個擴展應用。又因為SILT是基於固態盤的單節點存儲系統,了解固態盤讀寫的性能是至關重要的。固態盤被看做是存儲領域的革命性產品,相比磁盤,固態盤的隨機讀寫性能要高很多,能耗低,抗震,但是價格也更貴,壽命更短。下圖1是基於NAND Flash的固態盤的讀寫示意圖,我們可以看到隨機寫將造成失效Page隨機分布在各個Block上,擦除Block需要大量數據遷移,相當於放大了寫操作;如果是順序寫,失效Page將集中在少量Block中,擦除Block需要較少的數據遷移,因此性能更高[2]。可見隨機寫操作對性能和壽命的影響很大,因此針對固態盤的上層應用SILT存儲系統在設計時盡量避免了隨機寫操作。
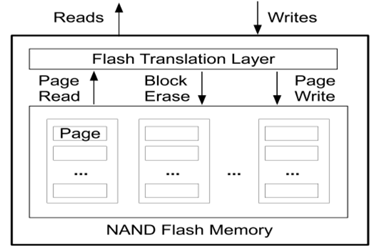
圖 1 固態盤存取示意圖
- SILT存儲系統設計目標
2.1 各種key-value store 的對比
Key-Value Store 對於當今大規模、高性能的數據敏感型應用來說已經成為一個至關重要的設計模塊。因此,在諸多領域高性能的key-value stores 的設計均受到重點關註,如電商平臺[3]、數據去重中心[4,5,6]、圖像存儲[7]和web對象緩存[8,9]等等。那怎樣才算是一個好的Key-value store,文章中給的目標是低延遲、高性能、充分利用有效的I/O資源。在這樣的目標,各類頂級會議上湧現出了大量基於固態盤設計的Key-Value Store,[email protected]
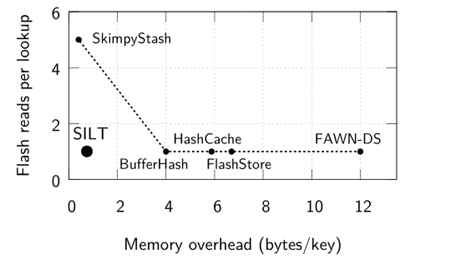
圖2 SILT和其它幾種KVS產品在內存開銷和查詢性能的比較
2.2 SILT系統的設計目標
SILT的設計遵循以下五個目標:
(1)較低的讀放大:對於單個Get請求,只觸發1+ε次flash read操作。其中ε是很小且可配置的值。(作者認為即使使用的固態盤,flash隨機讀仍然是系統讀性能瓶頸, 這是相對於內存計算而言,包括哈希表計算等 )
(2)可控的寫放大,支持順序寫:每個KV pair,在它的生命周期內(被刪除前),被寫了多少(垃圾回收等操作都會導致重復寫一個KV pair, SILT的一個值得關註的缺陷是寫放大,因此作者強調了可控 )。系統能夠避免隨機寫,支持順序寫。
(3)使用較少的內存索引:log-structure不可避免地需要內存索引結構,SILT盡量減少使用內存。(DRAM仍然相當昂貴,且能耗過高, SILT的優勢是將內存壓縮到極致)
(4)降低內存索引的計算開銷:SILT的內存索引的計算開銷必須很低,使得SILT能夠充分利用固態盤的吞吐率IOPS。( SILT的計算開銷主要包括哈希表計算、排序、解壓縮等 )
(5)高效利用固態盤空間:為了提高查詢和插入性能,SILT的一些數據布局很稀疏,但是總體的空間利用率必須很高。( 我認為作者說的數據布局主要是SILT的HashStore,它的利用率最多達到93%,另一個需要註意的是SILT的Merge操作,需要2倍的固態盤空間才能完成 )
傳統的Key-Value Store采用Single-Store設計,它們通常包括三個部件:
1.內存過濾器:高效地判斷一個Key是否存在,避免去固態盤查找不存在的Key。典型的數據結構是Bloom Filter;
2.內存索引:高效地定位固態盤上的Key,典型數據結構是哈希表;
3.一個適合固態盤的數據布局,例如log-structure。
作者認為當時的Key-Value Store無法滿足所有五個目標。比如SkimpyStash的內存開銷很少,但是讀放大嚴重;ChunStash和FlashStore的讀很高效,但是內存開銷太大。事實上,Single-Store的設計很難達到目標。SILT采用了Multi-Store的設計,如圖三所示是SILT的系統架構圖,每個Store都有不同的設計目標:
1.LogStore:針對讀、寫優化,但是內存開銷大,最新寫入的數據在這裏。
2.SortedStore:不可寫,讀性能較高,但比LogStore弱,內存開銷極小,大部分數據放在這裏;
3.HashStore:不可寫,讀性能等於LogStore,內存開銷比LogStore少,比Sort

圖3 SILT存儲系統架構圖
2.3 SILT讀寫操作
LogStore是log-structure,負責處理Put和Delete操作。LogStore使用一個內存哈希表將key映射到其在固態盤的位置,哈希表可以同時起到filter和index的作用。因為每個key都需要一個4字節的指針,因此內存開銷很大。LogStore一旦滿了,就會被轉換為HashStore,HashStore是臨時的,引入HashStore是為了避免頻繁合並SortedStore。HashStore按key的哈希順序存儲數據,因此不需要內存索引,而是使用內存開銷更少的filter。當HashStore的數量達到上限,就會批量地合並到SortedStore。SortedStore按key的自然順序排序,然後用前綴樹表示,通過結合壓縮算法,可以達到非常低的內存開銷。
每次插入操作,都將KV pair寫入LogStore。刪除操作相當於插入了一個"delete"。每次查詢操作,依次查詢LogStore,HashStore,和SortedStore,一旦找到就立刻停止搜索,返回結果。如果找到了"delete",說明數據已經被刪了,則返回。
4 LogStore的設計
LogStore的主要目的是處理Put請求,它將新的數據順序寫到固態盤上,並在內存中用一個哈希表檢索。普通的哈希表利用率只有50%,因此重點是如何設計哈希表,盡可能高效地利用內存。
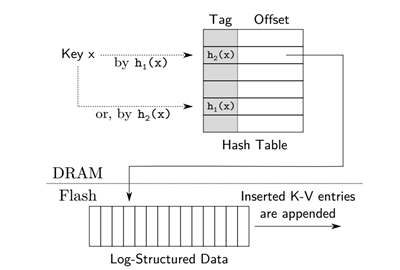
圖4 Logstore設計結構
如圖4所示是 Logstore設計結構, SILT使用布谷哈希表,它使用兩個哈希函數h1和h2,將每個key映射到兩個候選位置,key必然存在候選位置,因此綁定查詢開銷的上限,同時無需保存指針( 內存開銷低,這是相比鏈表法的優勢 )。當插入一個key時,存在任意空的候選位置就插入成功了;否則,需要踢掉一個位置的key,被踢掉key需要被放置到它另外一個候選位置上。這個過程可能需要重復多次才能安排好所有的key,重復次數過多(例如128次)意味著哈希表接近滿了。為了節約內存,SILT並不在哈希表內存放完整的key,而是僅僅一個key的"tag"。查詢key時,只有當tag匹配時,才會進一步訪問固態盤。只存放一個tag並不是布谷哈希的標準做法,因為踢出操作需要使用完整的key才能計算另一個候選位置,這就導致被踢的key需要讀固態盤才能進行計算。SILT的辦法是用key的tag指向另一個候選位置,這樣踢出一個key時,就根據tag找到另一個候選位置,並將舊候選位置設為新的tag。
標準的布谷哈希表達到50%的裝填因子後,沖突就變得很難解決。為了增加利用率,SILT允許每個候選位置存放四個key的tag。SILT的實驗表明,這樣做可以將裝填因子上升到93%。因為SILT假設key本身是哈希值,可以直接在key上取15 bits作為tag,當然兩個哈希函數取的位置是不覆蓋的。因此每個KV pair有15 bit的tag,4字節的指針,和1 bit的有效位(是否刪除),一共是6個字節。
5 HashStore的設計
直接將LogStore合並到SortedStore會增加寫放大,保留多個LogStore會增加內存開銷。因此,當LogStore滿的時候(即嘗試了一定次數後仍無法為所有key找到合適的位置),SILT會將LogStore轉換為HashStore,HashStore是只讀的。當積累了一定數量的HashStore後,再批量地合並到SortedStore。在轉化LogStore的過程中,舊LogStore仍然提供查詢功能,由新的LogStore提供插入功能。如圖5是Hashstore的設計結構。

圖5 HashStore的設計
HashStore中的KV pairs在固態盤上按哈希的順序排列,因此是一個固態盤上的哈希表,有著和LogStore一樣的裝載因子93%。HashStore將LogStore的哈希表中的指針去掉,只保留tag。因此每個key的內存開銷2.15字節。查詢一個key時,如果匹配了tag,就根據tag的位置去固態盤上讀key。因為沒有指針,內存開銷大大降低,保留的tag起到了filter的作用,避免去固態盤查找不存在的key。HashStore的沖突概率與LogStore一樣。
6 結語
通讀整篇文章[10],我認為該文提出的SILT存儲系統很好的解決了Key-value store系統中的讀放大問題,除此索引文件的設計滿足較低的內存占用率和高效的利用率,但不足的是並沒有解決系統中存在的寫放大問題,在垃圾回收和批量整合的過程中存在很明顯的寫放大問題。
參考文獻:
【1】操作系統原理
【2】大話雲存儲
【3】G. DeCandia, D. Hastorun, M. Jampani, G. Kakulapati, A. Lakshman, A. Pilchin, S. Sivasub-ramanian, P. Vosshall, and W. Vogels. Dynamo: Amazon‘s highly available key-value store.In Proc. 21st ACM Symposium on Operating Systems Principles (SOSP), Stevenson, WA, Oct.2007.
【4】[1] A. Anand, C. Muthukrishnan, S. Kappes, A. Akella, and S. Nath. Cheap and large CAMs for high performance data-intensive networked systems. In NSDI‘10: Proceedings of the 7th USENIX conference on Networked systems design and implementation, pages 29–29.
【5】[19] B. Debnath, S. Sengupta, and J. Li. FlashStore: High throughput persistent key-value store. Proc.VLDB Endowment, 3:1414–1425, September 2010
【6】[20] B. Debnath, S. Sengupta, and J. Li. SkimpyStash: RAM space skimpy key-value store onflash-based storage. In Proc. International Conference on Management of Data, ACM SIGMOD‘11, pages 25–36, New York, NY, USA, 2011.
[7][7] D. Beaver, S. Kumar, H. C. Li, J. Sobel, and P. Vajgel. Finding a needle in Haystack: Facebook‘s photo storage. In Proc. 9th USENIX OSDI, Vancouver, Canada, Oct. 2010.
[8][4] A. Badam, K. Park, V. S. Pai, and L. L. Peterson. HashCache: Cache storage for the next billion.In Proc. 6th USENIX NSDI, Boston, MA, Apr. 2009.
淺談Key-value 存儲——SILT