
Spark 學習筆記之 MONGODB SPARK CONNECTOR 插入性能測試
MONGODB SPARK CONNECTOR
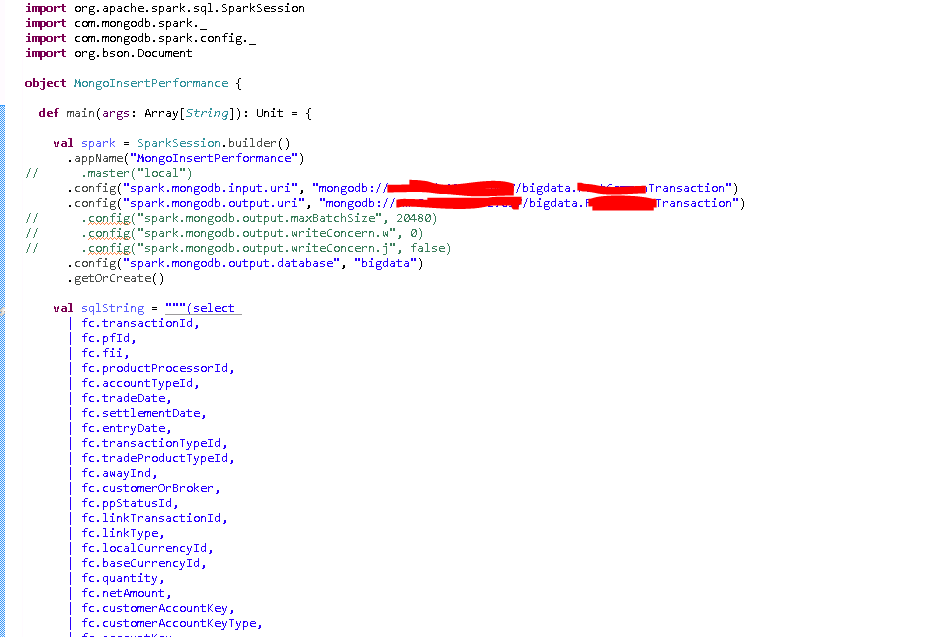
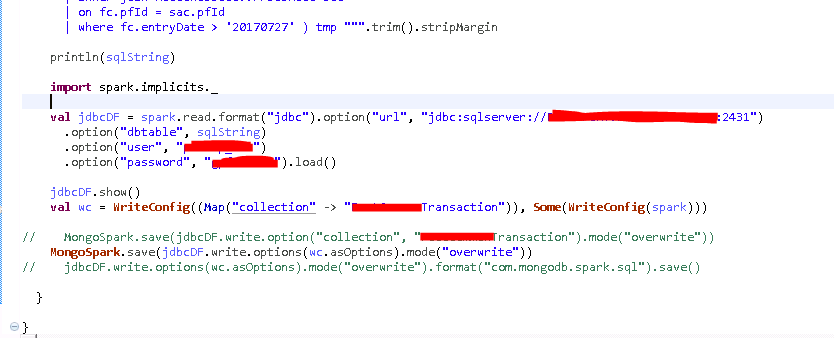
測試數據量:

測試結果:
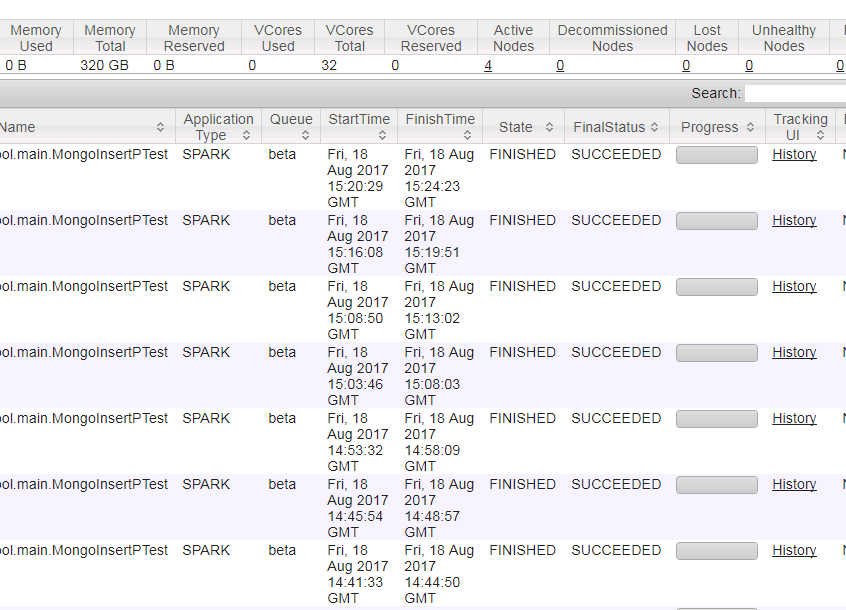
116萬數據通過4個表的join,從SQL Server查出,耗時1分多。MongoSparkConnector插入平均耗時:3分30秒。
總計耗時4分半-5分鐘。
Spark 學習筆記之 MONGODB SPARK CONNECTOR 插入性能測試
相關推薦
Spark 學習筆記之 MONGODB SPARK CONNECTOR 插入性能測試
log font span 技術 strong mongos str server 學習 MONGODB SPARK CONNECTOR 測試數據量: 測試結果: 116萬數據通過4個表的join,從SQL Server查出,耗時1分多。MongoSp
Spark 學習筆記之 Standalone與Yarn啟動和運行時間測試
span ima 上傳 運行 yarn erl 技術分享 word wordcount Standalone與Yarn啟動和運行時間測試: 寫一個簡單的wordcount: 打包上傳運行: Standalone啟動: 運行時間:
Spark 學習筆記之 Streaming Window
min .cn spa pan tex def rec mas clas Streaming Window: 上圖意思:每隔2秒統計前3秒的數據 slideDuration: 2 windowDuration: 3 例子: import org.apach
spark學習筆記之二:寬依賴和窄依賴
1.如果父RDD裡的一個partition只去向一個子RDD裡的partition為窄依賴,否則為寬依賴(只要是shuffle操作)。 2.spark根據運算元判斷寬窄依賴: 窄依賴:map
Spark學習筆記之-Spark遠端除錯
Spark遠端除錯 本例子介紹簡單介紹spark一種遠端除錯方法,使用的IDE是IntelliJ IDEA。 1、瞭解jvm一些引數屬性 -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=y,addres
Spark學習筆記之WordCount
1.pom.xml <dependencies> <!-- 匯入scala的依賴 --&g
學習筆記之MongoDB進階(一)
MongoDB的條件操作符 MongoDB中條件操作符有: (>) 大於 - $gt (<) 小於 - $lt (>=) 大於等於 - $gte (<= ) 小於等於 - $lte $gt -------- greater than
學習筆記之MongoDB基礎命令
1.選擇資料庫 命令: use DATEBASE_NAME(資料庫名) 作用:若沒有該資料庫則直接建立,若有則切換資料庫 執行效果如下: use runoob switched to db runoob db runoob
Spark學習筆記1:Spark概覽
Spark是一個用來實現快速而通用的叢集計算的平臺。 Spark專案包含多個緊密整合的元件。Spark的核心是一個對由很多計算任務組成的,執行在多個工作機器或者是一個計算叢集上的應用進行排程,分發以及監控的計算引擎。Sark核心引擎有著速度快和通用的特點,因此Spark支援
Spark學習筆記:初識Spark
=。= // 將users中的vertex屬性新增到graph中,生成graph2 // 使用joinVertices操作,用user中的屬性替換圖中對應Id的屬性 // 先將圖中的頂點屬
Hadoop學習筆記之三:用MRUnit做單元測試
引言 借年底盛宴品鑑之風,繼續抒我Hadoop之情,本篇文章介紹如何對Hadoop的MapReduce進行單元測試。MapReduce的開發週期差不多是這樣:編寫mapper和reducer、編譯、打包、提交作業和結果檢索等,這個過程比較繁瑣,一旦提交到分散式環境出了問題要定位除錯,重複這樣的過程實在無趣
go 學習筆記之僅僅需要一個示例就能講清楚什麼閉包
本篇文章是 Go 語言學習筆記之函數語言程式設計系列文章的第二篇,上一篇介紹了函式基礎,這一篇文章重點介紹函式的重要應用之一: 閉包 空談誤國,實幹興邦,以具體程式碼示例為基礎講解什麼是閉包以及為什麼需要閉包等問題,下面我們沿用上篇文章的示例程式碼開始本文的學習吧! 斐波那契數列是形如 1 1 2 3 5
大資料學習筆記之spark及spark streaming----快速通用計算引擎
導語 spark 已經成為廣告、報表以及推薦系統等大資料計算場景中首選系統,因效率高,易用以及通用性越來越得到大家的青睞,我自己最近半年在接觸spark以及spark streaming之後,對spark技術的使用有一些自己的經驗積累以及心得體會,在此分享給大家。 本文依
大資料學習筆記之三十 Spark介紹之一
Spark簡介 主要用來加快資料分析的執行和讀寫速度 基於MapReduce演算法實現的分散式計算,在擁有Hadoop MapReduce所有優點的基礎上,其任務的中間結果還可以儲存在記憶體中,查詢速度快 處理迭代演算法(機器學習、圖挖掘演算法)和互動式資料探
Spark學習筆記——文本處理技術
使用 ken ins main 最小 leg tran sparse rain 1.建立TF-IDF模型 import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.mllib.lin
Spark學習筆記——泰坦尼克生還預測
cti build case model 學習筆記 classes gre dict path package kaggle import org.apache.spark.SparkContext import org.apache.spark.SparkConf i
MongoDB 學習筆記之 權限管理基礎
顯示 命令 修改 技術 sky 需要 bad 官方 改密碼 權限管理基礎 MongoDB有很多用戶roles,這裏只是簡單列舉下命令的使用,具體的role的含義,請查閱官方文檔。 https://docs.mongodb.com/manual/reference/bui
Spark學習筆記(一)
-s 環境 從數據 多個 成了 lib one python ted 概念: Spark是加州大學伯克利分校AMP實驗室,開發的通用內存並行計算框架。 支持用scala、java和Python等語言編寫應用程序。相較於Hdoop,往往有更好的運行效率。 Spark包括了Sp
MongoDB 學習筆記之 分片和副本集混合運用
comment ssm table mmap insert ise class 學習 urn 分片和副本集混合運用: 基本架構圖: 搭建詳細配置: 3個shard + 3個replicat set + 3個configserver + 3個Mongos sh
MongoDB 學習筆記之 手動預先分片
var http strong str 可見 mongod 手動 ++ 1-1 手動預先分片: 目的:手動預先分片是為了防止未來chunk的移動,減少IO。 sh.shardCollection("shop.users",{"userId": 1 }) for(v