
大資料學習筆記之spark及spark streaming----快速通用計算引擎
導語
spark 已經成為廣告、報表以及推薦系統等大資料計算場景中首選系統,因效率高,易用以及通用性越來越得到大家的青睞,我自己最近半年在接觸spark以及spark streaming之後,對spark技術的使用有一些自己的經驗積累以及心得體會,在此分享給大家。
本文依次從spark生態,原理,基本概念,spark streaming原理及實踐,還有spark調優以及環境搭建等方面進行介紹,希望對大家有所幫助。
spark 生態及執行原理
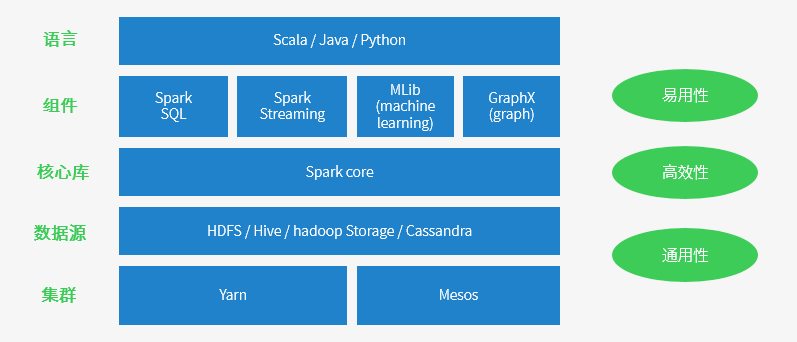
Spark 特點
-
執行速度快 => Spark擁有DAG執行引擎,支援在記憶體中對資料進行迭代計算。官方提供的資料表明,如果資料由磁碟讀取,速度是Hadoop MapReduce的10倍以上,如果資料從記憶體中讀取,速度可以高達100多倍。
-
適用場景廣泛 => 大資料分析統計,實時資料處理,圖計算及機器學習
-
易用性 => 編寫簡單,支援80種以上的高階運算元,支援多種語言,資料來源豐富,可部署在多種叢集中
-
容錯性高。Spark引進了彈性分散式資料集RDD (Resilient Distributed Dataset) 的抽象,它是分佈在一組節點中的只讀物件集合,這些集合是彈性的,如果資料集一部分丟失,則可以根據“血統”(即充許基於資料衍生過程)對它們進行重建。另外在RDD計算時可以通過CheckPoint來實現容錯,而CheckPoint有兩種方式:CheckPoint Data,和Logging The Updates,使用者可以控制採用哪種方式來實現容錯。
Spark的適用場景
目前大資料處理場景有以下幾個型別:
-
複雜的批量處理(Batch Data Processing),偏重點在於處理海量資料的能力,至於處理速度可忍受,通常的時間可能是在數十分鐘到數小時;
-
基於歷史資料的互動式查詢(Interactive Query),通常的時間在數十秒到數十分鐘之間
-
基於實時資料流的資料處理(Streaming Data Processing),通常在數百毫秒到數秒之間
Spark成功案例
目前大資料在網際網路公司主要應用在廣告、報表、推薦系統等業務上。在廣告業務方面需要大資料做應用分析、效果分析、定向優化等,在推薦系統方面則需要大資料優化相關排名、個性化推薦以及熱點點選分析等。這些應用場景的普遍特點是計算量大、效率要求高。
騰訊 / yahoo / 淘寶 / 優酷土豆
spark執行架構
spark基礎執行架構如下所示:
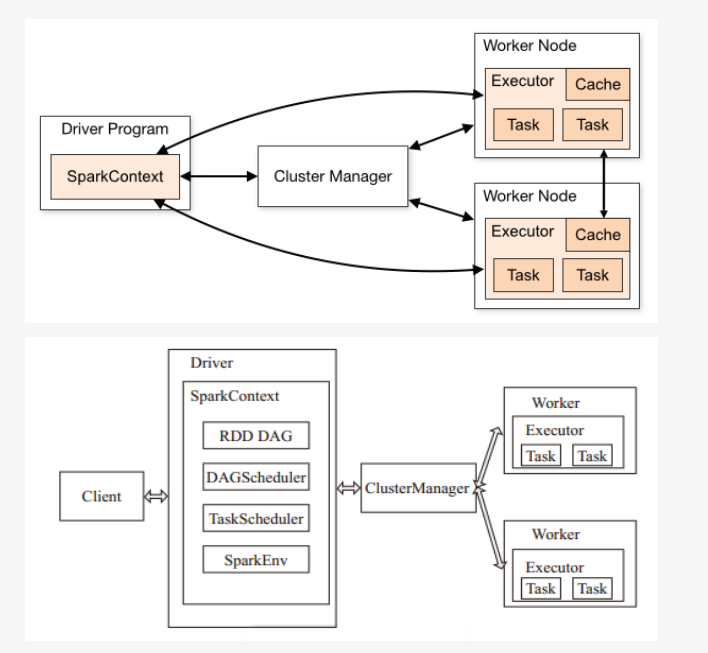
spark結合yarn叢集背後的執行流程如下所示:
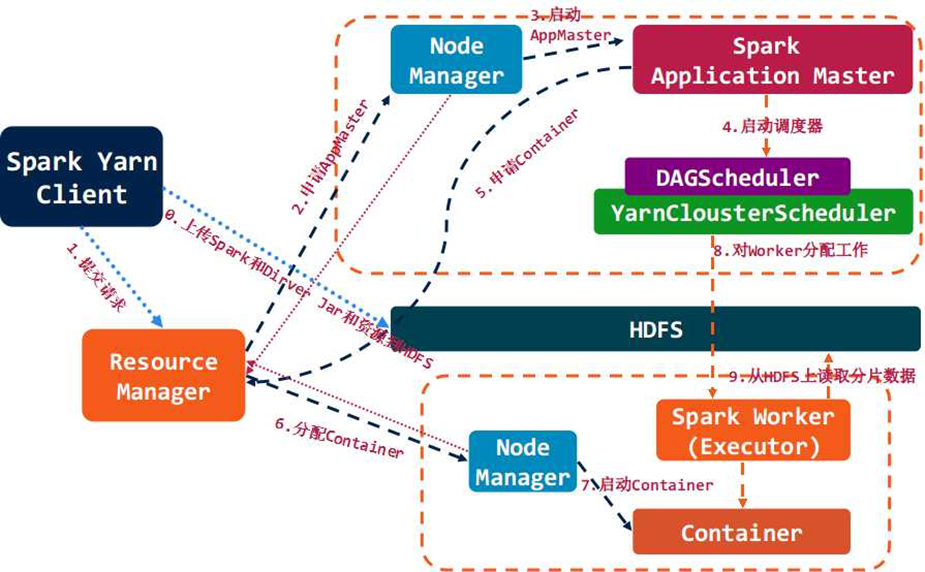
spark 執行流程:
Spark架構採用了分散式計算中的Master-Slave模型。Master是對應叢集中的含有Master程序的節點,Slave是叢集中含有Worker程序的節點。
-
Master作為整個叢集的控制器,負責整個叢集的正常執行;
-
Worker相當於計算節點,接收主節點命令與進行狀態彙報;
-
Executor負責任務的執行;
-
Client作為使用者的客戶端負責提交應用;
-
Driver負責控制一個應用的執行。
Spark叢集部署後,需要在主節點和從節點分別啟動Master程序和Worker程序,對整個叢集進行控制。在一個Spark應用的執行過程中,Driver和Worker是兩個重要角色。Driver 程式是應用邏輯執行的起點,負責作業的排程,即Task任務的分發,而多個Worker用來管理計算節點和建立Executor並行處理任務。在執行階段,Driver會將Task和Task所依賴的file和jar序列化後傳遞給對應的Worker機器,同時Executor對相應資料分割槽的任務進行處理。
-
Excecutor /Task 每個程式自有,不同程式互相隔離,task多執行緒並行
-
叢集對Spark透明,Spark只要能獲取相關節點和程序
-
Driver 與Executor保持通訊,協作處理
三種叢集模式:
1.Standalone 獨立叢集
2.Mesos, apache mesos
3.Yarn, hadoop yarn
基本概念:
-
Application =>Spark的應用程式,包含一個Driver program和若干Executor
-
SparkContext => Spark應用程式的入口,負責排程各個運算資源,協調各個Worker Node上的Executor
-
Driver Program => 執行Application的main()函式並且建立SparkContext
-
Executor => 是為Application執行在Worker node上的一個程序,該程序負責執行Task,並且負責將資料存在記憶體或者磁碟上。每個Application都會申請各自的Executor來處理任務
-
Cluster Manager =>在叢集上獲取資源的外部服務 (例如:Standalone、Mesos、Yarn)
-
Worker Node => 叢集中任何可以執行Application程式碼的節點,執行一個或多個Executor程序
-
Task => 執行在Executor上的工作單元
-
Job => SparkContext提交的具體Action操作,常和Action對應
-
Stage => 每個Job會被拆分很多組task,每組任務被稱為Stage,也稱TaskSet
-
RDD => 是Resilient distributed datasets的簡稱,中文為彈性分散式資料集;是Spark最核心的模組和類
-
DAGScheduler => 根據Job構建基於Stage的DAG,並提交Stage給TaskScheduler
-
TaskScheduler => 將Taskset提交給Worker node叢集執行並返回結果
-
Transformations => 是Spark API的一種型別,Transformation返回值還是一個RDD,所有的Transformation採用的都是懶策略,如果只是將Transformation提交是不會執行計算的
-
Action => 是Spark API的一種型別,Action返回值不是一個RDD,而是一個scala集合;計算只有在Action被提交的時候計算才被觸發。
Spark核心概念之RDD
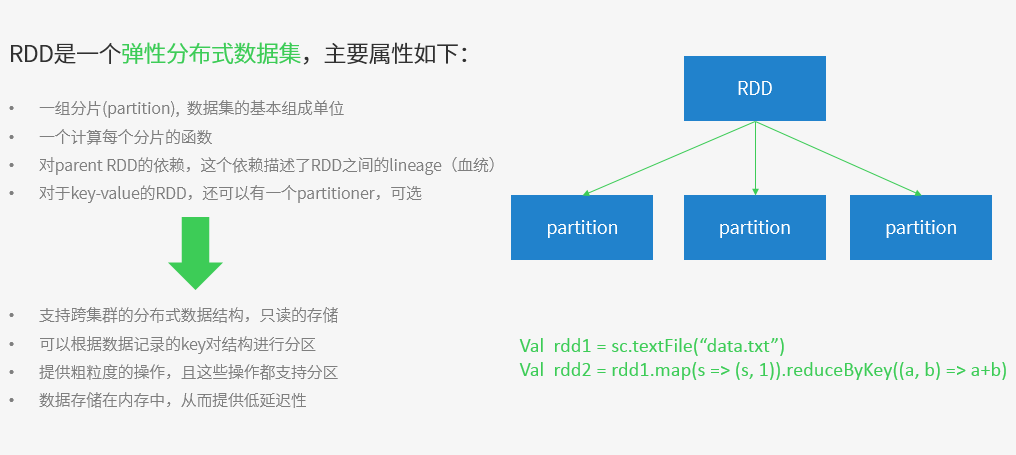
Spark核心概念之Transformations / Actions
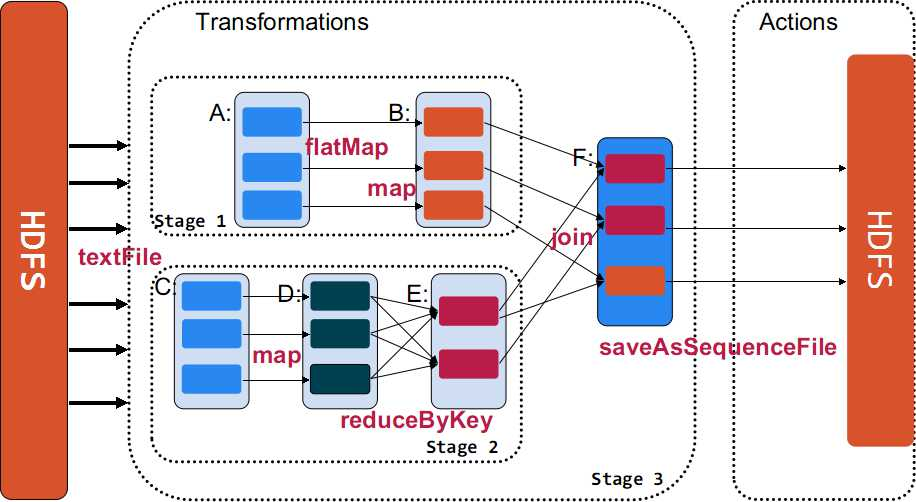
Transformation返回值還是一個RDD。它使用了鏈式呼叫的設計模式,對一個RDD進行計算後,變換成另外一個RDD,然後這個RDD又可以進行另外一次轉換。這個過程是分散式的。 Action返回值不是一個RDD。它要麼是一個Scala的普通集合,要麼是一個值,要麼是空,最終或返回到Driver程式,或把RDD寫入到檔案系統中。
Action是返回值返回給driver或者儲存到檔案,是RDD到result的變換,Transformation是RDD到RDD的變換。
只有action執行時,rdd才會被計算生成,這是rdd懶惰執行的根本所在。
Spark核心概念之Jobs / Stage
Job => 包含多個task的平行計算,一個action觸發一個job
stage => 一個job會被拆為多組task,每組任務稱為一個stage,以shuffle進行劃分
Spark核心概念之Shuffle
以reduceByKey為例解釋shuffle過程。
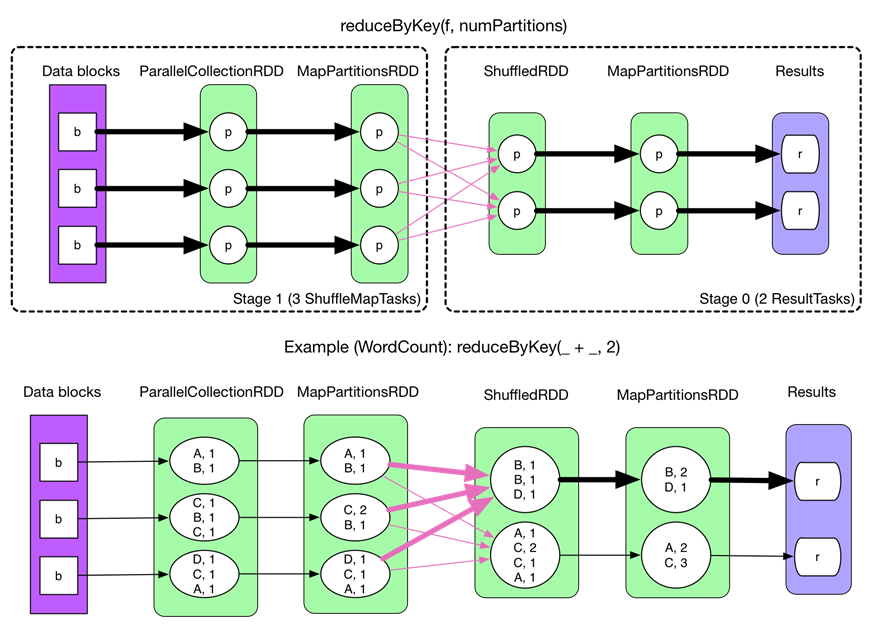
在沒有task的檔案分片合併下的shuffle過程如下:(spark.shuffle.consolidateFiles=false)

fetch 來的資料存放到哪裡?
剛 fetch 來的 FileSegment 存放在 softBuffer 緩衝區,經過處理後的資料放在記憶體 + 磁碟上。這裡我們主要討論處理後的資料,可以靈活設定這些資料是“只用記憶體”還是“記憶體+磁碟”。如果spark.shuffle.spill = false就只用記憶體。由於不要求資料有序,shuffle write 的任務很簡單:將資料 partition 好,並持久化。之所以要持久化,一方面是要減少記憶體儲存空間壓力,另一方面也是為了 fault-tolerance。
shuffle之所以需要把中間結果放到磁碟檔案中,是因為雖然上一批task結束了,下一批task還需要使用記憶體。如果全部放在記憶體中,記憶體會不夠。另外一方面為了容錯,防止任務掛掉。
存在問題如下:
-
產生的 FileSegment 過多。每個 ShuffleMapTask 產生 R(reducer 個數)個 FileSegment,M 個 ShuffleMapTask 就會產生 M * R 個檔案。一般 Spark job 的 M 和 R 都很大,因此磁碟上會存在大量的資料檔案。
-
緩衝區佔用記憶體空間大。每個 ShuffleMapTask 需要開 R 個 bucket,M 個 ShuffleMapTask 就會產生 MR 個 bucket。雖然一個 ShuffleMapTask 結束後,對應的緩衝區可以被回收,但一個 worker node 上同時存在的 bucket 個數可以達到 cores R 個(一般 worker 同時可以執行 cores 個 ShuffleMapTask),佔用的記憶體空間也就達到了cores× R × 32 KB。對於 8 核 1000 個 reducer 來說,佔用記憶體就是 256MB。
為了解決上述問題,我們可以使用檔案合併的功能。
在進行task的檔案分片合併下的shuffle過程如下:(spark.shuffle.consolidateFiles=true)
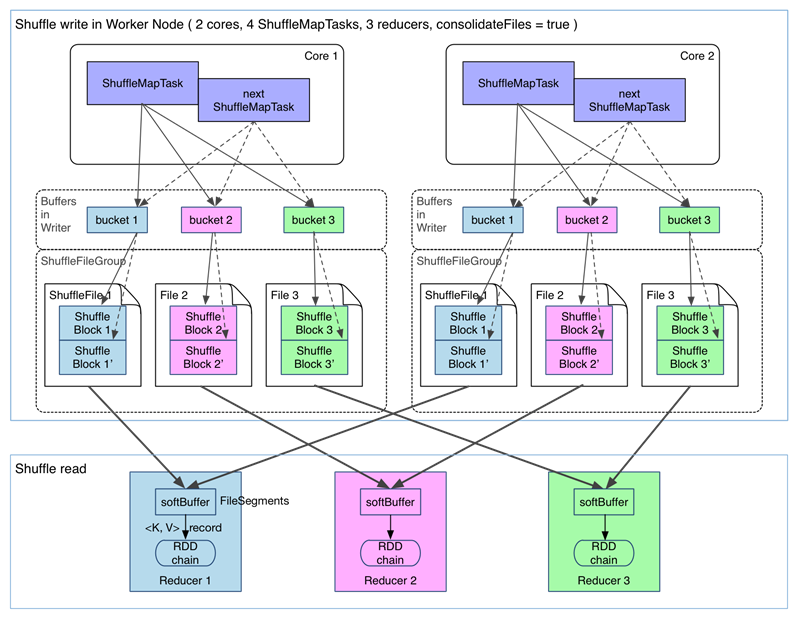
可以明顯看出,在一個 core 上連續執行的 ShuffleMapTasks 可以共用一個輸出檔案 ShuffleFile。先執行完的 ShuffleMapTask 形成 ShuffleBlock i,後執行的 ShuffleMapTask 可以將輸出資料直接追加到 ShuffleBlock i 後面,形成 ShuffleBlock i',每個 ShuffleBlock 被稱為 FileSegment。下一個 stage 的 reducer 只需要 fetch 整個 ShuffleFile 就行了。這樣,每個 worker 持有的檔案數降為 cores× R。FileConsolidation 功能可以通過spark.shuffle.consolidateFiles=true來開啟。
Spark核心概念之Cache
val rdd1 = ... // 讀取hdfs資料,載入成RDD
rdd1.cache
val rdd2 = rdd1.map(...)
val rdd3 = rdd1.filter(...)
rdd2.take(10).foreach(println)
rdd3.take(10).foreach(println)
rdd1.unpersist
cache和unpersisit兩個操作比較特殊,他們既不是action也不是transformation。cache會將標記需要快取的rdd,真正快取是在第一次被相關action呼叫後才快取;unpersisit是抹掉該標記,並且立刻釋放記憶體。只有action執行時,rdd1才會開始建立並進行後續的rdd變換計算。
cache其實也是呼叫的persist持久化函式,只是選擇的持久化級別為MEMORY_ONLY。
persist支援的RDD持久化級別如下:

需要注意的問題:
Cache或shuffle場景序列化時, spark序列化不支援protobuf message,需要java 可以serializable的物件。一旦在序列化用到不支援java serializable的物件就會出現上述錯誤。
Spark只要寫磁碟,就會用到序列化。除了shuffle階段和persist會序列化,其他時候RDD處理都在記憶體中,不會用到序列化。
Spark Streaming執行原理
spark程式是使用一個spark應用例項一次性對一批歷史資料進行處理,spark streaming是將持續不斷輸入的資料流轉換成多個batch分片,使用一批spark應用例項進行處理。
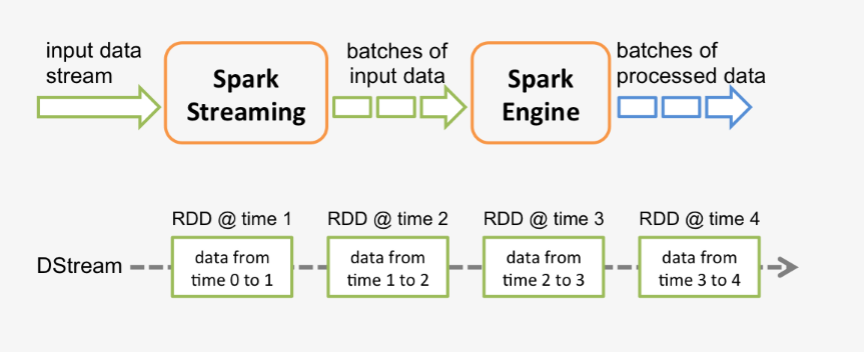
從原理上看,把傳統的spark批處理程式變成streaming程式,spark需要構建什麼?
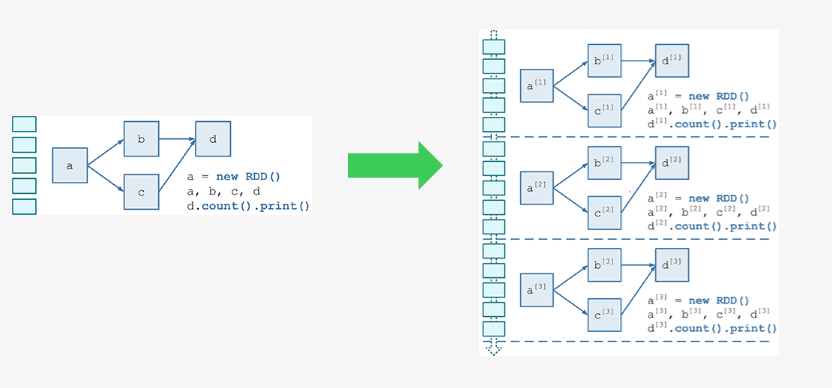
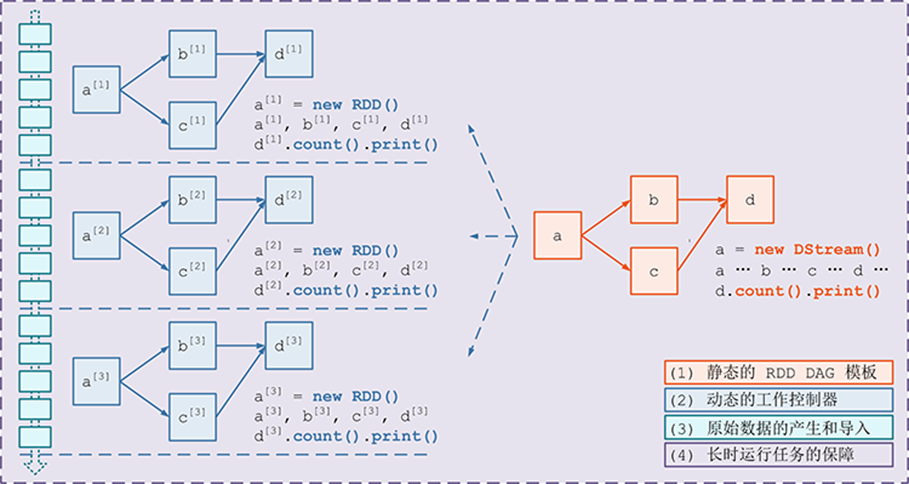
需要構建4個東西:
-
一個靜態的 RDD DAG 的模板,來表示處理邏輯;
-
一個動態的工作控制器,將連續的 streaming data 切分資料片段,並按照模板複製出新的 RDD ;
-
DAG 的例項,對資料片段進行處理;
-
Receiver進行原始資料的產生和匯入;Receiver將接收到的資料合併為資料塊並存到記憶體或硬碟中,供後續batch RDD進行消費;
-
對長時執行任務的保障,包括輸入資料的失效後的重構,處理任務的失敗後的重調。
具體streaming的詳細原理可以參考廣點通出品的原始碼解析文章:
對於spark streaming需要注意以下三點:
- 儘量保證每個work節點中的資料不要落盤,以提升執行效率。
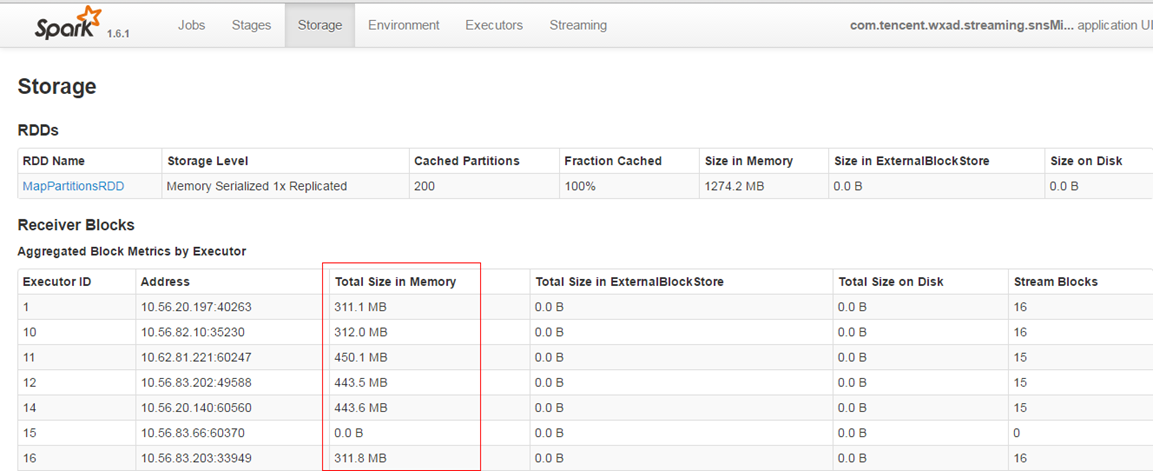
- 保證每個batch的資料能夠在batch interval時間內處理完畢,以免造成資料堆積。
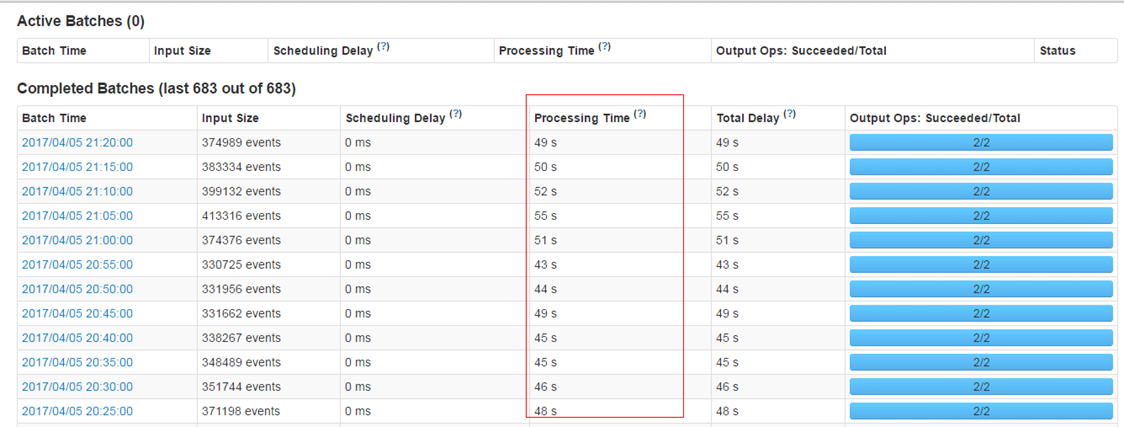
- 使用steven提供的框架進行資料接收時的預處理,減少不必要資料的儲存和傳輸。從tdbank中接收後轉儲前進行過濾,而不是在task具體處理時才進行過濾。
Spark 資源調優
記憶體管理:
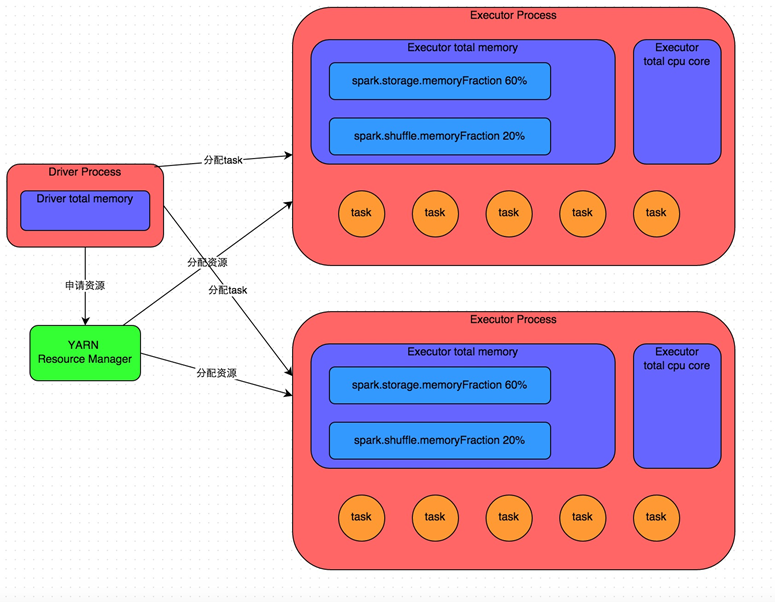
Executor的記憶體主要分為三塊:
第一塊是讓task執行我們自己編寫的程式碼時使用,預設是佔Executor總記憶體的20%;
第二塊是讓task通過shuffle過程拉取了上一個stage的task的輸出後,進行聚合等操作時使用,預設也是佔Executor總記憶體的20%;
第三塊是讓RDD持久化時使用,預設佔Executor總記憶體的60%。
每個task以及每個executor佔用的記憶體需要分析一下。每個task處理一個partiiton的資料,分片太少,會造成記憶體不夠。
其他資源配置:

具體調優可以參考美團點評出品的調優文章:
Spark 環境搭建
spark tdw以及tdbank api文件:
其他學習資料: