
Spark SQL
阿新 • • 發佈:2017-08-25
mapr bsp 單機 模塊 ont 比較 分布 整合 技術
1.1. Spark SQL概述
1.1.1. 什麽是Spark SQL
Spark SQL是Spark用來處理結構化數據的一個模塊,它提供了一個編程抽象叫做DataFrame並且作為分布式SQL查詢引擎的作用。
1.1.2. 為什麽要學習Spark SQL
我們已經學習了Hive,它是將Hive SQL轉換成MapReduce然後提交到集群上執行,大大簡化了編寫MapReduce的程序的復雜性,由於MapReduce這種計算模型執行效率比較慢。所以Spark SQL的應運而生,它是將Spark SQL轉換成RDD,然後提交到集群執行,執行效率非常快!
1.易整合

2.統一的數據訪問方式

3.兼容Hive
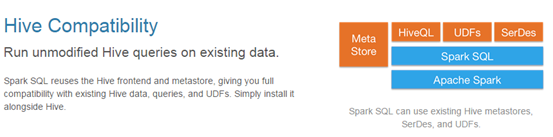
4.標準的數據連接

1.1. DataFrames
1.1.1. 什麽是DataFrames
與RDD類似,DataFrame也是一個分布式數據容器。然而DataFrame更像傳統數據庫的二維表格,除了數據以外,還記錄數據的結構信息,即schema。同時,與Hive類似,DataFrame也支持嵌套數據類型(struct、array和map)。從API易用性的角度上 看,DataFrame API提供的是一套高層的關系操作,比函數式的RDD API要更加友好,門檻更低。由於與R和Pandas的DataFrame類似,Spark DataFrame很好地繼承了傳統單機數據分析的開發體驗。

1.1.2. 創建DataFrames
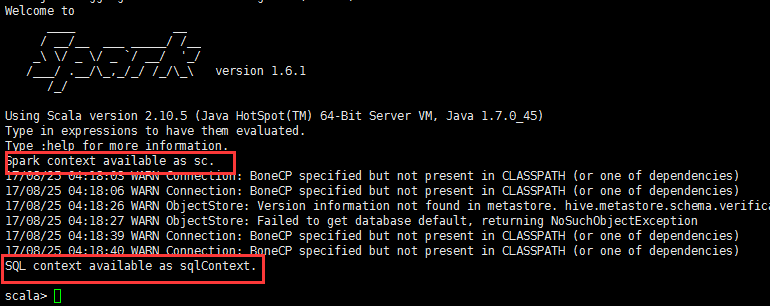
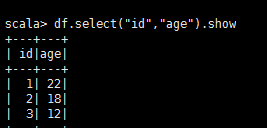
在Spark SQL中SQLContext是創建DataFrames和執行SQL的入口,在spark已經內置了一個sqlContext
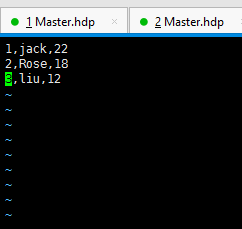
hadoop fs -put person.txt /

Spark SQL