
spark SQL概述

Spark SQL是什麽?
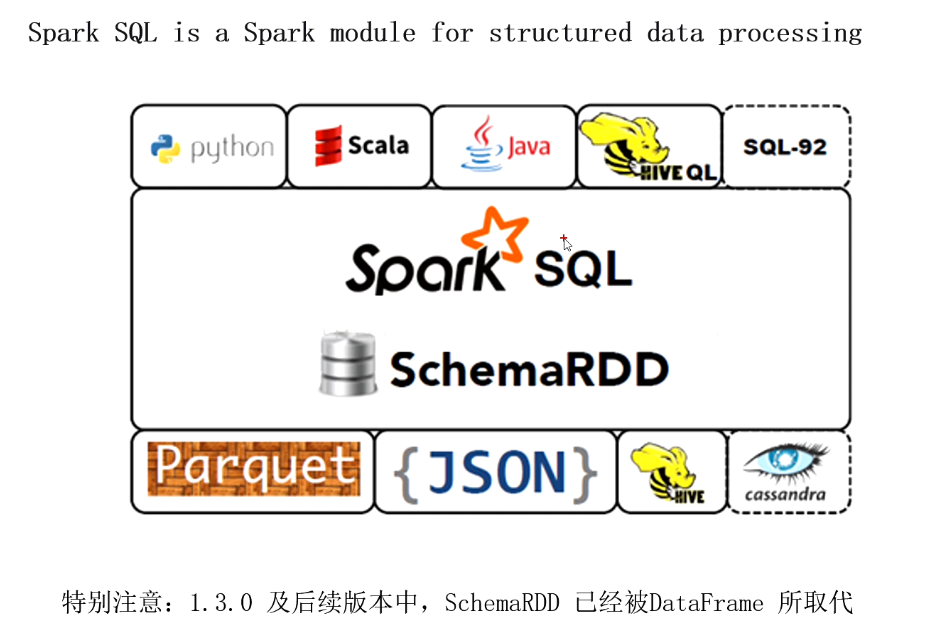
何為結構化數據

sparkSQL與spark Core的關系

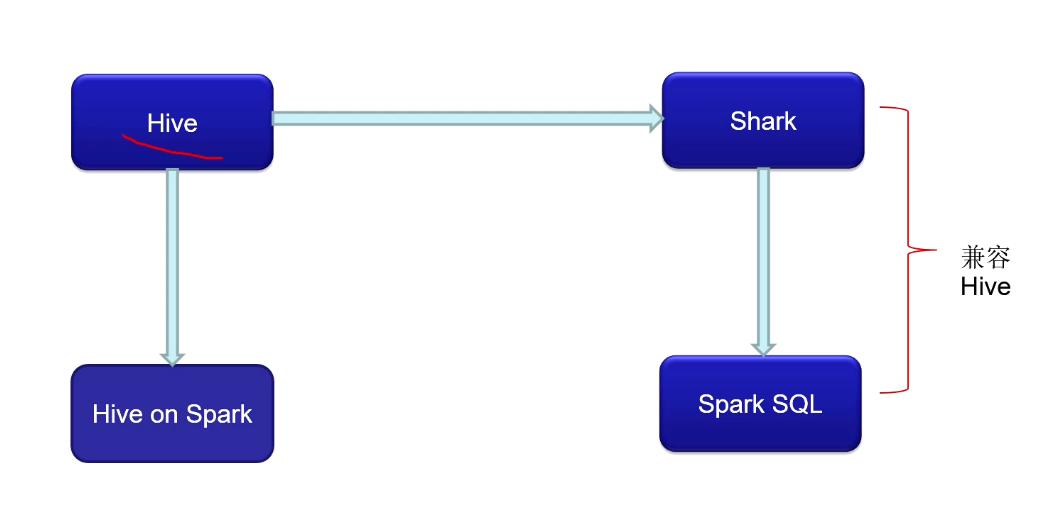
Spark SQL的前世今生:由Shark發展而來

Spark SQL的前世今生:可以追溯到Hive

Spark SQL的前世今生:Hive 到Shark(在Hive上做改進)

Spark SQL的前世今生:Shark 到Spark SQL(徹底擺脫但是兼容Hive)

Spark SQL的前世今生:Hive 到Hive on Spark

spark SQL概述
相關推薦
spark SQL概述
hive 徹底 es2017 ima img cor com font size Spark SQL是什麽? 何為結構化數據 sparkSQL與spark Core的關系 Spark SQL的前世今生:由Shark發展而來 Spark
SparkSQL(1)——Spark SQL概述
spark sql發展 Shark是一個為Spark設計的大規模資料倉庫系統,它與Hive相容。 Shark建立在Hive的程式碼基礎上,並通過將Hive的部分物理執行計劃交換出來。這個方法使得Shark的使用者可以加速Hive的查詢。 但是Shark繼承了H
第4章 Spark SQL概述
4-1 課程目錄 Spark SQL前世今生 SQL on Hadoop常用框架介紹 Spark SQL概述 Spark SQL願景 Spark SQL架構 4-2 -Spark SQL前世今生 為什麼使用SQL 1)事實上的標準 2)簡單易用 3)受眾面大
SparkSQL(2)——Spark SQL DataFrame概述
DataFrame是什麼? DataFrame的前身是SchemaRDD,從Spark 1.3.0開始SchemaRDD更名為DataFrame。 DataFrame與SchemaRDD的主要區別是:DataFrame不再直接繼承自RDD,而是自己實現了RDD
spark-sql的概述以及程式設計模型的介紹
1、spark sql的概述 (1)spark sql的介紹: Spark SQL 是 Spark 用來處理結構化資料(結構化資料可以來自外部結構化資料來源也可以通 過 RDD 獲取)的一個模組,它提供了一個程式設計抽象叫做 DataFrame 並且作為分散式 SQL 查 詢引擎的作用。 外部的結構
spark-sql的概述以及編程模型的介紹
creat 沒有 解析 互轉 轉換 單機 tps types sha 1、spark sql的概述 (1)spark sql的介紹: Spark SQL 是 Spark 用來處理結構化數據(結構化數據可以來自外部結構化數據源也可以通 過 RDD 獲取
Spark SQL原始碼剖析(一)SQL解析框架Catalyst流程概述
Spark SQL模組,主要就是處理跟SQL解析相關的一些內容,說得更通俗點就是怎麼把一個SQL語句解析成Dataframe或者說RDD的任務。以Spark 2.4.3為例,Spark SQL這個大模組分為三個子模組,如下圖所示 其中Catalyst可以說是Spark內部專門用來解析SQL的一個框架,在H
Spark-Sql之DataFrame實戰詳解
集合 case 編程方式 優化 所表 register 操作數 print ava 1、DataFrame簡介: 在Spark中,DataFrame是一種以RDD為基礎的分布式數據據集,類似於傳統數據庫聽二維表格,DataFrame帶有Schema元信息,即DataFram
Spark SQL編程指南(Python)【轉】
res 平臺 per 它的 split 執行 文件的 分組 不同 轉自:http://www.cnblogs.com/yurunmiao/p/4685310.html 前言 Spark SQL允許我們在Spark環境中使用SQL或者Hive SQL執行關系型查詢。它的核
Spark SQL 源代碼分析之Physical Plan 到 RDD的詳細實現
local 過濾 右連接 操作 images img mem sans 觀察 /** Spark SQL源代碼分析系列文章*/ 接上一篇文章Spark SQL Catalyst源代碼分析之Physical Plan。本文將介紹Physical Plan的toRDD的
spark-sql case when 問題
spark 大數據 hadoop spark-sqlSELECT CASE (pmod(datediff(f0.`4168388__c_0`,‘1970-01-04‘),7)+1) WHEN ‘1‘ THEN ‘星期日‘ WHEN ‘2‘ THEN ‘星期一‘ WHEN ‘3‘ THEN ‘星期二‘ WHE
Spark-Sql整合hive,在spark-sql命令和spark-shell命令下執行sql命令和整合調用hive
type with hql lac 命令 val driver spark集群 string 1.安裝Hive 如果想創建一個數據庫用戶,並且為數據庫賦值權限,可以參考:http://blog.csdn.net/tototuzuoquan/article/details/5
Spark SQL and DataFrame Guide(1.4.1)——之DataFrames
ati been -m displays txt -a 版本 ava form Spark SQL是處理結構化數據的Spark模塊。它提供了DataFrames這樣的編程抽象。同一時候也能夠作為分布式SQL查詢引擎使用。 DataFrames D
Spark SQL
mapr bsp 單機 模塊 ont 比較 分布 整合 技術 1.1. Spark SQL概述 1.1.1. 什麽是Spark SQL Spark SQL是Spark用來處理結構化數據的一個模塊,它提供了一個編程抽象叫做DataFrame並且作為分布式SQL查詢引
Spark SQL 編程
ima art tps ext img rdd point .cn ram Spark SQL的依賴 Spark SQL的入口:SQLContext 官方網站參考 https://spark.apache.org/docs/1.6.2/sql-programmi
Spark SQL 之 Join 實現
結構 很多 找到 過濾 sql查詢優化 ade read 轉換成 分析 原文地址:Spark SQL 之 Join 實現 Spark SQL 之 Join 實現 塗小剛 2017-07-19 217標簽: spark , 數據庫 Join作為SQL中
Spark-SQL連接Hive
ces submit mat targe runt match tms force trying 第一步:修個Hive的配置文件hive-site.xml 添加如下屬性,取消本地元數據服務: <property> <name>hive.
【Spark SQL 源碼分析系列文章】
blog .com data 原創 org 分析 成了 系列 ice 從決定寫Spark SQL源碼分析的文章,到現在一個月的時間裏,陸陸續續差不多快完成了,這裏也做一個整合和索引,方便大家閱讀,這裏給出閱讀順序 :) 第一篇 Spark SQL源碼分析之核心流程
第二篇:Spark SQL Catalyst源碼分析之SqlParser
end from pop tco 循環 -c font 多個 再看 /** Spark SQL源碼分析系列文章*/ Spark SQL的核心執行流程我們已經分析完畢,可以參見Spark SQL核心執行流程,下面我們來分析執行流程中各個核心組件的工作職責。
第一篇:Spark SQL源碼分析之核心流程
example 協議 bst copyto name 分詞 oop 不同 spl /** Spark SQL源碼分析系列文章*/ 自從去年Spark Submit 2013 Michael Armbrust分享了他的Catalyst,到至今1年多了,Spark SQ