
增量式強化學習
線性逼近:
相比較於非線性逼近,線性逼近的好處是只有一個最優值,因此可以收斂到全局最優。其中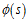 為狀態s處的特征函數,或者稱為基函數。
為狀態s處的特征函數,或者稱為基函數。
常用的基函數的類型為:
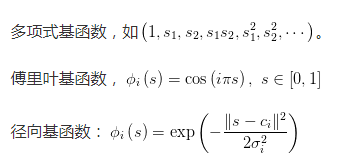
增量式方法參數更新過程隨機性比較大,盡管計算簡單,但樣本數據的利用效率並不高。而批的方法,盡管計算復雜,但計算效率高。
批處理方法:

深度強化學習:
Q-learning方法是異策略時序差分方法。其偽代碼為:

離策略:是指行動策略(產生數據的策略)和要評估的策略不是一個策略。在圖Q-learning 偽代碼中,行動策略(產生數據的策略)是第5行的\varepsilon -greedy策略,而要評估和改進的策略是第6行的貪婪策略(每個狀態取值函數最大的那個動作)。
所謂時間差分方法,是指利用時間差分目標來更新當前行為值函數。在圖1.1 Q-learning偽代碼中,時間差分目標為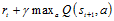 。
。
增量式強化學習
相關推薦
增量式強化學習
增量 name 效率 eps ima 全局最優 全局 技術分享 alt 線性逼近: 相比較於非線性逼近,線性逼近的好處是只有一個最優值,因此可以收斂到全局最優。其中為狀態s處的特征函數,或者稱為基函數。 常用的基函數的類型為: 增量式方法參數更新過程隨機性比較大,盡管計
增量式線上學習:對最先進的演算法進行回顧和比較
翻譯論文:Incremental On-line Learning:A Review and Comparison of State of the Art Algorithms 作者:Viktor Losing, Barbara Hammer, Heiko W
強化學習 相關資源
ren info round count question posit pre tar tor 最近因為某個不可描述的原因需要迅速用強化學習完成一個小實例,但是之前完全不懂強化學習啊,雖然用了人家的代碼但是在找代碼的過程中還是發現了很多不錯的強化學習資源,決定mark下
JavaScript正則表達式的學習
eight 正則 進行 劃線 包括 修飾 特定字符 span har 正則表達式的應用已經相當廣泛,之前也多次接觸,但是並未真正的系統的學習過,借此機會,好好整理了一下,並加入了es6中關於正則表達式的新語法,希望對大家有點幫助. 一、首先,了解正則表達式的含義,表示方法
[分布式系統學習] 6.824 LEC2 RPC和線程 筆記
amp star nbsp 機制 並且 als goroutine 操作 page 6.824的課程通常是在課前讓你做一些準備。一般來說是先讀一篇論文,然後請你提一個問題,再請你回答一個問題。然後上課,然後布置Lab。 第二課的準備-Crawler 第二課的準備不是論文
學習筆記TF037:實現強化學習策略網絡
屬於 控制 返回 獎勵 渲染 動作 ren 虛擬 初始 強化學習(Reinforcement Learing),機器學習重要分支,解決連續決策問題。強化學習問題三概念,環境狀態(Environment State)、行動(Action)、獎勵(Reward),目標獲得最多累
強化學習(David Silver)4:免模型學習
叠代 ack 方差 自舉 組合 a* 最小二乘 求和 效率 0、為什麽免模型學習? PS:課程中叠代的值是值函數;周誌華老師的西瓜書中叠代的是狀態值函數;課程中叠代的是狀態-動作值函數 1、蒙特卡洛方法:直接通過采樣求和(v(s) = S(s)/n(s),其中S(s) =
強化學習(David Silver)4:免模型控制
sil 對比 rsa isod 頻率 模型 找到 使用 采樣 1、一般的策略叠代優化的方法 1)策略評估 2)策略改善 2、model free的策略叠代優化的方法 基於v(s)的優化需要MDP,基於Q的優化不需要,所以策略是 1)使用Q函數策略評估 2)使用厄普西隆貪心策
強化學習(David Silver)6:值函數近似
最優解 學習 前向算法 數據 計算 action 算法 什麽 化學 0、為什麽有值函數近似 狀態空間太大,基於DP/MC/TD的方法的離散值太多,存儲量太大,運行太慢 1、值函數近似有兩種方法 一個是狀態值函數方法;一個是狀態動作值方法 2、值函數近似的三種類型 類型1:輸
Seq2SQL :使用強化學習通過自然語言生成SQL
ati ima sof div sta 領域 不能 分享 普通 論文: https://einstein.ai/static/images/layouts/research/seq2sql/seq2sql.pdf 數據集:https://github.com/salesfo
強化學習
logs .cn nbsp jpg 技術 引用 https -1 知乎 引用自知乎,原文鏈接 https://www.zhihu.com/question/41775291 強化學習
【基礎知識十六】強化學習
動態 sof col -s 範例 如何 差分 ash 抽象 一、任務與獎賞 我們執行某個操作a時,僅能得到一個當前的反饋r(可以假設服從某種分布),這個過程抽象出來就是“強化學習”。 強化學習任務通常用馬爾可夫決策過程MDP來描述: 強化學
數字和表達式(學習筆記)
解釋器 結果 2.0 1.0 解決 imp 整數 oat 小數 1、交互式Python解釋器可以當做非常強大的計算器使用,試試以下的例子: >>> 2 + 2 4 或者 >>> 53762 + 235253 28892
強化學習(David Silver)2:MDP(馬爾科夫決策過程)
war 觀察 turn 解法 求解 有關 馬爾科夫 函數 使用 1、MP(馬爾科夫過程) 1.1、MDP介紹 1)MDP形式化地強化學習中的環境(此時假設環境完全可以觀察) 2) 幾乎所有強化學習問題都可以形式化為MDP(部分可觀察的環境也可以轉化為MDP????) 1.2
強化學習(David Silver)3:動態規劃
哈哈 avi 過程 來源 con 隨機 選擇 進行 解決 1、簡介 1.1、動態規劃 動態規劃的性質:最優子結構;無後向性 動態規劃假定MDP所有信息已知,解決的是planning問題,不是RL問題 1.2、兩類問題 預測問題:給定策略,給出MDP/MRP和策略,計算策略值
強化學習之猜猜我是誰--- Deep Q-Network ^_^
導致 line d+ callbacks ima new div pan dense Deep Q-Network和Q-Learning怎麽長得這麽像,難道它們有關系? 沒錯,Deep Q-Network其實是Q-Learning融合了神經網絡的一種方法 這次我們以打飛機的
強化學習初步學習
image eva gin ive span auto isp block pla Iterative Policy Evaluation How to Improve a Policy
AI+遊戲:高效利用樣本的強化學習 | 騰訊AI Lab學術論壇演講
騰訊 AI 人工智能 3月15日,騰訊AI Lab第二屆學術論壇在深圳舉行,聚焦人工智能在醫療、遊戲、多媒體內容、人機交互等四大領域的跨界研究與應用。全球30位頂級AI專家出席,對多項前沿研究成果進行了深入探討與交流。騰訊AI Lab還宣布了2018三大核心戰略,以及同頂級研究與出版機構自然科研的
強化學習步驟
學習 otl 學習步驟 ID spm force silver mach page 1.Python基礎(莫煩) 2.數據分析的視頻:Numpy,Matplotlib, Pandas(已發鏈接) 3.強化學習基礎(莫煩) B站 4.強化學習理論課(silver) 5.Q
強化學習_Q-learning 算法的簡明教程
化學 learning 9.png nbsp AR mage ear bubuko learn 強化學習_Q-learning 算法的簡明教程