
python爬蟲之git的使用
1、初始化文件夾為版本控制文件夾,首先建立一個文件夾,進入這個文件夾以後輸入git init初始化這個文件夾。
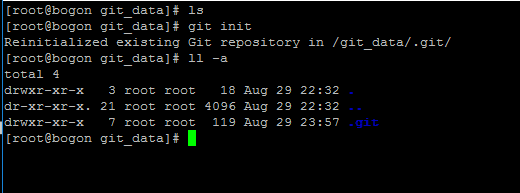
2、Git幾種位置概念
1、本地代碼:本地更改完代碼以後,雖然是存放在git的文件夾裏面,但是沒有添加到待提交列表裏面。
2、待提交列表:執行完git add 文件名,但是未執行git commit -m ‘說明’命令的狀態。
3、本地倉庫:git會在本地建立一個本地的倉庫,執行完git commit以後會提交到本地倉庫裏面。
4、遠程倉庫:例如Github、coding.net之類的遠程倉庫。
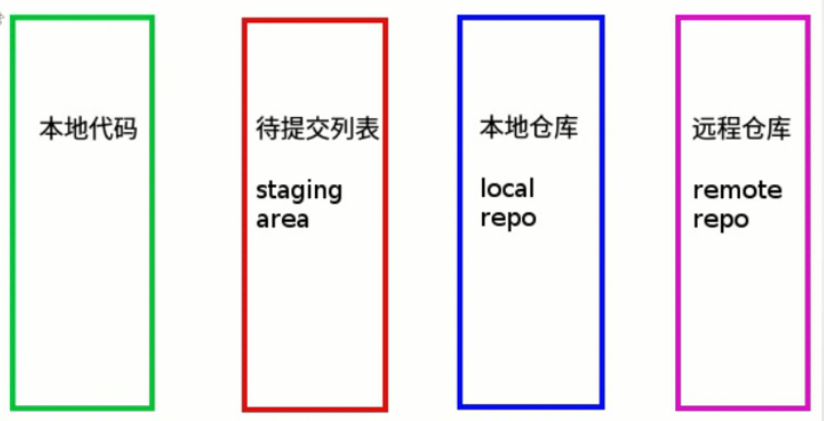
1、本地代碼狀態:

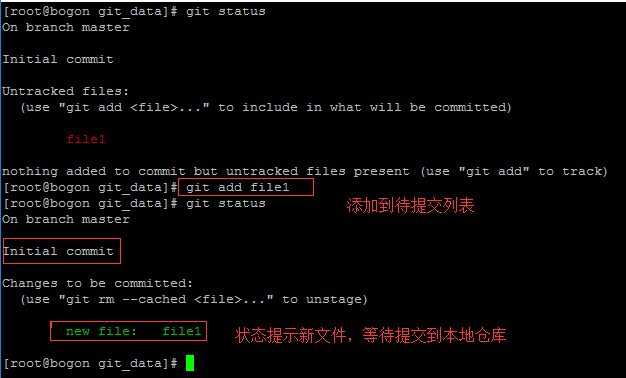
2、待提交列表:
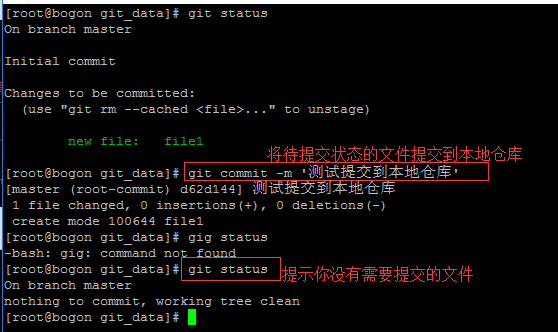
3、本地倉庫
python爬蟲之git的使用
相關推薦
python爬蟲之git的使用
mage .cn 沒有 倉庫 本地倉庫 odin src python爬蟲 建立 1、初始化文件夾為版本控制文件夾,首先建立一個文件夾,進入這個文件夾以後輸入git init初始化這個文件夾。 2、Git幾種位置概念 1、本地代碼:本地更改完代碼以後,雖然是存放在git的
python爬蟲之git的使用(coding.net的使用)
git push github上 版本 es2017 push 我們 執行命令 pytho 最好的 1、註冊coding.net賬號,然後登陸。 2、創建項目 套路和github都一樣。 1.1、我們在遠程倉庫上創建了一個倉庫,這樣的話,我們需要在本地隨便建立一
一個鹹魚的Python爬蟲之路(三):爬取網頁圖片
you os.path odin 路徑 生成 存在 parent lose exist 學完Requests庫與Beautifulsoup庫我們今天來實戰一波,爬取網頁圖片。依照現在所學只能爬取圖片在html頁面的而不能爬取由JavaScript生成的圖。所以我找了這個網站
[Python爬蟲] 之十五:Selenium +phantomjs根據微信公眾號抓取微信文章
頭部 drive lac 過程 標題 操作 函數 軟件測試 init 借助搜索微信搜索引擎進行抓取 抓取過程 1、首先在搜狗的微信搜索頁面測試一下,這樣能夠讓我們的思路更加清晰 在搜索引擎上使用微信公眾號英文名進行“搜公眾號&r
玩轉python爬蟲之URLError異常處理
bsp 無法識別 pac 使用 cin lai 網絡 處理方式 地址 這篇文章主要介紹了python爬蟲的URLError異常處理,詳細探尋一下URL\HTTP異常處理的相關內容,通過一些具體的實例來分析一下,非常的簡單,但是卻很實用,感興趣的小夥伴們可以參考一下 本節
python爬蟲之正則表達式
ner cde 輸入 set 神奇 tro 轉義 規則 error 一、簡介 正則表達式,又稱正規表示式、正規表示法、正規表達式、規則表達式、常規表示法(英語:Regular Expression,在代碼中常簡寫為regex、regexp或RE),計算機科學的一個概念。
[Python爬蟲] 之十九:Selenium +phantomjs 利用 pyquery抓取超級TV網數據
images 判斷 nco dex onf etc lac lin 利用 一、介紹 本例子用Selenium +phantomjs爬取超級TV(http://www.chaojitv.com/news/index.html)的資訊信息,輸入給定關鍵字抓取
Python爬蟲之爬取煎蛋網妹子圖
創建目錄 req add 註意 not 相同 esp mpi python3 這篇文章通過簡單的Python爬蟲(未使用框架,僅供娛樂)獲取並下載煎蛋網妹子圖指定頁面或全部圖片,並將圖片下載到磁盤。 首先導入模塊:urllib.request、re、os import
python爬蟲之requests模塊
.post 過大 form表單提交 www xxxxxx psd method date .com 一. 登錄事例 a. 查找汽車之家新聞 標題 鏈接 圖片寫入本地 import requests from bs4 import BeautifulSoup import
Python爬蟲之利用正則表達式爬取內涵吧
file res start cnblogs all save nts quest ide 首先,我們來看一下,爬蟲前基本的知識點概括 一. match()方法: 這個方法會從字符串的開頭去匹配(也可以指定開始的位置),如果在開始沒有找到,立即返回None,匹配到一個結果
Python爬蟲之利用BeautifulSoup爬取豆瓣小說(三)——將小說信息寫入文件
設置 one 行為 blog 應該 += html uil rate 1 #-*-coding:utf-8-*- 2 import urllib2 3 from bs4 import BeautifulSoup 4 5 class dbxs: 6 7
python爬蟲之scrapy的pipeline的使用
python爬蟲 pre ram .py pid cati port 目錄 自動創建 scrapy的pipeline是一個非常重要的模塊,主要作用是將return的items寫入到數據庫、文件等持久化模塊,下面我們就簡單的了解一下pipelines的用法。 案例一:
python爬蟲之解析網頁的工具pyquery
div blog import 很多 aof pyquery from text lec 主要是對http://www.cnblogs.com/zhaof/p/6935473.html這篇博客所做的筆記有疑惑可以去看這篇文章from pyquery import PyQue
python爬蟲之scrapy文件下載
files 下載 item toc mat spider color pid 一點 我們在寫普通腳本的時候,從一個網站拿到一個文件的下載url,然後下載,直接將數據寫入文件或者保存下來,但是這個需要我們自己一點一點的寫出來,而且反復利用率並不高,為了不重復造輪子,scra
Python 爬蟲之第一次接觸
with close def fin port 更新 top sta .get 爬豆瓣網電影TOP250名單 ------- 代碼未寫完,等待更新 import requests from requests.exceptions import RequestExcep
python爬蟲之scrapy模擬登錄
這不 eight 搜索 頁面 response dom cookie值 知乎 blog 背景: 初來乍到的pythoner,剛開始的時候覺得所有的網站無非就是分析HTML、json數據,但是忽略了很多的一個問題,有很多的網站為了反爬蟲,除了需要高可用代理IP地址池外,還
python爬蟲之線程池和進程池
偏見 通信 內存空間 正常 io操作 爬取 網站 總結 性能 一、需求 最近準備爬取某電商網站的數據,先不考慮代理、分布式,先說效率問題(當然你要是請求的太快就會被封掉,親測,400個請求過去,服務器直接拒絕連接,心碎),步入正題。一般情況下小白的我們第一個想到的是fo
python爬蟲之Splash使用初體驗
ans 服務器 wid ajax tor 為什麽 安裝 異步 理由 Splash是什麽: Splash是一個Javascript渲染服務。它是一個實現了HTTP API的輕量級瀏覽器,Splash是用Python實現的,同時使用Twisted和QT。Twisted(QT
python爬蟲之真實世界中的網頁解析
爬蟲 兩種 del http協議 head 常用 nbsp 是我 返回 Request和Response Request是我們平常瀏覽網頁,向網站所在的服務器發起請求,而服務器收到請求後,返回給我們的回應就是Response,這種行為就稱為HTTP協議,也就是客戶端(瀏覽器
python爬蟲之pyquery學習
功能 刪除指定元素 pre spa image demo round imp 情況 相關內容: pyquery的介紹 pyquery的使用 安裝模塊 導入模塊 解析對象初始化 css選擇器 在選定元素之後的元素再選取 元素的文本、屬性等內容的獲取 pyquery執