
XML的四種解析方式
阿新 • • 發佈:2017-09-02
ron 合並 parent 問題 private entity cti fin system
基礎方法: DOM、SAX
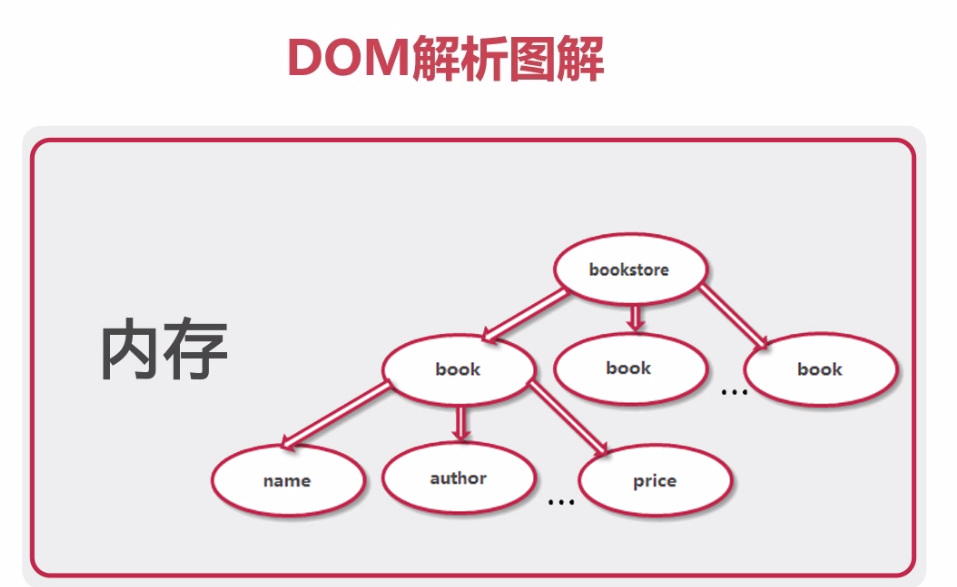
DOM:與平臺無關的官方解析方式
SAX:基於事件驅動的解析方式

擴展方法:JDOM、DOM4J(在基礎的方法上擴展的,只有Java能夠使用的解析方式)
DOM: 一次性解析完畢!
import java.io.FileOutputStream; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.transform.OutputKeys; import javax.xml.transform.Transformer;import javax.xml.transform.TransformerFactory; import javax.xml.transform.dom.DOMSource; import javax.xml.transform.stream.StreamResult; import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.Node; import org.w3c.dom.NodeList; /** * 第六章 簡答題1-4 * @author Xuas * */ public classDemo_DOM { Document doc = null; /** * 加載DOM樹 */ public void loadDocument() throws Exception { //得到DOM解析器的工廠實例 DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); //從DOM工廠獲得DOM解析器 DocumentBuilder db = dbf.newDocumentBuilder(); //解析XML文檔,得到一個Document對象,即DOM樹doc = db.parse("src/com/chapter6/zy/學生信息.xml"); } /** * 顯示信息 */ public void showInfo(){ //獲取所有student節點集合 NodeList studentList = doc.getElementsByTagName("student"); System.out.println("*******一共有"+studentList.getLength()+"個學生*******"); //遍歷每一個student節點 for(int i=0;i<studentList.getLength();i++){ System.out.println("第"+(i+1)+"名學生信息:"); /** * 不確定屬性個數時: */ /*//獲取第i個student節點 Node studentNode = studentList.item(i); //獲取student節點所有屬性集合 NamedNodeMap attrs = studentNode.getAttributes(); System.out.println("第"+(i+1)+"個學生共有"+attrs.getLength()+"個屬性"); //遍歷student的屬性 for(int j=0;j<attrs.getLength();j++){ //通過item(index)獲取student節點的某一個屬性 Node attr = attrs.item(j); //獲取屬性名 System.out.print("屬性名:"+attr.getNodeName()); //獲取屬性值 System.out.println("==>屬性值:"+attr.getNodeValue()); }*/ /** * 確定student節點有且只有一個id屬性: */ //將student節點進行強制類型轉換,轉換成Element類型 Element student = (Element)studentList.item(i); //通過getAttribute("id")方法獲取屬性值 String attrValue = student.getAttribute("id"); System.out.println("id屬性:"+attrValue); //解析student節點的子節點 NodeList stuChildNodes = student.getChildNodes(); //遍歷stuChildNodes獲取每個節點名和節點值 System.out.println("第"+(i+1)+"個學生共有"+stuChildNodes.getLength()+"個子節點"); for(int k=0;k<stuChildNodes.getLength();k++){ //區分出text類型的node以及element類型的node if(stuChildNodes.item(k).getNodeType() == Node.ELEMENT_NODE){ //獲取element類型節點的節點名 System.out.print(stuChildNodes.item(k).getNodeName()); //獲取element類型節點的節點值(兩種方式) /** * */ //System.out.println(":"+stuChildNodes.item(k).getFirstChild().getNodeValue()); System.out.println(":"+stuChildNodes.item(k).getTextContent()); } } System.out.println("***************************************************"); } } /** * 刪除ID為1的成績 */ public void delete() throws Exception{ NodeList stuList = doc.getElementsByTagName("student"); //找到刪除的節點 for(int i=0;i<stuList.getLength();i++){ Element stuEle = (Element)stuList.item(i); //找到ID=1的student節點的成績子節點 if(stuEle.getAttribute("id").equals("1")){ NodeList childNodes = stuEle.getChildNodes(); for(int j=0;j<childNodes.getLength();j++){ if(childNodes.item(j).getNodeName().equals("score")){ childNodes.item(j).getParentNode().removeChild(childNodes.item(j)); } } } } //保存XML文件 TransformerFactory transformerFactory = TransformerFactory.newInstance(); Transformer transformer = transformerFactory.newTransformer(); DOMSource domSource = new DOMSource(doc); // 設置編碼格式 transformer.setOutputProperty(OutputKeys.ENCODING, "gb2312"); StreamResult result = new StreamResult(new FileOutputStream("src/com/chapter6/zy/學生信息(刪除ID為1).xml")); // 把DOM樹轉換為XML文件 transformer.transform(domSource, result); } /** * 修改ID為2的成績為60 */ public void modify() throws Exception{ NodeList stuList = doc.getElementsByTagName("student"); //找到要修改的student節點 for(int i=0;i<stuList.getLength();i++){ Element stuEle = (Element)stuList.item(i); //找到ID為2的student節點 if(stuEle.getAttribute("id").equals("2")){ //遍歷ID為2的student節點的子節點找到score節點 NodeList childNodes = stuEle.getChildNodes(); for(int j=0;j<childNodes.getLength();j++){ if(childNodes.item(j).getNodeName().equals("score")){ childNodes.item(j).setTextContent("60"); } } } } //保存XML文件 TransformerFactory transformerFactory = TransformerFactory.newInstance(); Transformer transformer = transformerFactory.newTransformer(); DOMSource domSource = new DOMSource(doc); // 設置編碼格式 transformer.setOutputProperty(OutputKeys.ENCODING, "gb2312"); StreamResult result = new StreamResult(new FileOutputStream("src/com/chapter6/zy/學生信息(修改ID為2成績為60).xml")); // 把DOM樹轉換為XML文件 transformer.transform(domSource, result); } /** * 添加一個學生信息(ID為3) */ public void add() throws Exception { //創建student節點 Element stuEle = doc.createElement("student"); stuEle.setAttribute("id", "3"); //創建name節點 Element nameEle = doc.createElement("name"); nameEle.setTextContent("王五"); //創建course節點 Element courseEle = doc.createElement("course"); courseEle.setTextContent("英語"); //創建score節點 Element scoreEle = doc.createElement("score"); scoreEle.setTextContent("77"); //添加父子關系 stuEle.appendChild(nameEle); stuEle.appendChild(courseEle); stuEle.appendChild(scoreEle); Element scoresEle = (Element)doc.getElementsByTagName("scores").item(0); scoresEle.appendChild(stuEle); //保存XML文件 TransformerFactory transformerFactory = TransformerFactory.newInstance(); Transformer transformer = transformerFactory.newTransformer(); DOMSource domSource = new DOMSource(doc); //設置編碼格式 transformer.setOutputProperty(OutputKeys.ENCODING, "gb2312"); StreamResult result = new StreamResult(new FileOutputStream("src/com/chapter6/zy/學生信息(添加ID為3學生).xml")); //把DOM樹轉換為XML文件 transformer.transform(domSource, result); } /** * 測試方法 */ public static void main(String[] args) throws Exception{ Demo_DOM demo = new Demo_DOM(); demo.loadDocument(); //demo.delete(); demo.modify(); demo.add(); demo.showInfo(); } }
SAX:逐步解析(一個標簽一個標簽的解析!)
import java.util.ArrayList; import org.xml.sax.Attributes; import org.xml.sax.SAXException; import org.xml.sax.helpers.DefaultHandler; import com.SAX方式解析XML.entity.Book; public class SAXParserHandler extends DefaultHandler { String value = null; Book book = null; private ArrayList<Book> bookList = new ArrayList<Book>(); public ArrayList<Book> getBookList() { return bookList; } int bookIndex = 0; /** * 用來遍歷xml文件的開始標簽 */ public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException { //調用DefaultHandler類的startElement方法 super.startElement(uri, localName, qName, attributes); //開始解析book元素的屬性 if(qName.equals("book")){ //創建一個Book對象 book = new Book(); bookIndex++; //已知book元素下屬性名稱,根據屬性名獲取屬性值 System.out.println("***********開始遍歷第"+bookIndex+"本書的內容***********"); /*String value = attributes.getValue("id"); System.out.println("book的屬性值是:"+value);*/ int num = attributes.getLength(); for(int i=0;i<num;i++){ System.out.print("book元素的第"+(i+1)+"屬性名是:"+attributes.getQName(i)); System.out.println("==>屬性值是:"+attributes.getValue(i)); if(attributes.getQName(i).equals("id")){ book.setId(attributes.getValue(i)); } } }else if(!qName.equals("book") && !qName.equals("bookstore")){ System.out.print("節點名是:"+qName+"==>"); } } /** * 用來遍歷xml文件的結束標簽 */ public void endElement(String uri, String localName, String qName) throws SAXException { //調用DefaultHandler類的endElement方法 super.endElement(uri, localName, qName); //判斷是否針對一本書已經遍歷結束 if(qName.equals("book")){ bookList.add(book); book = null; System.out.println("***********結束遍歷第"+bookIndex+"本書的內容***********"); }else if(qName.equals("name")){ book.setName(value); }else if(qName.equals("author")){ book.setAuthor(value); }else if(qName.equals("year")){ book.setYear(value); }else if(qName.equals("price")){ book.setPrice(value); }else if(qName.equals("language")){ book.setLanguage(value); } } /** * 用來標識解析開始 */ public void startDocument() throws SAXException { super.startDocument(); System.out.println("SAX解析開始"); } /** * 用來標識解析結束 */ public void endDocument() throws SAXException { super.endDocument(); System.out.println("SAX解析結束"); } /** * */ public void characters(char[] ch, int start, int length) throws SAXException { super.characters(ch, start, length); value = new String(ch, start, length); if(!value.trim().equals("")){ System.out.println("節點值是:"+value); } } }
import javax.xml.parsers.SAXParser; import javax.xml.parsers.SAXParserFactory; import com.SAX方式解析XML.entity.Book; import com.SAX方式解析XML.handler.SAXParserHandler; public class Demo { public static void main(String[] args) throws Exception{ //獲取一個SAXParserFactory的實例 SAXParserFactory factory = SAXParserFactory.newInstance(); //通過factory獲取SAXParser實例 SAXParser parser = factory.newSAXParser(); //創建SAXParserHandler對象 SAXParserHandler handler = new SAXParserHandler(); parser.parse("books.xml", handler); System.out.println("共有"+handler.getBookList().size()+"本書!"); for (Book book : handler.getBookList()) { System.out.println(book.getId()); System.out.println(book.getName()); System.out.println(book.getAuthor()); System.out.println(book.getYear()); System.out.println(book.getPrice()); System.out.println(book.getLanguage()); System.out.println("--------------finish---------------"); } } }
選擇DOM還是SAX??
DOM---優點:
1.形成了樹結構,直觀好理解,代碼更易編寫!
2.解析過程中樹結構保留在內存中,方便修改!
DOM---缺點:
當xml文件較大時,對內存耗費比較大,容易影響解析性能並造成內存溢出!(內存裝不下DOM樹了!)
SAX---優點:
1.采用事件驅動模式,對內存耗費比較小!
2.適用於只需要處理xml中數據的情況!
SAX---優點:
1.不易編碼!
2.很難同時訪問同一個xml中的多處不同數據!
JDOM與DOM、DOM4J
JDOM:
1.僅使用具體類而不使用接口!
2.API大量使用了Collections類!
import java.io.FileInputStream; import java.io.InputStream; import java.io.InputStreamReader; import java.util.ArrayList; import java.util.List; import org.jdom2.Attribute; import org.jdom2.Document; import org.jdom2.Element; import org.jdom2.input.SAXBuilder; import com.JDOM方式解析XML.entity.Book; public class Demo { private static ArrayList<Book> booksList = new ArrayList<Book>(); public static void main(String[] args) throws Exception{ // 進行對books.xml文件的解析 // 1.創建一個SAXBuilder的對象 SAXBuilder saxBuilder = new SAXBuilder(); // 2.創建一個輸入流,將xml加載到輸入流裏來 InputStream in = new FileInputStream("src/res/books.xml"); //處理解析過程中的亂碼問題 InputStreamReader isr = new InputStreamReader(in, "UTF-8"); // 3.通過saxBuilder的build()方法,將輸入流加載到saxBilder中 Document doc = saxBuilder.build(in); // 4.通過document對象獲取xml文件的根節點 Element rootEle = doc.getRootElement(); // 5.獲取根節點下的子節點的List集合 List<Element> bookList = rootEle.getChildren(); // 繼續進行解析 for (Element book : bookList) { Book bookEntity = new Book(); System.out.println("開始解析第"+(bookList.indexOf(book)+1)+"本書"); // 解析book的屬性集合 List<Attribute> attrList = book.getAttributes(); // 知道節點下屬性名稱時,獲取節點值 //book.getAttributeValue("id"); // 遍歷attrList(針對不清楚book節點下屬性的名字及數量) for (Attribute attr : attrList) { System.out.println("屬性名:"+attr.getName()+"==>屬性值:"+attr.getValue()); if(attr.getName().equals("id")){ bookEntity.setId(attr.getValue()); } } // 對book節點的子節點的節點名 節點值進行遍歷 List<Element> bookChilds = book.getChildren(); for (Element child : bookChilds) { System.out.println("節點名:"+child.getName()+"==>節點值:"+child.getValue()); if(child.getName().equals("name")){ bookEntity.setName(child.getValue()); }else if(child.getName().equals("author")){ bookEntity.setAuthor(child.getValue()); }else if(child.getName().equals("year")){ bookEntity.setYear(child.getValue()); }else if(child.getName().equals("price")){ bookEntity.setPrice(child.getValue()); }else if(child.getName().equals("language")){ bookEntity.setLanguage(child.getValue()); } } System.out.println("結束解析第"+(bookList.indexOf(book)+1)+"本書"); booksList.add(bookEntity); bookEntity = null; /* * 測試是否存儲到Book對象中 */ //System.out.println(booksList.size()); //System.out.println(booksList.get(0).getName()); } } }
DOM4J:(在性能上比JDOM高!)
1.JDOM的一種智能分支,它合並了許多超出基本XML文檔表示的功能!
2.DOM4J使用接口和抽象基本類方法,是一個優秀的Java XML API!
3.具有性能優異、靈活性好、功能強大和極端易使用的特點!
4.是一個開放源代碼的軟件!
import java.io.File; import java.util.Iterator; import java.util.List; import org.dom4j.Attribute; import org.dom4j.Document; import org.dom4j.Element; import org.dom4j.io.SAXReader; public class Demo { public static void main(String[] args) throws Exception { // 解析books.xml文件 // 創建SAXReader的對象reader SAXReader reader = new SAXReader(); // 通過reader對象的read()方法加載xml文件,獲取document對象 Document doc = reader.read(new File("books.xml")); // 通過document對象獲取根節點bookstore Element bookStore = doc.getRootElement(); // 通過element對象的elementIterator()方法獲取叠代器 Iterator bookStoreIt = bookStore.elementIterator(); // 遍歷叠代器,獲取根節點中的信息(book) while(bookStoreIt.hasNext()){ System.out.println("=========開始遍歷某一本書========="); Element book = (Element)bookStoreIt.next(); List<Attribute> attrs = book.attributes(); for (Attribute attr : attrs) { System.out.println("屬性名:"+attr.getName()+"==>屬性值:"+attr.getValue()); } Iterator bookIt = book.elementIterator(); while(bookIt.hasNext()){ Element bookChild = (Element)bookIt.next(); System.out.println("節點名:"+bookChild.getName()+"==>節點值:"+bookChild.getStringValue()); } System.out.println("=========結束遍歷某一本書========="); } } }
XML的四種解析方式