
XML幾種解析方式以及其試用場景
XML解析方式
XML(Extensible Markup Language)即可擴充套件標記語言,它與HTML一樣,都是SGML(Standard Generalized Markup Language,標準通用標記語言)。Xml是Internet環境中跨平臺的,依賴於內容的技術,是當前處理結構化文件資訊的有力工具。擴充套件標記語言XML是一種簡單的資料儲存語言,使用一系列簡單的標記描述資料,而這些標記可以用方便的方式建立。XML已經成為一種通用的資料交換格式,它的平臺無關性,語言無關性,系統無關性,給資料整合與互動帶來了極大的方便。XML的解析方式基本上分為三類:第一類是基於XML文件樹結構的解析,例如DOM(Document Object Model);第二類是基於流式的解析,例如SAX(Simple API for XML)、StAX(Stream API for XML)和XPP(XML Pull Parser);第三類是基於非提取式的解析,例如VTD-XML(Virtual Token Description for XML)。
1 DOM
DOM是用與平臺和語言無關的方式表示諸如XML和HTML文件的W3C(全球資訊網聯盟) 官方推薦標準。它定義了所有文件元素的物件和屬性,以及訪問它們的API介面。W3C DOM被分為3個不同的部分,核心DOM、XML DOM和HTML DOM。核心DOM用於任何結構化文件的標準模型;XML DOM用於XML的標準物件模型和標準程式設計介面;HTML DOM用於HTML文件的標準模型。
DOM是以層次結構組織的節點或資訊片斷的集合。這個層次結構允許開發人員在樹中尋找特定資訊。分析該結構通常需要載入整個文件和構造層次結構,然後才能做任何工作。由於它是基於資訊層次的,因而DOM被認為是基於樹或基於物件的。
優點:易用性強,由於樹在記憶體中是持久的,因此可以修改它以便應用程式能對資料和結構作出更改,它還可以在任何時候在樹中上下導航。
缺點:效率低,解析速度慢,記憶體佔用量過高,對於大檔案來說幾乎不可能使用。另外效率低還表現在大量的消耗時間,因為使用DOM進行解析時,將為文件的每個element、attribute、processing-instruction和comment都建立一個物件,這樣在DOM機制中所運用的大量物件的建立和銷燬無疑會影響其效率。
2 SAX
SAX是基於事件驅動的推式解析方式。它並不是W3C的官方標準,而是業界事實上的標準。SAX解析的基本原理是把元素開始、元素結束、文字、文件的開始或結束等當成一個事件,當解析器遇到這些事件時,就傳送請求給事件處理介面進行處理。事件處理介面的具體實現是程式設計師編寫的事件處理響應程式碼。SAX解析的基本原理如下圖:
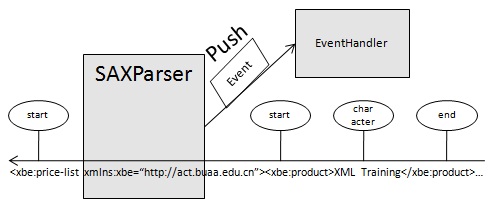
SAX處理的優點非常類似於流媒體的優點。分析能夠立即開始,而不是等待所有的資料被處理。由於應用程式只是在讀取資料時檢查資料,因此不需要將資料儲存在記憶體中。這對於大型文件來說是個巨大的優點。事實上,應用程式甚至不必解析整個文件;它可以在某個條件得到滿足時停止解析。一般來說,SAX還比它的替代者DOM快許多。
選擇DOM還是選擇SAX? 對於需要自己編寫程式碼來處理XML文件的開發人員來說, 選擇DOM還是SAX解析模型是一個非常重要的設計決策。DOM採用建立樹形結構的方式訪問XML文件,而SAX採用的事件模型。
DOM解析器把XML文件轉化為一個包含其內容的樹,並可以對樹進行遍歷。用DOM解析模型的優點是程式設計容易,開發人員只需要呼叫建樹的指令,然後利用navigation APIs訪問所需的樹節點來完成任務。可以很容易的新增和修改樹中的元素。然而由於使用DOM解析器的時候需要處理整個XML文件,所以對效能和記憶體的要求比較高,尤其是遇到很大的XML檔案的時候。由於它的遍歷能力,DOM解析器常用於XML文件需要頻繁的改變的服務中。
SAX解析器採用了基於事件的模型,它在解析XML文件的時候可以觸發一系列的事件,當發現給定的tag的時候,它可以啟用一個回撥方法,告訴該方法制定的標籤已經找到。SAX對記憶體的要求通常會比較低,因為它讓開發人員自己來決定所要處理的tag.特別是當開發人員只需要處理文件中所包含的部分資料時,SAX這種擴充套件能力得到了更好的體現。但用SAX解析器的時候編碼工作會比較困難,而且很難同時訪問同一個文件中的多處不同資料。
優點:所有的SAX處理都在一次遍歷中完成的;因此,在解析同等大小的文件時SAX通常會相比DOM提供更好的效能(因為DOM必須遍歷樹結構)。此外,與DOM是比,因為在給定的時間之內只需要XML文件的一部分裝入記憶體,所以SAX通常在處理更大檔案時記憶體的利用效率也來得更高(DOM在開始解析文件之前必須把全部XML文件裝入記憶體)。
缺點: SAX應用程式一般都比較長,程式中充斥著大量的if/else結構用來確定處理特定元素時所採用的運動。同樣的,處理多個XML元素之間散佈的資料結構也很成問題,因為解析事件之間必須儲存中間資料。SAX應用程式的事件處理結構一般意味著SAX應用程式是針對特定檔案結構定製構建的,而DOM應用程式則更具一般性。
3 StAX
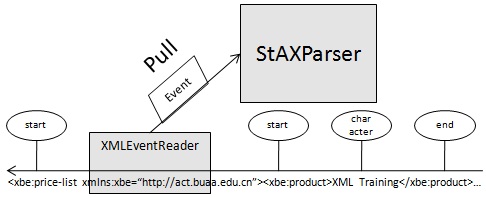
StAX是基於事件流的拉式是解析方式,與SAX不同之處在於 StAX 允許應用程式程式碼把這些事件逐個拉出來,而不用提供在解析器方便時從解析器中接收事件的處理程式。
StAX 實際上包括兩套處理 XML 的 API,分別提供了不同程度的抽象。基於指標的 API 允許應用程式把 XML 作為一個標記(或事件)流來處理;應用程式可以檢查解析器的狀態,獲得解析的上一個標記的資訊,然後再處理下一個標記,依此類推。這是一種低層 API,儘管效率高,但是沒有提供底層 XML 結構的抽象。較為高階的基於迭代器的 API 允許應用程式把 XML 作為一系列事件物件來處理,每個物件和應用程式交換 XML 結構的一部分。應用程式只需要確定解析事件的型別,將其轉換成對應的具體型別,然後利用其方法獲得屬於該事件的資訊。
StAX 所採用的基於拉的方法和其他方法相比有一些突出的優點。首先,不管使用哪種 API 風格,都是應用程式呼叫讀取器(解析器)而不是相反。通過保留解析過程的控制權,可以簡化呼叫程式碼來準確地處理它預期的內容。或者發生意外時停止解析。此外,由於該方法不基於處理程式回撥,應用程式不需要像使用 SAX 那樣模擬解析器的狀態。
StAX 仍然保留了 SAX 相對於 DOM 的優點。通過把重心從結果物件模型轉移到解析流本身,從理論上說應用程式能夠處理無限的 XML流,因為事件固有的臨時性,不會在記憶體中累積起來。對於那些使用 XML 作為訊息傳遞協議而非表示文件內容的那些應用程式尤其重要,比如 Web 服務或即時訊息應用程式。比方說,如果只是將其轉換成特定於應用程式的物件模型然後就將其丟棄,那麼為 Web 服務路由器 servlet 提供一個 DOM 就沒有多少用處。使用 StAX 直接轉化成應用程式模型效率更高。對於 Extensible Messaging and Presence Protocol(XMPP)客戶機,根本不能使用 DOM,因為 XMPP 客戶機/伺服器流是隨著使用者輸入的訊息實時生成。等待流的關閉標籤(以便最終建立 DOM)就意味著等待整個會話結束。通過把 XML 作為一系列的事件來處理,應用程式能夠以最合適的方式響應每個事件(比如顯示收到的即時訊息等等)。
由於其雙向性,StAX 也支援鏈式處理,特別是在事件層上。接收事件(無論什麼來源)的能力被封裝在XMLEventConsumer(XMLEventWriter 的擴充套件)介面中。因此,可以模組化地編寫應用程式從 XMLEventReader(也是一個普通的迭代器,可以按迭代器處理)讀取和處理 XML 事件、然後傳遞給事件消費者(如果需要可以進一步擴充套件處理鏈)。在第 2 部分將看到,也可使用應用程式提供的篩選器(實現了 EventFilter 介面的類)來定製 XMLEventReader 或者使用 EventReaderDelegate 修飾已有的XMLEventReader。
總而言之,和 DOM 以及 SAX 相比,StAX 使應用程式更貼近底層的 XML。使用 StAX,應用程式不僅可以建立需要的物件模型(而不需要處理標準 DOM),而且可以隨時這樣做,而不必等到解析器回撥。
4 XPP
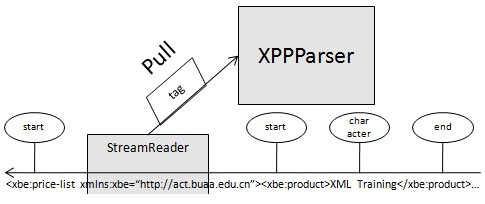
XPP是更底層的StAX解析方式, 只能適當支援 XML 文件的子集並且不提供驗證的任何支援。它同樣具有尺寸小的優勢。這種優勢再與拉回解析器方法結合,使它成為該比較中的良好替換項。
XPP 幾乎獨佔地使用介面,但是它僅使用所有類中的一小部分。XPP 避免使用 API 中的 Collections 類。總的來說,它是本文中最簡單的文件模型 API。
將 XPP 限制成 XML 文件子集的侷限性是它不支援文件中的實體、註釋或處理指示資訊。XPP 建立僅包含元素、屬性(包括“名稱空間”)和內容文字的文件結構。這對於某些型別的應用程式來說是一種非常嚴格的限制。
XPP 中的拉回解析器支援(本文中稱為 XPP 拉回)通過將解析實際上推遲到訪問文件的一個元件時才進行,然後按照構造那個元件的需要對文件進行解析。該技術想實現允許非常快速的文件顯示或分類應用,尤其在需要轉發或除去(而不是對文件進行完全解析和處理)文件時。該方法的使用是可選的,如果以非拉回型方式使用 XPP,它對整個文件進行解析並且同時地構建完整的表示。
XPP 使用依據文字文件構建文件表示的整合語法解析器,並且除了通過文字方式外,它不提供從 DOM(或 SAX2)轉換或轉換成SAX2(或 DOM)事件流的任何方式。
5 VTD
當我們選擇處理 XML 檔案的時候,正如上面介紹的那樣,大致上有DOM、SAX、StAX和XPP四種選擇。雖然它們都各有其利弊,但都不是特別好的解決方案,不難看出,DOM 與 SAX(StAX、XPP)是正好相反的兩個極端,它們在解析效率上都存在一定的效能瓶頸,究其原因,在於它們都是基於提取解(extractive parsing)模式。所謂的提取解析就是說在解析 XML 時,解析器會提取一部分原檔案,一般來說是一個字串,然後在記憶體中進行解析構建,輸出自然就是一個或一些物件了。以DOM 為例,DOM 會將每一個 element,attribute, processing-instruction, comment 等等都解析成物件並給與結構,這就是所謂的提取解析。提取解析將會帶來三種RoundTrip,引起效能瓶頸:
1. 物件的建立與回收。提取解析模式註定瞭解析器都需要大量的建立或銷燬物件,引起效率問題。
2. 編碼與解碼。無論是何種解析方法都需要能夠處理 XML 的編碼,也就是說,在讀取的時候解碼,在寫入的時候編碼。
3. Tokenize和Untokenize。無論是何種解析方法,都會將其中的Token輸出為字串以提供給應用程式,應用程式修改完畢,又將其字元untokenize成原始資料型別。
因此,在 DOM 或者SAX 、StAX和XPP的物件模型中,當每一次需要做改動時,我們要做的就是將物件的資訊再解析回 XML 的字串,注意這個解析是個完整的解析,也就是說,原檔案並沒有被利用,而是直接將物件模型重新完整解析成 XML 字串。換句話講,它們並不支援增量更新,而在這過程中,有很多不是應用程式所關心的,因而增加了不必要的效能開銷。
總而言之, DOM、SAX、StAX和XPP的效率問題主要出在它的提取解析模式上, VTD-XML[25](Virtual Token Descriptor虛擬令牌描述符)便是對以上問題的思考後給出的答案,它是一個非提取的 XML解析器,由於它出色的機制,很好的解決了上面所提出的各種問題,並且還帶來了非提取的其他好處,像快速的解析與遍歷、對 XPath 的支援、增量更新等等。一條VTD記錄的位元層格式如下所示:
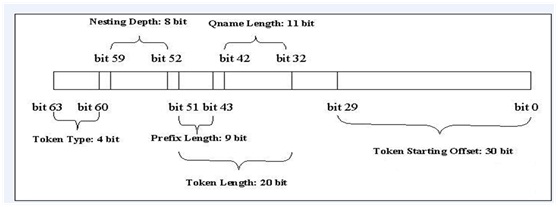
各欄位的描述如下:
·開始偏移量:30bits(b29~b0)最大值是 2^30-1 = 1G-1;
·長度:20bits(b51~b32)最大值是 2^20-1 = 1M-1;
其中字首長度:9bits(b51~b43)最大值是 511;
序列名長度:11bits(b42~b32)最大值是 1023;
·深度:8bits(b59~b52)最大值是 255;
·令牌型別:4bits(b63、b60);
·保留:2bits(b31、b30)。
由此可見VTD 是 64bits 固定長度的,這樣做的目的就是為了提高效能,因為長度固定,在讀取,查詢等操作的時候格外的高效,也就是可以用陣列這種高效的結構來組織 VTD,這大大減少了因為大量使用物件而產生的效能問題。