
Caffe入門隨筆
Caffe入門隨筆
分享一下自己入門機器學習的一些資料:
(1)課程,最推薦Coursera上的Andrew NG的Machine Learning,最好註冊課程,然後跟下來。
其次是華盛頓大學的Machine Learning系列課程,一共有6門,包括畢業設計
(2)書籍: 機器學習(周誌華西瓜書)、機器學習實戰、統計學習方法(李航)、集體智慧編程、數學之美(吳軍)
(3)微博
@余凱_西二旗民工;@老師木;@梁斌penny;@張棟_機器學習;@鄧侃;@大數據皮東;@djvu9;@陳天奇怪
(4)知乎
@賈揚清;@Naiyan Wang; @李文哲;@陳然
熱門回答 機器學習該怎麽入門?<https://www.zhihu.com/question/20691338>
安裝和配置caffe
環境:臺式機 + 無GPU + Ubuntu14.04
純CPU簡易安裝過程:
(1) 下載相關依賴包(在ubuntu下都由apt-get大法搞定)
sudo apt-get install libatlas-base-dev sudo apt-get install libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-dev libboost-all-dev libhdf5-serial-dev sudo apt-get install libgflags-dev libgoogle-glog-dev liblmdb-dev protobuf-compiler
(2) github上下載最新的caffe源碼
git clone https://github.com/BVLC/caffe.git cd caffe cp Makefile.config.example Makefile.config
(3) 修改Makefile.config,選擇CPU_ONLY選項,保存
(4) 測試
make all -j4 make test make runtest
安裝配置心得
純CPU版因為不涉及顯卡和Cuda安裝的問題,因此安裝過程中比較簡單。主要遇到的問題是相關依賴包的缺失問題。
整理了下用到的依賴包和作用:
(1) Protobuffer
谷歌開發的一種可以實現內存與非易失存儲介質(如硬盤)交換的協議接口。Caffe源碼中大量使用protobuffer作為權值和模型參數的載體。使用protobuffer可以跨語言(C++/java/python)傳遞相同的數據結構。
(2) Boost
C++準標準庫,功能強大,跨平臺,構造精巧,開源免費。在caffe中主要使用了Boost庫中的智能指針,其自帶引用計數功能,可避免共享指針時造成的內存泄漏和多次釋放。
(3) GFLAGS
主要起到命令行參數解析的作用,與protobuffer功能類似,只是參數輸入源不同。
(4) GLOG
谷歌開發的用於記錄應用程序日誌的實用庫,提供基於C++標準輸入輸出的流形式接口,記錄可以選擇的不同的日誌級別,將重要日誌和普通日誌分開。
(5) BLAS
基本線性代數庫。最常用的有Openblas, Atlas, Intel Mkl等,安裝相應的版本後,可以在caffe的config文件中配置
(6) HDF5
美國國家高級計算中心為了滿足各種領域研究需求而研制的一種能高效存儲和分發科學數據的新型數據格式。可以存儲不同類型的圖像和數碼數據文件,在不同的機器上傳輸。Caffe訓練模型可以保存為默認的protobuffer格式或者hdf5格式。
(7) Lmdb和leveldb
在caffe中主要的作用是數據庫管理,將形形色色的原始數據轉換為統一的key-value存儲,方便caffe的datalayer進行讀取。
Caffe Demo
http://blog.sina.com.cn/s/blog_5d36d8e00102uya1.html
參照薛開宇的博客,在caffe的example下跑一些demo
以caffe/example/cifar10目錄下的cifar數據集demo為例,我的安裝目錄是~/software/caffe
(1)獲取數據集和計算均值文件
cd ~/software/caffe/data/cifar10 ./get_cifar10.sh cd ~/software/caffe/examples/cifar10 ./create_cifar10.sh
運行之後,將會在cifar10目錄下會出現:
兩個文件夾
cifar10_train_lmdb/ cifar10_test_lmdb/
一個數據庫圖像均值二進制文件
mean.binaryproto
(2)訓練cifar10數據集
寫好參數設置的文件cifar10_quick_solver.prototxt和定義的文件cifar10_quick_train.prototxt和cifar10_quick_test.prototxt後運行 train_quick.sh即可
(3)觀察結果
當5000次叠代之後,正確率約為75%,模型的參數存儲在二進制protobuf格式在cifar10_quick_iter_5000,然後,這個模型就可以用來運行在新數據上了。
Caffe源碼閱讀
參考知乎上的一個問題,深度學習caffe的代碼怎麽讀
https://www.zhihu.com/question/27982282
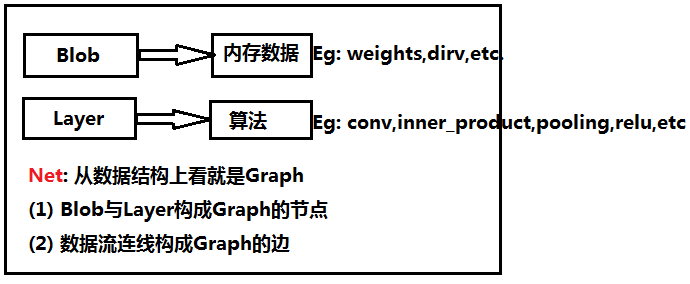
要讀懂caffe,首先要熟悉Blob,Layer,Net,Solver這幾個大類。這四個大類自下而上,環環相扣,貫穿了整個caffe的結構。
(1)Blob:
作為數據傳輸的媒介,無論是網絡權重參數,還是輸入數據,都是轉化為Blob數據結構來存儲
(2)Layer:
作為網絡的基礎單元,神經網絡中層與層間的數據節點、前後傳遞都在該數據結構中被實現,層類種類豐富,比如常用的卷積層、全連接層、pooling層等等,大大地增加了網絡的多樣性
(3)Net:
作為網絡的整體骨架,決定了網絡中的層次數目以及各個層的類別等信息
Blob,Layer和Net的關系可以用下圖來描述:
(4)Solver:
作為網絡的求解策略,涉及到求解優化問題的策略選擇以及參數確定方面,修改這個模塊的話一般都會是研究DL的優化求解的方向。
prototxt文件
在caffe中,要訓練一個網絡,至少要包含2個prototxt文件:
1. 一個是描述Net結構(“Blob+Layers+數據流”構成)的文件
2. 一個是描述訓練算法的Solver文件
例如,cifar10中的描述Solver的prototxt

1 # reduce the learning rate after 8 epochs (4000 iters) by a factor of 10 2 # The train/test net protocol buffer definition 3 net: "examples/cifar10/cifar10_quick_train_test.prototxt" 4 # test_iter specifies how many forward passes the test should carry out. 5 # In the case of MNIST, we have test batch size 100 and 100 test iterations, 6 # covering the full 10,000 testing images. 7 test_iter: 100 8 # Carry out testing every 500 training iterations. 9 test_interval: 500 10 # The base learning rate, momentum and the weight decay of the network. 11 base_lr: 0.001 12 momentum: 0.9 13 weight_decay: 0.004 14 # The learning rate policy 15 lr_policy: "fixed" 16 # Display every 100 iterations 17 display: 100 18 # The maximum number of iterations 19 max_iter: 4000 20 # snapshot intermediate results 21 snapshot: 4000 22 snapshot_format: HDF5 23 snapshot_prefix: "examples/cifar10/cifar10_quick" 24 # solver mode: CPU or GPU 25 solver_mode: CPU
Caffe代碼快速梳理
Caffe是基於C++編寫的深度學習框架,大量使用了類的封裝、繼承、多態,閱讀Caffe的源碼也可以很好的學習C++。
參考《21天實戰Caffe》,開始閱讀Caffe的源碼
在Caffe的根目錄下執行 tree 命令,即可查看caffe的整個目錄結構:
tree -d
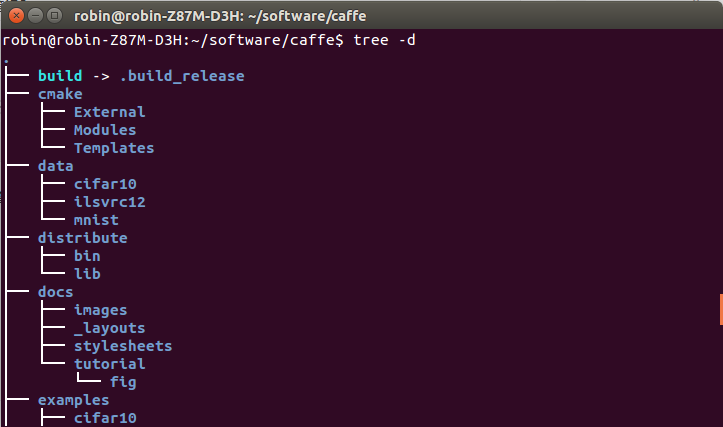
重點關註include/ src/ 和 tool/3個子目錄
借鑒別人經驗,一般來說,閱讀Caffe源碼的4步:
(1)看src/caffe/proto/caffe.proto,了解基本的數據結構內存對象和磁盤文件的映射關系
(2)看頭文件
(3)有針對性地看cpp和cu文件
(4)編寫各類工具,集成到caffe內部
菜鳥剛剛起步,感覺Caffe的源碼寫的還是很清晰的,希望以後可以耐心的好好啃吧。
Caffe網絡結構可視化
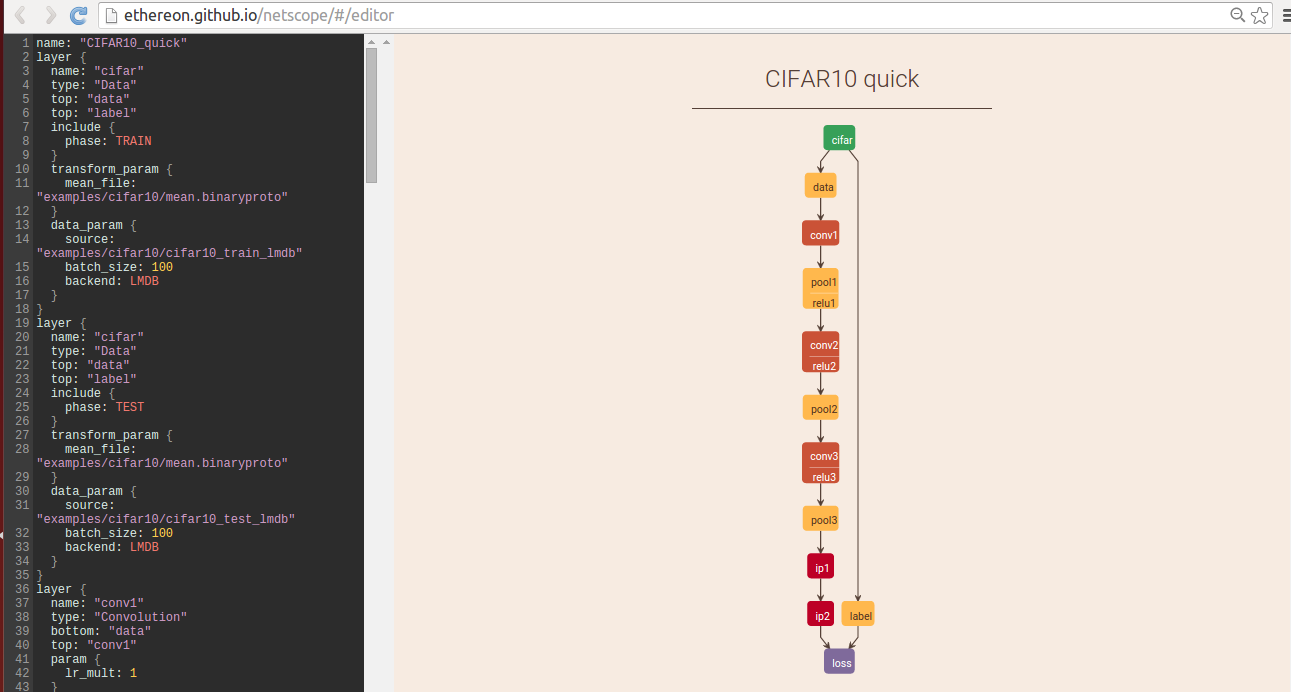
推薦可視化網站 <http://ethereon.github.io/netscope/#/editor>
CNN model的具體設置在prototxt文件裏面,將其內容復制到上面的網站即可看到網絡結構,方便調整和檢查網絡連接
就拿Cifar10數據集來說,找到caffe/examples/cifar10下的網絡定義prototxt文件,粘貼到網上左邊,然後Shilf+Enter,即可直觀看到網絡結構:
Caffe的Python開發
ipython notebook可以說是python開發深度學習的一個利器了
進入caffe的根目錄,輸入:
ipython notebook &
然後進入caffe的example目錄,自帶了一些python寫的demo
Caffe入門隨筆