
統計學習方法
boosting 算法: 通過改變訓練樣本的權重,學習多個分類器,並將多個分類器線性組合,提升分類性能。(對於一個復雜任務,將多個專家的判斷進行適當的綜合得出的判斷,要比任一一個單獨的判斷好) 將弱學習方法boost 為強學習算法。因為弱學習算法相對容易求得。提升算法就是從弱學習算法,出發反復學習,得到一系列弱分類器,然後組合為強分類器。
兩個問題:
1. 如何改變訓練數據的權重或概率分布
2. 如何將弱分類器組合
adaboost:
1. 提升前一輪弱分類器錯誤分類樣本的權值,降低正確分類樣本的權值
2. 加權多數表決方法,加大分類誤差率小的弱分類器的權值,減小分類誤差大的弱分類器的權值
adaboost 算法模型為加法模型,損失函數為指數函數,學習算法為前向分布算法時的二類分類學習方法。
boosting tree,
EM 算法:
用於含有隱變量的概率模型參數的極大似然估計,或極大後驗估計。
分為兩步: E步,求期望;M步求極大,
引入: 概率模型有時既含有觀測變量,又含有隱變量。 如果概率模型的變量都是觀測變量,那麽給數據,可以直接用極大似然估計。
例子:
3個硬幣: A,B,C, 正面朝上的概率分別為x,p,q; 先拋擲A,根據結果選出硬幣B或C,正面選B, 反面選C; 然後拋擲硬幣,拋擲結果出現正面記為1,出現反面記為0; 重復n次試驗
(1,1,0,1,0,0,1,0,1,1)
只能觀測到拋擲硬幣的結果,不能觀測到過程,問如何估計3個硬幣正面出現的概率。。即硬幣模型的參數:
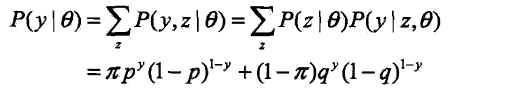


沒有解析解,只有通過叠代的方法求解。。。。EM算法就是用於求解這類叠代算法。
HMM : 標註問題的統計學習模型。生成模型。
CRF(條件隨機場):
給定一組輸入隨機變量條件下另一組輸出碎甲變量的條件概率分布模型。特點是假定輸出隨機變量構成馬兒克夫歲家常。
概率無向圖模型。。MRF, 是可以由一個無向圖表示的聯合概率分布。
統計學習方法