
誰動了我的特征?——sklearn特征轉換行為全記錄
目錄
1 為什麽要記錄特征轉換行為?
2 有哪些特征轉換的方式?
3 特征轉換的組合
4 sklearn源碼分析
4.1 一對一映射
4.2 一對多映射
4.3 多對多映射
5 實踐
6 總結
7 參考資料
1 為什麽要記錄特征轉換行為?
使用機器學習算法和模型進行數據挖掘,有時難免事與願違:我們依仗對業務的理解,對數據的分析,以及工作經驗提出了一些特征,但是在模型訓練完成後,某些特征可能“身微言輕”——我們認為相關性高的特征並不重要,這時我們便要反思這樣的特征提出是否合理;某些特征甚至“南轅北轍”——我們認為正相關的特征結果變成了負相關,造成這種情況很有可能是抽樣與整體不相符,模型過於復雜,導致了過擬合。然而,我們怎麽判斷先前的假設和最後的結果之間的差異呢?
線性模型通常有含有屬性coef_,當系數值大於0時為正相關,當系數值小於0時為負相關;另外一些模型含有屬性feature_importances_,顧名思義,表示特征的重要性。根據以上兩個屬性,便可以與先前假設中的特征的相關性(或重要性)進行對比了。但是,理想是豐滿的,現實是骨感的。經過復雜的特征轉換之後,特征矩陣X已不再是原來的樣子:啞變量使特征變多了,特征選擇使特征變少了,降維使特征映射到另一個維度中。
累覺不愛了嗎?如果,我們能夠將最後的特征與原特征對應起來,那麽分析特征的系數和重要性又有了意義了。所以,在訓練過程(或者轉換過程)中,記錄下所有特征轉換行為是一個有意義的工作。可惜,sklearn暫時並沒有提供這樣的功能。在這篇博文中,我們嘗試對一些常見的轉換功能進行行為記錄,讀者可以在此基礎進行進一步的拓展。
2 有哪些特征轉換的方式?
《使用sklearn做單機特征工程》一文概括了若幹常見的轉換功能:
| 類名 | 功能 | 說明 |
| StandardScaler | 數據預處理(無量綱化) | 標準化,基於特征矩陣的列,將特征值轉換至服從標準正態分布 |
| MinMaxScaler | 數據預處理(無量綱化) | 區間縮放,基於最大最小值,將特征值轉換到[0, 1]區間上 |
| Normalizer | 數據預處理(歸一化) | 基於特征矩陣的行,將樣本向量轉換為“單位向量” |
| Binarizer | 數據預處理(二值化) | 基於給定閾值,將定量特征按閾值劃分 |
| OneHotEncoder | 數據預處理(啞編碼) | 將定性數據編碼為定量數據 |
| Imputer | 數據預處理(缺失值計算) | 計算缺失值,缺失值可填充為均值等 |
| PolynomialFeatures | 數據預處理(多項式數據轉換) | 多項式數據轉換 |
| FunctionTransformer | 數據預處理(自定義單元數據轉換) | 使用單變元的函數來轉換數據 |
| VarianceThreshold | 特征選擇(Filter) | 方差選擇法 |
| SelectKBest | 特征選擇(Filter) | 可選關聯系數、卡方校驗、最大信息系數作為得分計算的方法 |
| RFE | 特征選擇(Wrapper) | 遞歸地訓練基模型,將權值系數較小的特征從特征集合中消除 |
| SelectFromModel | 特征選擇(Embedded) | 訓練基模型,選擇權值系數較高的特征 |
| PCA | 降維(無監督) | 主成分分析法 |
| LDA | 降維(有監督) | 線性判別分析法 |
按照特征數量是否發生變化,這些轉換類可分為:
- 無變化:StandardScaler,MinMaxScaler,Normalizer,Binarizer,Imputer,FunctionTransformer*
- 有變化:OneHotEncoder,PolynomialFeatures,VarianceThreshold,SelectKBest,RFE,SelectFromModel,PCA,LDA
對於不造成特征數量變化的轉換類,我們只需要保持特征不變即可。在此,我們主要研究那些有變化的轉換類,其他轉換類都默認為無變化。按照映射的形式,可將以上有變化的轉換類可分為:
- 一對一:VarianceThreshold,SelectKBest,RFE,SelectFromModel
- 一對多:OneHotEncoder
- 多對多:PolynomialFeatures,PCA,LDA
原特征與新特征為一對一映射通常發生在特征選擇時,若原特征被選擇則直接變成新特征,否則拋棄。啞編碼為典型的一對多映射,需要啞編碼的原特征將會轉換為多個新特征。多對多的映射中PolynomialFeatures並不要求每一個新特征都與原特征建立映射關系,例如階為2的多項式轉換,第一個新特征只由第一個原特征生成(平方)。降維的本質在於將原特征矩陣X映射到維度更低的空間中,使用的技術通常是矩陣乘法,所以它既要求每一個原特征映射到所有新特征,同時也要求每一個新特征被所有原特征映射。
3 特征轉換的組合
在《使用sklearn優雅地進行數據挖掘》一文中,我們看到一個基本的數據挖掘場景:
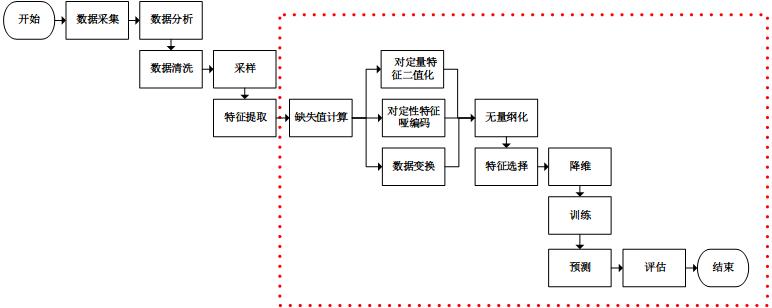
特征轉換行為通常是流水線型和並行型結合的。所以,我們考慮重新設計流水線處理類Pipeline和並行處理類FeatureUnion,使其能夠根據不同的特征轉換類,記錄下轉換行為“日誌”。“日誌”的表示形式也是重要的,由上圖可知,集成後的特征轉換過程呈現無環網狀,故使用網絡來描述“日誌”是合適的。在網絡中,節點表示特征,有向連線表示特征轉換。
為此,我們新增兩個類型Feature和Transfrom來構造網絡結構,Feature類型表示網絡中的節點,Transform表示網絡中的有向邊。python的networkx庫可以很好地表述網絡和操作網絡,我這是要重新造輪子嗎?其實並不是,現在考慮代表新特征的節點怎麽命名的問題,顯然,不能與網絡中任意節點同名,否則會發生混淆。然而,由於sklearn的訓練過程存在並行過程(線程),直接使用network來構造網絡的話,將難以處理節點重復命名的問題。所以,我才新增兩個新的類型來描述網絡結構,這時網絡中的節點名是可以重復的。最後,對這網絡進行廣度遍歷,生成基於networkx庫的網絡,因為這個過程是串行的,故可以使用“當前節點數”作為新增節點的序號了。這兩個類的代碼(feature.py)設計如下:

1 import numpy as np 2 3 class Transform(object): 4 def __init__(self, label, feature): 5 super(Transform, self).__init__() 6 #邊標簽名,使用networkx等庫畫圖時將用到 7 self.label = label 8 #該邊指向的節點 9 self.feature = feature 10 11 class Feature(object): 12 def __init__(self, name): 13 super(Feature, self).__init__() 14 #節點名稱,該名稱在網絡中不唯一,在某些映射中,該名稱需要直接傳給新特征 15 self.name = name 16 #節點標簽名,該名稱在網絡中唯一,使用networkx等庫畫圖時將用到 17 self.label = ‘%s[%d]‘ % (self.name, id(self)) 18 #從本節點發出的有向邊列表 19 self.transformList = np.array([]) 20 21 #建立從self到feature的有向邊 22 def transform(self, label, feature): 23 self.transformList = np.append(self.transformList, Transform(label, feature)) 24 25 #深度遍歷輸出以本節點為源節點的網絡 26 def printTree(self): 27 print self.label 28 for transform in self.transformList: 29 feature = transform.feature 30 print ‘--%s-->‘ % transform.label, 31 feature.printTree() 32 33 def __str__(self): 34 return self.label
4 sklearn源碼分析
我們可以統一地記錄不改變特征數量的轉換行為:在“日誌”網絡中,從代表原特征的節點,引伸出連線連上唯一的代表新特征的節點。然而,對於改變特征數量的轉換行為來說,需要針對每個轉換類編寫不同的“日誌”記錄(網絡生成)代碼。為不改變特征數量的轉換行為設計代碼(default.py)如下:
1 import numpy as np 2 from feature import Feature 3 4 def doWithDefault(model, featureList): 5 leaves = np.array([]) 6 7 n_features = len(featureList) 8 9 #為每一個輸入的原節點,新建一個新節點,並建立映射 10 for i in range(n_features): 11 feature = featureList[i] 12 newFeature = Feature(feature.name) 13 feature.transform(model.__class__.__name__, newFeature) 14 leaves = np.append(leaves, newFeature) 15 16 #返回新節點列表,之所以該變量取名叫leaves,是因為其是網絡的邊緣節點 17 return leaves
4.1 一對一映射
映射形式為一對一時,轉換類通常為特征選擇類。在這種映射下,原特征要麽只轉化為一個新特征,要麽不轉化。通過分析sklearn源碼不難發現,特征選擇類都混入了特質sklearn.feature_selection.base.SelectorMixin,因此這些類都有方法get_support來獲取哪些特征轉換信息:
所以,在設計“日誌”記錄模塊時,判斷轉換類是否混入了該特征,若是則直接調用get_support方法來得到被篩選的特征的掩碼或者下標,如此我們便可從被篩選的特征引伸出連線連上新特征。為此,我們設計代碼(one2one.py)如下:
1 import numpy as np 2 from sklearn.feature_selection.base import SelectorMixin 3 from feature import Feature 4 5 def doWithSelector(model, featureList): 6 assert(isinstance(model, SelectorMixin)) 7 8 leaves = np.array([]) 9 10 n_features = len(featureList) 11 12 #新節點的掩碼 13 mask_features = model.get_support() 14 15 for i in range(n_features): 16 feature = featureList[i] 17 #原節點被選擇,生成新節點,並建立映射 18 if mask_features[i]: 19 newFeature = Feature(feature.name) 20 feature.transform(model.__class__.__name__, newFeature) 21 leaves = np.append(leaves, newFeature) 22 #原節點被拋棄,生成一個名為Abandomed的新節點,建立映射,但是這個特征不加入下一步繼續生長的節點列表 23 else: 24 newFeature = Feature(‘Abandomed‘) 25 feature.transform(model.__class__.__name__, newFeature) 26 27 return leaves
4.2 一對多映射
OneHotEncoder是典型的一對多映射轉換類,其提供了兩個屬性結合兩個參數來表示轉換信息:
- n_values:定性特征的值數量,若為auto則直接從訓練集中獲取,若為整數則表示所有定性特征的值數量+1,若為數組則分別表示每個定性特征的數量+1
- categorical_features:定性特征的掩碼或下標
- active_features_:有效值(在n_values為auto時有用),假設A屬性取值範圍為(1,2,3),但是實際上訓練樣本中只有(1,2),假設B屬性取值範圍為(2,3,4),訓練樣本中只有(2,4),那麽有效值為(1,2,5,7)。是不是感到奇怪了,為什麽有效值不是(1,2,2,4)?OneHotEncoder在這裏做了巧妙的設計:有效值被轉換成了一個遞增的序列,這樣方便於配合屬性n_features快速地算出每個原特征轉換成了哪些新特征,轉換依據的真實有效值是什麽。
- feature_indices_:每個定性特征的有效值範圍,例如第i個定性特征,其有效值範圍為feature_indices_[i]至feature_indices_[i+1],sklearn官方文檔在此描述有誤,該數組的長度應為n_features+1。在上例中,feature_indices_等於(0,3,8)。故下標為0的定性特征,其有效值範圍為大於0小於3,則有效值為1和2;下標為1的定性特征,其有效值範圍為大於3小於8,則有效值為5和7。下標為0的定性特征,其兩個真實有效值為1-0=1和2-0=2;下標為1的定性特征,其兩個真實有效值為5-3=2和7-3=4。這樣一來就可以得到(1,2,2,4)的真實有效值了。
綜上,我們設計處理OneHotEncoder類的代碼(one2many.py)如下:
1 import numpy as np 2 from sklearn.preprocessing import OneHotEncoder 3 from feature import Feature 4 5 def doWithOneHotEncoder(model, featureList): 6 assert(isinstance(model, OneHotEncoder)) 7 assert(hasattr(model, ‘feature_indices_‘)) 8 9 leaves = np.array([]) 10 11 n_features = len(featureList) 12 13 #定性特征的掩碼 14 if model.categorical_features == ‘all‘: 15 mask_features = np.ones(n_features) 16 else: 17 mask_features = np.zeros(n_features) 18 mask_features[self.categorical_features] = 1 19 20 #定性特征的數量 21 n_qualitativeFeatures = len(model.feature_indices_) - 1 22 #如果定性特征的取值個數是自動的,即從訓練數據中生成 23 if model.n_values == ‘auto‘: 24 #定性特征的有效取值列表 25 n_activeFeatures = len(model.active_features_) 26 #變量j為定性特征的下標,變量k為有效值的下標 27 j = k = 0 28 for i in range(n_features): 29 feature = featureList[i] 30 #如果是定性特征 31 if mask_features[i]: 32 if model.n_values == ‘auto‘: 33 #為屬於第j個定性特征的每個有效值生成一個新節點,建立映射關系 34 while k < n_activeFeatures and model.active_features_[k] < model.feature_indices_[j+1]: 35 newFeature = Feature(feature.name) 36 feature.transform(‘%s[%d]‘ % (model.__class__.__name__, model.active_features_[k] - model.feature_indices_[j]), newFeature) 37 leaves = np.append(leaves, newFeature) 38 k += 1 39 else: 40 #為屬於第j個定性特征的每個有效值生成一個新節點,建立映射關系 41 for k in range(model.feature_indices_[j]+1, model.feature_indices_[j+1]): 42 newFeature = Feature(feature.name) 43 feature.transform(‘%s[%d]‘ % (model.__class__.__name__, k - model.feature_indices_[j]), newFeature) 44 leaves = np.append(leaves, newFeature) 45 j += 1 46 #如果不是定性特征,則直接根據原節點生成新節點 47 else: 48 newFeature = Feature(feature.name) 49 feature.transform(‘%s[r]‘ % model.__class__.__name__, newFeature) 50 leaves = append(leaves, newFeatures) 51 52 return leaves
4.3 多對多映射
PCA類是典型的多對多映射的轉換類,其提供了參數n_components_來表示轉換後新特征的個數。之前說過降維的轉換類,其既要求每一個原特征映射到所有新特征,也要求每一個新特征被所有原特征映射。故,我們設計處理PCA類的代碼(many2many.py)如下:
1 import numpy as np 2 from sklearn.decomposition import PCA 3 from feature import Feature 4 5 def doWithPCA(model, featureList): 6 leaves = np.array([]) 7 8 n_features = len(featureList) 9 10 #按照主成分數生成新節點 11 for i in range(model.n_components_): 12 newFeature = Feature(model.__class__.__name__) 13 leaves = np.append(leaves, newFeature) 14 15 #為每一個原節點與每一個新節點建立映射 16 for i in range(n_features): 17 feature = featureList[i] 18 for j in range(model.n_components_): 19 newFeature = leaves[j] 20 feature.transform(model.__class__.__name__, newFeature) 21 22 return leaves
5 實踐
到此,我們可以專註改進流水線處理和並行處理的模塊了。為了不破壞Pipeline類和FeatureUnion類的核心功能,我們分別派生出兩個類PipelineExt和FeatureUnionExt。其次,為這兩個類增加私有方法getFeatureList,這個方法有只有一個參數featureList表示輸入流水線處理或並行處理的特征列表(元素為feature.Feature類的對象),輸出經過流水線處理或並行處理後的特征列表。設計內部方法_doWithModel,其被getFeatureList方法調用,其提供了一個公共的入口,將根據流水線上或者並行中的轉換類的不同,具體調用不同的處理方法(這些不同的處理方法在one2one.py,one2many.py,many2many.py中定義)。在者,我們還需要一個initRoot方法來初始化網絡結構,返回一個根節點。最後,我們嘗試用networkx庫讀取自定義的網絡結構,基於matplotlib的對網絡進行圖形化顯示。以上部分的代碼(ple.py)如下:
1 from sklearn.feature_selection.base import SelectorMixin 2 from sklearn.preprocessing import OneHotEncoder 3 from sklearn.decomposition import PCA 4 from sklearn.pipeline import Pipeline, FeatureUnion, _fit_one_transformer, _fit_transform_one, _transform_one 5 from sklearn.externals.joblib import Parallel, delayed 6 from scipy import sparse 7 import numpy as np 8 import networkx as nx 9 from matplotlib import pyplot as plt 10 from default import doWithDefault 11 from one2one import doWithSelector 12 from one2many import doWithOneHotEncoder 13 from many2many import doWithPCA 14 from feature import Feature 15 16 #派生Pipeline類 17 class PipelineExt(Pipeline): 18 def _pre_get_featues(self, featureList): 19 leaves = featureList 20 for name, transform in self.steps[:-1]: 21 leaves = _doWithModel(transform, leaves) 22 return leaves 23 24 #定義getFeatureList方法 25 def getFeatureList(self, featureList): 26 leaves = self._pre_get_featues(featureList) 27 model = self.steps[-1][-1] 28 if hasattr(model, ‘fit_transform‘) or hasattr(model, ‘transform‘): 29 leaves = _doWithModel(model, leaves) 30 return leaves 31 32 #派生FeatureUnion類,該類不僅記錄了轉換行為,同時也支持部分數據處理 33 class FeatureUnionExt(FeatureUnion): 34 def __init__(self, transformer_list, idx_list, n_jobs=1, transformer_weights=None): 35 self.idx_list = idx_list 36 FeatureUnion.__init__(self, transformer_list=map(lambda trans:(trans[0], trans[1]), transformer_list), n_jobs=n_jobs, transformer_weights=transformer_weights) 37 38 def fit(self, X, y=None): 39 transformer_idx_list = map(lambda trans, idx:(trans[0], trans[1], idx), self.transformer_list, self.idx_list) 40 transformers = Parallel(n_jobs=self.n_jobs)( 41 delayed(_fit_one_transformer)(trans, X[:,idx], y) 42 for name, trans, idx in transformer_idx_list) 43 self._update_transformer_list(transformers) 44 return self 45 46 def fit_transform(self, X, y=None, **fit_params): 47 transformer_idx_list = map(lambda trans, idx:(trans[0], trans[1], idx), self.transformer_list, self.idx_list) 48 result = Parallel(n_jobs=self.n_jobs)( 49 delayed(_fit_transform_one)(trans, name, X[:,idx], y, 50 self.transformer_weights, **fit_params) 51 for name, trans, idx in transformer_idx_list) 52 53 Xs, transformers = zip(*result) 54 self._update_transformer_list(transformers) 55 if any(sparse.issparse(f) for f in Xs): 56 Xs = sparse.hstack(Xs).tocsr() 57 else: 58 Xs = np.hstack(Xs) 59 return Xs 60 61 def transform(self, X): 62 transformer_idx_list = map(lambda trans, idx:(trans[0], trans[1], idx), self.transformer_list, self.idx_list) 63 Xs = Parallel(n_jobs=self.n_jobs)( 64 delayed(_transform_one)(trans, name, X[:,idx], self.transformer_weights) 65 for name, trans, idx in transformer_idx_list) 66 if any(sparse.issparse(f) for f in Xs): 67 Xs = sparse.hstack(Xs).tocsr() 68 else: 69 Xs = np.hstack(Xs) 70 return Xs 71 72 #定義getFeatureList方法 73 def getFeatureList(self, featureList): 74 transformer_idx_list = map(lambda trans, idx:(trans[0], trans[1], idx), self.transformer_list, self.idx_list) 75 leaves = np.array(Parallel(n_jobs=self.n_jobs)( 76 delayed(_doWithModel)(trans, featureList[idx]) 77 for name, trans, idx in transformer_idx_list)) 78 leaves = np.hstack(leaves) 79 return leaves 80 81 #定義為每個模型進行轉換記錄的總入口方法,該方法將根據不同的轉換類調用不同的處理方法 82 def _doWithModel(model, featureList): 83 if isinstance(model, SelectorMixin): 84 return doWithSelector(model, featureList) 85 elif isinstance(model, OneHotEncoder): 86 return doWithOneHotEncoder(model, featureList) 87 elif isinstance(model, PCA): 88 return doWithPCA(model, featureList) 89 elif isinstance(model, FeatureUnionExt) or isinstance(model, PipelineExt): 90 return model.getFeatureList(featureList) 91 else: 92 return doWithDefault(model, featureList) 93 94 #初始化網絡的根節點,輸入參數為原始特征的名稱 95 def initRoot(featureNameList): 96 root = Feature(‘root‘) 97 for featureName in featureNameList: 98 newFeature = Feature(featureName) 99 root.transform(‘init‘, newFeature) 100 return root
現在,我們需要驗證一下成果了,不妨繼續使用博文《使用sklearn優雅地進行數據挖掘》中提供的場景來進行測試:
1 import numpy as np 2 from sklearn.datasets import load_iris 3 from sklearn.preprocessing import Imputer 4 from sklearn.preprocessing import OneHotEncoder 5 from sklearn.preprocessing import FunctionTransformer 6 from sklearn.preprocessing import Binarizer 7 from sklearn.preprocessing import MinMaxScaler 8 from sklearn.feature_selection import SelectKBest 9 from sklearn.feature_selection import chi2 10 from sklearn.decomposition import PCA 11 from sklearn.linear_model import LogisticRegression 12 from sklearn.pipeline import Pipeline, FeatureUnion 13 from ple import PipelineExt, FeatureUnionExt, initRoot 14 15 def datamining(iris, featureList): 16 step1 = (‘Imputer‘, Imputer()) 17 step2_1 = (‘OneHotEncoder‘, OneHotEncoder(sparse=False)) 18 step2_2 = (‘ToLog‘, FunctionTransformer(np.log1p)) 19 step2_3 = (‘ToBinary‘, Binarizer()) 20 step2 = (‘FeatureUnionExt‘, FeatureUnionExt(transformer_list=[step2_1, step2_2, step2_3], idx_list=[[0], [1, 2, 3], [4]])) 21 step3 = (‘MinMaxScaler‘, MinMaxScaler()) 22 step4 = (‘SelectKBest‘, SelectKBest(chi2, k=3)) 23 step5 = (‘PCA‘, PCA(n_components=2)) 24 step6 = (‘LogisticRegression‘, LogisticRegression(penalty=‘l2‘)) 25 pipeline = PipelineExt(steps=[step1, step2, step3, step4, step5, step6]) 26 pipeline.fit(iris.data, iris.target) 27 #最終的特征列表 28 leaves = pipeline.getFeatureList(featureList) 29 #為最終的特征輸出對應的系數 30 for i in range(len(leaves)): 31 print leaves[i], pipeline.steps[-1][-1].coef_[i] 32 33 def main(): 34 iris = load_iris() 35 iris.data = np.hstack((np.random.choice([0, 1, 2], size=iris.data.shape[0]+1).reshape(-1,1), np.vstack((iris.data, np.full(4, np.nan).reshape(1,-1))))) 36 iris.target = np.hstack((iris.target, np.array([np.median(iris.target)]))) 37 root = initRoot([‘color‘, ‘Sepal.Length‘, ‘Sepal.Width‘, ‘Petal.Length‘, ‘Petal.Width‘]) 38 featureList = np.array([transform.feature for transform in root.transformList]) 39 40 datamining(iris, featureList) 41 42 root.printTree() 43 44 if __name__ == ‘__main__‘: 45 main()
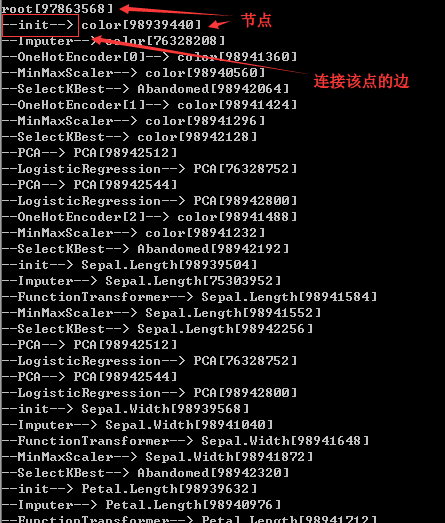
運行程序,最終的特征及對應的系數輸出如下:

輸出網絡結構的深度遍歷(部分截圖):
為了更好的展示轉換行為構成的網絡,我們還可以基於networkx構建有向圖,通過matplotlib進行展示(ple.py):
1 #遞歸的方式進行深度遍歷,生成基於networkx的有向圖
2 def _draw(G, root, nodeLabelDict, edgeLabelDict):
3 nodeLabelDict[root.label] = root.name
4 for transform in root.transformList:
5 G.add_edge(root.label, transform.feature.label)
6 edgeLabelDict[(root.label, transform.feature.label)] = transform.label
7 _draw(G, transform.feature, nodeLabelDict, edgeLabelDict)
8
9 #判斷是否圖是否存在環
10 def _isCyclic(root, walked):
11 if root in walked:
12 return True
13 else:
14 walked.add(root)
15 for transform in root.transformList:
16 ret = _isCyclic(transform.feature, walked)
17 if ret:
18 return True
19 walked.remove(root)
20 return False
21
22 #廣度遍歷生成瀑布式布局
23 def fall_layout(root, x_space=1, y_space=1):
24 layout = {}
25 if _isCyclic(root, set()):
26 raise Exception(‘Graph is cyclic‘)
27
28 queue = [None, root]
29 nodeDict = {}
30 levelDict = {}
31 level = 0
32 while len(queue) > 0:
33 head = queue.pop()
34 if head is None:
35 if len(queue) > 0:
36 level += 1
37 queue.insert(0, None)
38 else:
39 if head in nodeDict:
40 levelDict[nodeDict[head]].remove(head)
41 nodeDict[head] = level
42 levelDict[level] = levelDict.get(level, []) + [head]
43 for transform in head.transformList:
44 queue.insert(0, transform.feature)
45
46 for level in levelDict.keys():
47 nodeList = levelDict[level]
48 n_nodes = len(nodeList)
49 offset = - n_nodes / 2
50 for i in range(n_nodes):
51 layout[nodeList[i].label] = (level * x_space, (i + offset) * y_space)
52
53 return layout
54
55 def draw(root):
56 G = nx.DiGraph()
57 nodeLabelDict = {}
58 edgeLabelDict = {}
59
60 _draw(G, root, nodeLabelDict, edgeLabelDict)
61 #設定網絡布局方式為瀑布式
62 pos = fall_layout(root)
63
64 nx.draw_networkx_nodes(G,pos,node_size=100, node_color="white")
65 nx.draw_networkx_edges(G,pos, width=1,alpha=0.5,edge_color=‘black‘)
66 #設置網絡中節點的標簽內容及格式
67 nx.draw_networkx_labels(G,pos,labels=nodeLabelDict, font_size=10,font_family=‘sans-serif‘)
68 #設置網絡中邊的標簽內容及格式
69 nx.draw_networkx_edge_labels(G, pos, edgeLabelDict)
70
71 plt.show()
以圖形界面展示網絡的結構:
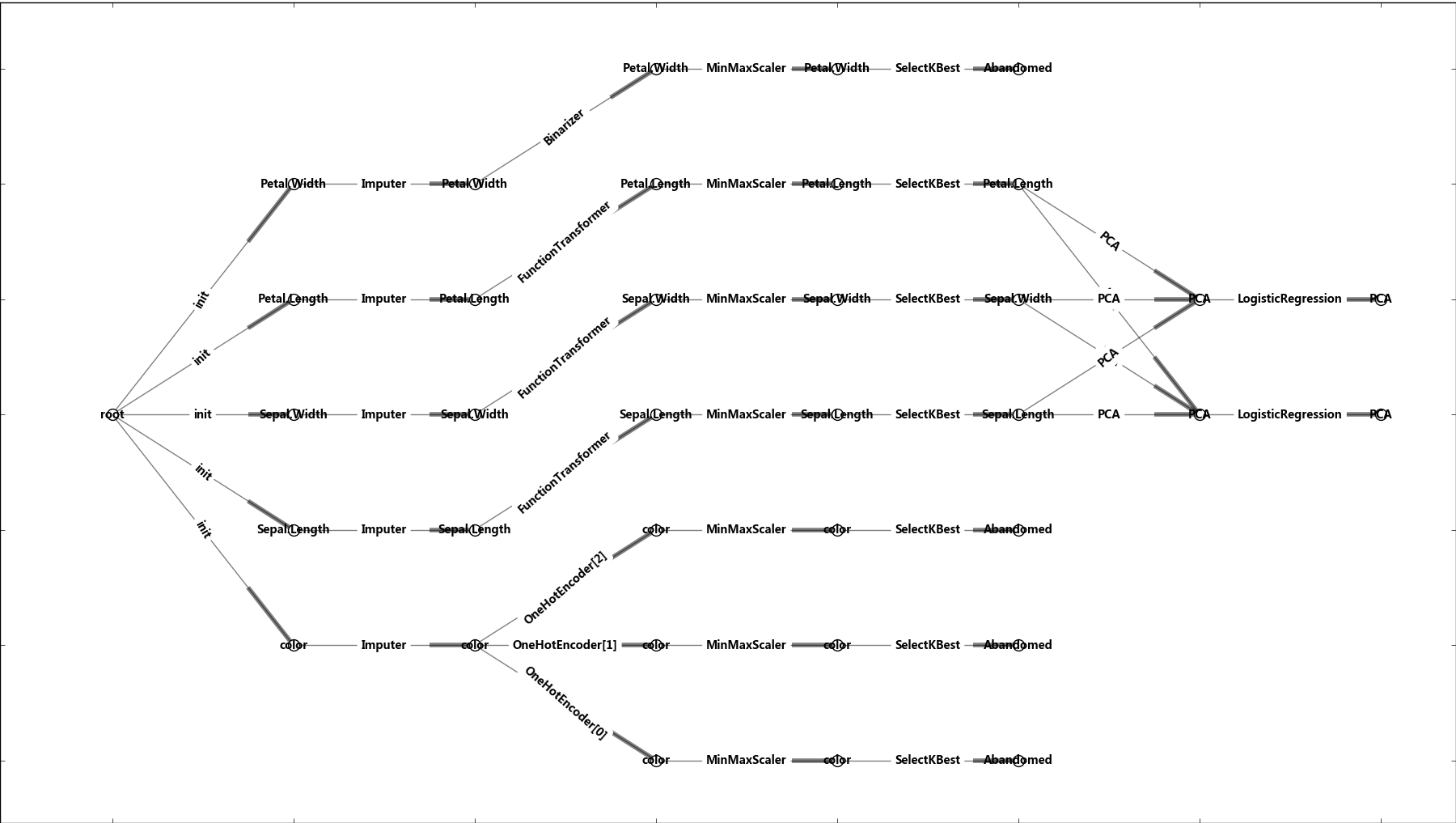
6 總結
聰明的讀者你肯定發現了,記錄下特征轉換行為的最好時機其實是轉換的同時。可惜的是,sklearn目前並不支持這樣的功能。在本文中,我將這一功能集中到流水線處理和並行處理的模塊當中,只能算是一個臨時的手段,但聊勝於無吧。另外,本文也是拋磚引玉,還有其他的轉換類,在原特征與新特征之間的映射關系上,百家爭鳴。所以,我在Github上新建了個庫,包含本文實例中所有的轉換類處理的代碼,在之後,我會慢慢地填這個坑,直到世界的盡頭,抑或sklearn加入該功能。
7 參考資料
作者的三篇關於數據挖掘的文章:可以直接查看原文鏈接:http://www.cnblogs.com/jasonfreak/p/5619260.html
- 《使用sklearn優雅地進行數據挖掘》
- 《使用sklearn做單機特征工程》
- sklearn.preprocessing.OneHotEncode
誰動了我的特征?——sklearn特征轉換行為全記錄