
深度學習激活函數比較
一、Sigmoid函數
1)表達式
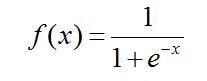
2)函數曲線

3)函數缺點
-
-
- 梯度飽和問題。先看一下反向傳播計算過程:
-
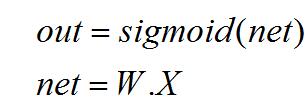
反向求導:
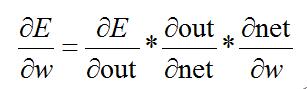
而其中:
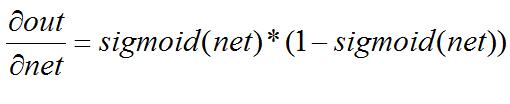
所以,由上述反向傳播公式可以看出,當神經元數值無線接近1或者0的時候,在反向傳播計算過程中,梯度也幾乎為0,就導致模型參數幾乎不更新了,對模型的學習貢獻也幾乎為零。也稱為參數彌散問題或者梯度彌散問題。
同時,如果初始權重設置過大,會造成一開始就梯度接近為0,就導致模型從一開始就不會學習的嚴重問題。
-
-
- 函數不是關於原點中心對稱的。
-
二、tanh函數
1)公式
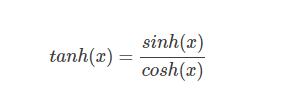
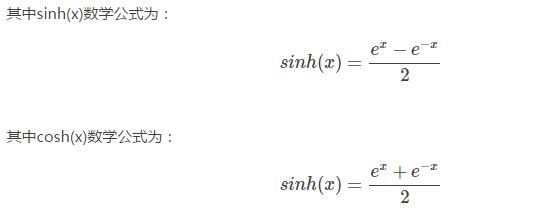
2)曲線
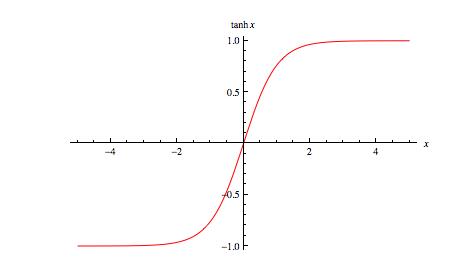
tanh 函數同樣存在飽和問題,但它的輸出是零中心的,因此實際中 tanh 比 sigmoid 更受歡迎。
三、ReLU函數
深度學習激活函數比較
相關推薦
深度學習激活函數比較
logs 過大 img ima .com 曲線 src pan 貢獻 一、Sigmoid函數 1)表達式 2)函數曲線 3)函數缺點 梯度飽和問題。先看一下反向傳播計算過程: 反向求導:
深度學習激活函數們
ali 會有 pack 網絡 fun 默認 .html 數學 一個 如下圖,在神經元中,輸入的 inputs 通過加權,求和後,還被作用了一個函數,這個函數就是激活函數 Activation Function。 如果不用激勵函數,每一層輸出都是上層輸入的線性函數,無論神
常用激活函數比較
lin www. 解釋 就是 什麽 註意 unit 什麽是 的區別 本文結構: 什麽是激活函數 為什麽要用 都有什麽 sigmoid、ReLU、softmax的比較 如何選擇 1. 什麽是激活函數 如下圖,在神經元中,輸入的inputs通過加權,求和後,還被作用了一個函
【深度學習】深入理解ReLU(Rectifie Linear Units)激活函數
appdata 稀疏編碼 去掉 ren lock per 作用 開始 href 論文參考:Deep Sparse Rectifier Neural Networks (很有趣的一篇paper) Part 0:傳統激活函數、腦神經元激活頻率研究、稀疏激活性
幹貨 | 深入理解深度學習中的激活函數
神經網絡學習 目標 tps 數值 函數表 我們 傳播 多少 當我 理解深度學習中的激活函數 在這個文章中,我們將會了解幾種不同的激活函數,同時也會了解到哪個激活函數優於其他的激活函數,以及各個激活函數的優缺點。 1. 什麽是激活函數? 生物神經網絡是人工神經網絡的起源。然而
深度學習之激活函數、優化方法和正則化
形式 unit 優勢 神經元 必須 vat 數值 line 利用 激活函數(activate function)在神經元中非常重要,為了增強網絡的表示能力和學習能力,激活函數需要具備以下幾點性質: (1)連續並可導的非線性函數,以便於利用數值優化的方法來學習網絡參數。
CNN學習筆記:激活函數
說明 param 情況 cnn fall 並且 輸入 inf oid CNN學習筆記:激活函數 激活函數 使用一個神經網絡時,需要決定使用哪種激活函數用隱藏層上,哪種用在輸出節點上。 在神經網路的前向傳播中,這兩步會使用到sigmoid函數。sigmoid
激活函數和損失函數
ref 常見 tail 問題 機器 學習 art mar 深度學習 深度學習筆記(三):激活函數和損失函數 損失函數:Hinge Loss(max margin) 機器學習中的常見問題——損失函數激活函數和損失函數
激活函數
測試 加載 分享圖片 過程 分類問題 圖片 alt 得到 如果 神經網絡做的主要事情就是分類,在上課中,最簡單的問題為二分類問題,利用單層感知機,可以畫出一條線將平面隔開分類。同樣如果增加感知機個數,可以得到更強的分類能力,但是無論如何都是一個線性方程。只不過是線性的復雜組
1.4激活函數-帶隱層的神經網絡tf實戰
ima 需要 logs .com horizon optimizer 數量 sid ont 激活函數 激活函數----日常不能用線性方程所概括的東西 左圖是線性方程,右圖是非線性方程 當男生增加到一定程度的時候,喜歡女生的數量不可能無限制增加,更加趨於平穩
神經網絡(六)激活函數
過程 ++ 初始 clas 等價 輸入 通過 height tex 激活函數是用來加入非線性因素的,解決線性模型所不能解決的問題。 激活函數通常有如下一些性質: 非線性: 當激活函數是線性的時候,一個兩層的神經網絡就可以逼近基本上所有的函數了。但是,如果激活函數是恒等
激活函數筆記
ima 技術 detail png cto proc .net http shadow sigmod [0,1]tanh [-1,1]relu max(0,x)參考:http://blog.csdn.net/u013146742/article/details/519865
ANN神經網絡——Sigmoid 激活函數編程練習 (Python實現)
poi eight rac inter sce ould error def logistic # ---------- # # There are two functions to finish: # First, in activate(), write th
Tensorflow中神經網絡的激活函數
and ftp panda frame item plt index line 圖片 激勵函數的目的是為了調節權重和誤差。 relu max(0,x) relu6 min(max(0,x),6) sigmoid 1/(1+exp(-x))
關於幾種激活函數的整理
函數 關於 gpo www details http sdn body .net https://blog.csdn.net/lilu916/article/details/77822309 https://www.zhihu.com/question/29021768
神經網絡激活函數
this fun clas soft func end open AS introduce # Activation Functions #---------------------------------- # # This function introduces
[吃藥深度學習隨筆] 損失函數
global flow SQ oss 網絡層 訓練 dom AD atm 神經元模型 常用的激活函數(激勵函數): 神經網絡(NN)復雜度:多用神經網絡層數和神經網絡參數個數來表示 層數 = 隱藏層層數+1個輸出層 參數個數 = 總W(權重) +
神經網絡激活函數sigmoid relu tanh 為什麽sigmoid 容易梯度消失
曲線 區別 -c put orien 互斥 dde .net 設置 https://blog.csdn.net/danyhgc/article/details/73850546 什麽是激活函數 為什麽要用 都有什麽 sigmoid ,ReLU, softmax 的比較 如
激活函數的作用
曲線 說明 index edi mage gpo 知乎 二分 映射 機器學習筆記:形象的解釋神經網絡激活函數的作用是什麽? 此文轉自知乎,哈工大NLPer 憶臻 原出處:https://zhuanlan.zhihu.com/p/25279356 查閱資料和學習,大家對神
ReLU激活函數的缺點
因此 shu 數學 IV OS 固定 通過 輸入 現在 訓練的時候很”脆弱”,很容易就”die”了,訓練過程該函數不適應較大梯度輸入,因為在參數更新以後,ReLU的神經元不會再有激活的功能,導致梯度永遠都是零。 例如,一個非常大的梯度流過一個 ReLU 神經元,更新過參數之