
機器學習--決策樹
基本流程:
決策樹:
根結點:屬性測試,包含樣本全集
內部結點:屬性測試,根據屬性測試的結果被劃分到子結點中
葉結點:決策結果

劃分選擇:如何選擇最優劃分屬性。目標是結點的"純度"越來越高
1.信息增益:
使用“信息熵”:

信息增益越大,意味使用屬性a劃分所獲得的“純度提升”越大。因此可以使用信息增益進行決策樹的劃分屬性選擇。即在決策樹算法的圖中的第八行選擇屬性a*=argmaxGain(D,a)
2.增益率
Gain_ratio(D,a)=Gain(D,a)/IV(a)
IV(a)=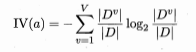
3.基尼指數
數據集的純度可用基尼值來度量

剪枝:
如果能為決策樹帶來泛化性能提升,則將該子樹替換為葉結點。
預剪枝,後剪枝
連續與缺失值
二分法、
機器學習--決策樹
相關推薦
機器學習--決策樹
-1 最優 bsp p s 分享 log cnblogs 學習 tex 基本流程: 決策樹: 根結點:屬性測試,包含樣本全集 內部結點:屬性測試,根據屬性測試的結果被劃分到子結點中 葉結點:決策結果 劃分選擇:如何選擇最優劃分屬性。目標
機器學習—決策樹
images dot grid acc port tree special orm criterion import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.
AI機器學習-決策樹算法-概念和學習過程
人工智能 其他 1. 概念決策樹是通過一系列規則對數據進行分類的過程,它提供一種在什麽條件下會得到什麽值的類似規則的方法。決策樹分為分類樹和回歸樹兩種,分類樹對離散變量做決策樹,回歸樹對連續變量做決策樹。分類決策樹模型是一種描述對實例進行分類的樹形結構。決策樹由結點和有向邊組成。結點有兩種類型:內部節
機器學習——決策樹和隨機森林演算法
認識決策樹 決策樹思想的來源非常樸素,程式設計中的條件分支結構就是if-then結構,最早的決策樹就是利用這類結構分割資料的一種分類學習方法。 下面以一個問題引出決策樹的思想 這個問題用圖來表示就是這樣: 為什麼先把年齡放在第一個呢,下面就是一個概念:資訊熵 資訊熵
機器學習-決策樹演算法
機器學習中分類和預測演算法的評估: 1.準確率 2.速度 3.強壯性 4.可規模性 5.可解釋性 1.什麼是決策樹/判定樹 判定樹是一個類似於流程圖的樹結構:其中,每個內部結點表示在一個屬性上的測試,每個分支代表一個屬性輸出,而每個樹葉結點代表類或類分佈。樹
機器學習--決策樹演算法學習筆記
一、演算法表述 決策樹學習的目的是為了產生一顆泛化能力強的數。 一般來說,一顆決策樹包含一個根節點,若干個內部節點和若干個葉節點。 葉節點對應決策結果,其他每個節點對應一個屬性測試。 每個節點包含的樣本集合根據屬性測試的結果被劃分到子節點中,根節點包含樣本全集。 從
機器學習-決策樹(decision tree)
機器學習中分類和預測演算法的評估: 準確率 速度 強壯性(演算法中當有噪音和某些值缺失時,演算法能否依然很好) 可規模性 可解釋性(能否很好的解釋模型) 一、什麼是決策樹? 1、判定樹(決策樹)是一個類似於流程圖的樹結構,其中,每個內部節點表示在一個屬性上的
機器學習--決策樹及泰坦尼克號生存預測
決策樹是一個類似於流程圖的樹結構,分支節點表示對一個特徵進行測試,根據測試結果進行分類,樹葉節點代表一個類別。 要判斷從哪個特徵進行分裂,就要對資訊進行量化,量化的方式有: ID3: 資訊增益 條件熵: 其中pi=P(X=xi),X,Y代表了兩個事件,而它們之間有
機器學習——決策樹
1 import numpy as np 2 import pandas as pd 3 from sklearn.feature_extraction import DictVectorizer 4 from sklearn.model_selection import train_test_sp
機器學習 決策樹 隨機森林演算法
決策樹 概念 有關決策樹的理論參考: https://blog.csdn.net/gunhunti4524/article/details/81506012 不再贅述 要注意的是,sklearn預設使用的是 基尼係數 同是介紹一個數據集網站 http://biostat.mc.v
機器學習---決策樹decision tree的應用
1.Python 2.Python機器學習的庫:scikit-learn 2.1 特性: 簡單高效的資料探勘和機器學習分析 對所有使用者開放,根據不同需求高度可重用性 基於Numpy,SciPy和matplotlib 開源的,且可達到商用級別,獲
機器學習 - 決策樹(下)- CART 以及與 ID3、C4.5的比較
機器學習 - 決策樹(下)- CART 以及與 ID3、C4.5的比較 CART 迴歸樹 分類樹 剪枝 剪枝 選擇 決策樹特點總結 ID3,C4.
機器學習 - 決策樹(中)- ID3、C4.5 以及剪枝
機器學習 - 決策樹(中)- ID3、C4.5 以及剪枝 決策樹簡述 決策樹過程 ID3 C4.5 過擬合 剪枝定義 剪枝過程
機器學習 - 決策樹(上)- 資訊理論基礎
機器學習 - 決策樹 and 資訊理論基礎 熵 自資訊 夏農熵 交叉熵 條件熵 互資訊(ID3 所使用的資訊增益) KL 散度(相對熵)
機器學習-決策樹(Entscheidungsbäume)
決策樹 基礎知識 樹的構成: 1.每一個內部節點代表一個屬性測試 2.每個分支對應特定的屬性值 3.每個葉子節點對應一個分類 樹的描述: 對於樹通常可以用一個析取正規化表示,每一個klausel對應著樹上從跟到葉子節點的一條路徑 比如: (
機器學習決策樹:提煉出分類器演算法
,用到決策樹一般都會出現過擬合問題,因此需要對決策樹進行剪枝,闡述了常用的幾種剪枝的方法(這些方法都出現在了sklearn的決策樹建構函式的引數中),後面總結了sklearn調包分析用決策樹做分類和迴歸的幾個例子,下面通過一個簡單的例子,提煉出構建一棵分類決策樹的演算法思想,進一步體會下決策樹的分類原
機器學習-決策樹-ID3, C4.5
概念: 決策樹:節點間的組織方式像一棵倒樹,以attribute為節點,以attribute的不同值為分支。 重點概念: 1. 資訊熵: 熵是無序性(或不確定性)的度量指標。假如事件A的全概率劃分是(A1,A2,...,An),每部分發生的概率是(p1,p2,...,pn
[機器學習]決策樹中的資訊增益和資訊增益比
一、特徵選擇中的資訊增益 什麼是資訊增益? 資訊增益是特徵選擇中的一個重要的指標,它定義為一個特徵能為分類系統帶來多少資訊,資訊越多,該特徵就越重要。 這樣就又有一個問題:如何衡量一個特徵為分類系統帶來了多少資訊呢? 對一個特徵而言,系統有它的時候和沒有它的時候資訊量將會發
機器學習 —— 決策樹及其整合演算法(Bagging、隨機森林、Boosting)
決策樹 --------------------------------------------------------------------- 1.描述: 以樹為基礎的方法可以用於迴歸和分類。 樹的節點將要預測的空間劃分為一系列簡單域 劃分預測空間的規則可以被建模為
機器學習決策樹演算法解決影象識別
演算法介紹 什麼是決策樹演算法 決策樹又稱判定樹,是一個類似於流程圖的樹結構:其中,每個內部結點表示在一個屬性上的測試,每個分支代表一個屬性輸出,而每個樹葉結點代表類或類分佈。樹的最頂層是根結點。 構造決策樹的基本演算法 主要評估標準,準確率,速度,健壯性,可規模性,可解