
機器學習—決策樹
阿新 • • 發佈:2017-10-06
images dot grid acc port tree special orm criterion
import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.tree import DecisionTreeClassifier from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split from sklearn.datasets import load_iris from sklearn import metrics %matplotlib inline
#載入數據 iris = load_iris() x = iris.data y = iris.target x_train,x_test,y_train,y_test = train_test_split(x,y,train_size=0.7,random_state=0) #數據處理 sc = StandardScaler() x_train_std = sc.fit_transform(x_train) x_test_std = sc.transform(x_test) #建立模型 dt = DecisionTreeClassifier(criterion=‘entropy‘,max_depth=3) #先設置一個三層的決策樹,設置劃分標準為信息增益 dt.fit(x_train_std,y_train) y_pred = dt.predict(x_test_std) accuracy = metrics.accuracy_score(y_test,y_pred) accuracy
輸出結果:0.97777777777777775
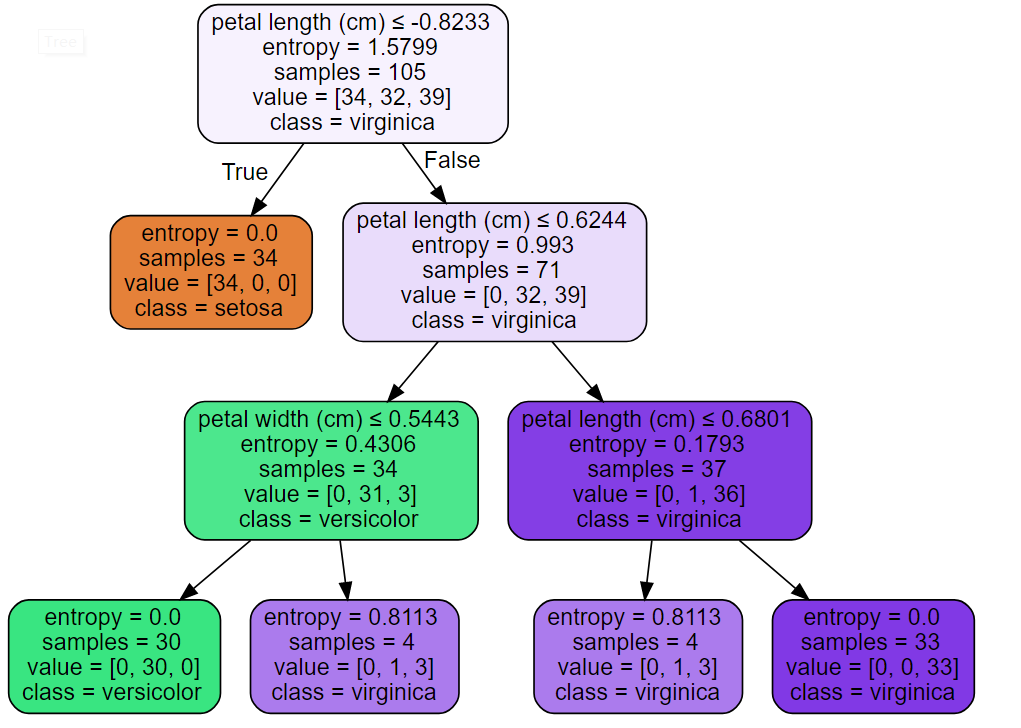
#決策樹輸出到pdf from sklearn import tree import graphviz dot_data = tree.export_graphviz(dt,out_file=None) graph = graphviz.Source(dot_data) graph.render(‘iris‘) #直接輸出決策樹 dot_data = tree.export_graphviz(dt, out_file=None, feature_names=iris.feature_names, class_names=iris.target_names, filled=True, rounded=True, special_characters=True) graph = graphviz.Source(dot_data) graph
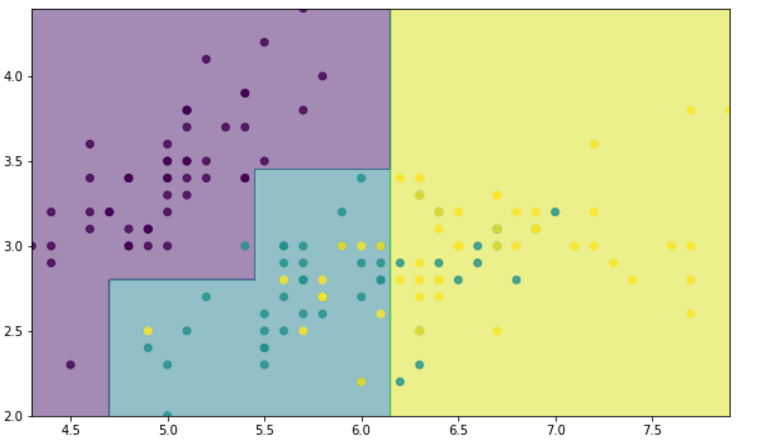
#分類效果畫圖出來,只選擇其中兩個變量做圖 x = iris.data x = x[:,:2] y = iris.target M,N = 500,500 x1_min,x1_max = x[:,0].min(),x[:,0].max() x2_min,x2_max = x[:,1].min(),x[:,1].max() t1 = np.linspace(x1_min,x1_max,M) t2 = np.linspace(x2_min,x2_max,N) x1,x2 = np.meshgrid(t1,t2) x_test = np.stack((x1.flat,x2.flat),axis=1) dt = DecisionTreeClassifier(max_depth=3) dt.fit(x,y) y_show = dt.predict(x_test) y_show = y_show.reshape(x1.shape) fig = plt.figure(figsize=(10,6),facecolor=‘w‘) plt.contourf(x1,x2,y_show,alpha=0.5) plt.scatter(x[:,0],x[:,1],c = y.ravel(),alpha=0.8) plt.xlim(x1_min,x1_max) plt.ylim(x2_min,x2_max)
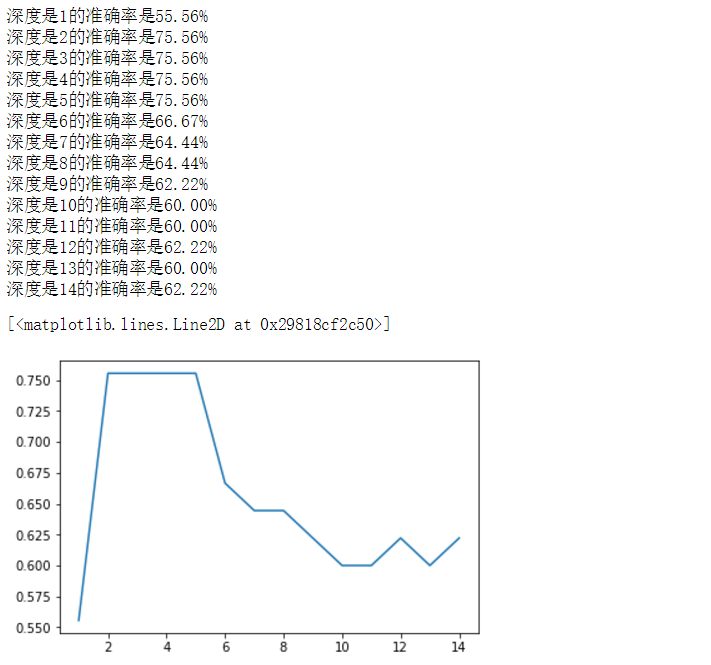
#不同深度的樹,對預測結果的好壞 x = iris.data x = x[:,:2] y = iris.target x_train,x_test,y_train,y_test = train_test_split(x,y,train_size=0.7,random_state=1) sc = StandardScaler() x_train_std = sc.fit_transform(x_train) x_test_std = sc.transform(x_test) err_list = [] for depth in range(1,15): dt = DecisionTreeClassifier(max_depth=depth) dt.fit(x_train_std,y_train) y_pred = dt.predict(x_test_std) print(‘深度是%s的準確率是%.2f%%‘%(depth,metrics.accuracy_score(y_test,y_pred)*100)) err_list.append(metrics.accuracy_score(y_test,y_pred)) plt.plot(range(1,15),err_list)
機器學習—決策樹