
Mysql性能優化之覆蓋索引
阿新 • • 發佈:2017-09-30
查找 cnblogs 都是 記錄 性能優化 nod 如果 libary 使用
因為我們大多數情況下使用的都是Innodb,所以這篇博客主要依據Innodb來講
b+樹(圖片來自網絡)
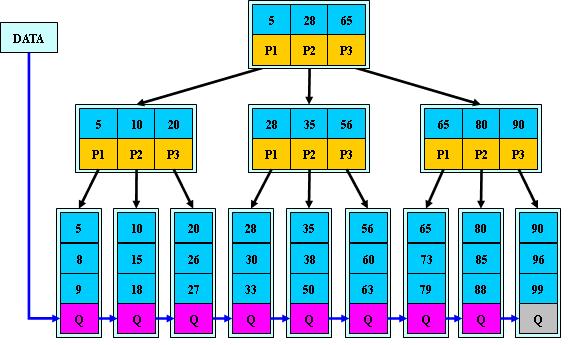
b+樹圖來自網絡
1.聚集索引與非聚集索引區別
聚集索引:葉子節點包含完整的數據(物理地址連續),叫做聚集索引
非聚集索引(又稱輔助索引):它的葉子節點並不包含行記錄的全部數據,葉子結點除了包含鍵值以外,每個葉子結點中的索引行還包含了一個書簽,該書簽用來告訴存儲引擎可以在哪找到相應的數據行。需要引用主索引作為data域,其實原理就是直接通過輔助索引無法找到數據,需要通過輔助索引找到主鍵,然後再根據主索引去查找其對應葉子節點的數據。其過程就是(輔助索引+主鍵+columns值)。
2.分頁需要優化原因
例:select a from table where b=1
①如果b字段沒有索引,則數據庫會進行全表掃描,掃描所有的數據庫
②如果b字段有索引,索引需要掃描3個數據塊
⑴獲取所有b=1的主鍵與其rowid
⑵再根據rowid查找數據。
⑶如果數據不在該數據塊回表,如果a在索引中則不會表。
其緩慢的原因其實是因為輔助索引需要回表去根據主鍵再去查詢。
3.分頁具體實現
例:select book_name,book_info from libary limit 20000,10 (表主鍵為其id)
覆蓋索引:包含所有滿足查詢需要的索引成為覆蓋索引
即(id,book_name,book_info)作為組合索引,就是覆蓋索引的一種體現
Mysql性能優化之覆蓋索引