
論文閱讀:A Primer on Neural Network Models for Natural Language Processing(1)
前言
2017.10.2博客園的第一篇文章,Mark。
由於實驗室做的是NLP和醫療相關的內容,因此開始啃NLP這個硬骨頭,希望能學有所成。後續將關註知識圖譜,深度強化學習等內容。
進入正題,該文章是用神經網絡處理NLP問題的Introduciton。希望讀完此文能夠對自然語言處理(using NN)有一個基本的概念。
本文所有引用的文字和圖片來自於論文《A Primer on Neural Network Models for Natural Language Processing》,作者Yoav Goldberg。
一、術語解釋
Feature :a concrete, linguistic input such as a word, a suffix, or a part-of-speech(詞性,詞類) tag.特征,一個單詞,或者一個下標,或者一個詞類標簽
Input vector
Input vector entry: a specific value of the input。輸入的特征值
二、兩類神經網絡介紹
1. 全連接前饋神經網絡在分類任務上相比之傳統的方法有很多的優點。
應用:A series of works2 managed to obtain improved syntactic parsing results by simply replacing the linear model of a parser with a fully connected feed-forward network. Straight-forward applications of a feed-forward network as a classifier replacement (usually coupled with the use of pre-trained word vectors) provide benefits also for CCG supertagging,3 dialog state tracking,4 pre-ordering for statistical machine translation5 and language modeling.6 Iyyer, Manjunatha, Boyd-Graber, and Daum′e III (2015) demonstrate that multi-layer feed-forward networks can provide competitive results on sentiment classi- fication and factoid question answering.
2. CNN(主要是卷積和池化層)能夠找到非固定位置的關鍵特征。
應用:Convolutional and pooling architecture show promising results on many tasks, including document classification,7 short-text categorization,8 sentiment classification,9 relation type classification between entities,10 event detection,11 paraphrase identification,12 semantic role labeling,13 question answering,14 predicting box-office revenues of movies based on critic reviews,15 modeling text interestingness,16 and modeling the relation between character-sequences and part-of-speech tags.17
3.卷積神經網絡允許我們將任意長度的句子編碼到固定大小的序列,該序列能體現出這個句子最主要的特征,但是這是在犧牲了大部分句子的結構信息上實現的。而循環神經網絡和遞歸神經網絡允許我們在保留大部分結構信息的情況下處理序列和樹。循環神經網絡被設計用來生成序列,遞歸神經網絡是一般化的循環神經網絡,被用來處理樹狀結構,同時遞歸神經網絡還可以用來處理堆(stacks)。
三、特征描述
1. 神經網絡通常都被看作是一個分類器,輸入x的維度為Din,選擇Dout種輸出中的一種作為輸出。輸入x是對單詞,詞性標註,或是其他語義詞匯進行編碼。從稀疏輸入的線性模型到神經網絡的最大區別就是停止使用了一維編碼(例如one-hot編碼),轉而采取了稠密向量編碼。即每一個特征被編碼為一個d維空間中的向量。這些核心特征能夠像神經網絡的參數一樣被訓練。不同的特征其維度也可能不同,如詞特征可能需要100維,但詞性特征可能只需要20維。如下圖所示。
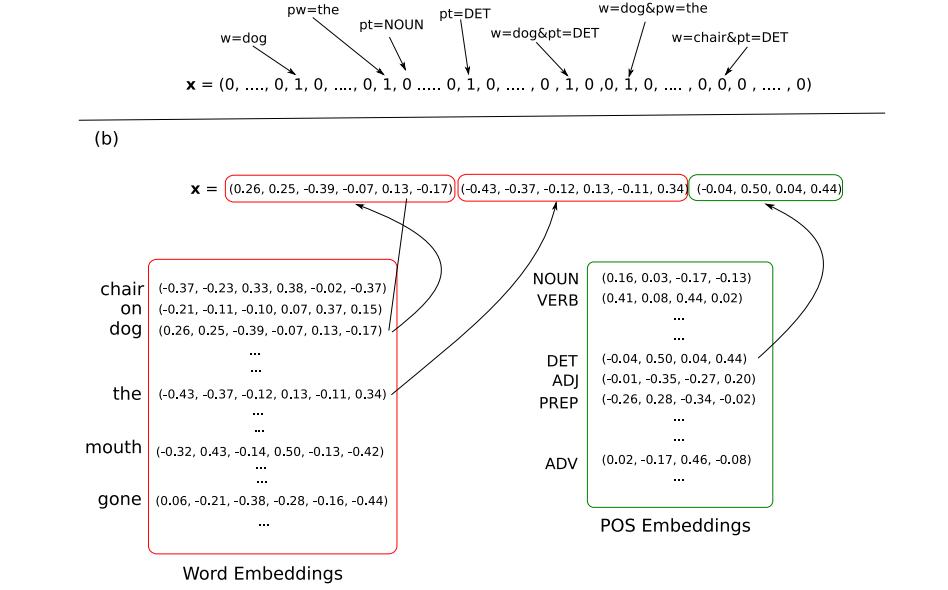
通常的NLP鑒別器處理流程如下:
A 提取出與輸出類別相關的核心特征集合。
B 對每一個特征找到其對應的向量。
C 將每個向量整合到輸入向量x(可以采取多種合並方法)。
D 將輸入向量傳給NN。
這其間有兩個難點,一是將向量的稀疏表示轉換為稠密表示,二是僅僅提取核心向量。
2.one-hot編碼和稠密編碼的區別
One-hot編碼的特征:A 維度等於總特征個數 B 特征之間沒有任何相關性
Dense編碼特征:A 維度為d,小於總特征 B 特征之間相似的距離將會比較近。
Dense編碼的主要好處還是在於能夠將類似的詞進行相似的編碼。那麽NN就能夠用相同的辦法來處理十分相似的兩個向量。
3.不定數量的特征的表示,CBOW和WCBOW
CBOW就是將特征取均值,而WCBOW則是為每個特征加上了權重。
4.距離和位置特征
在傳統的NLP處理任務中,詞與詞之間的距離通過距離來表示,如從1到10或更多,並且每個距離對應一個one-hot編碼。但是在NN中,距離向量與其他特征的編碼類似,每個距離被分配一個d維向量,與神經網絡的參數一起被訓練。
5.特征組合
NN僅處理核心特征,而傳統的線性NLP處理系統需要手工的指定特征和它們之間的關系。傳統的NLP需要很謹慎的設計特征之間的關系,以保證特征之間的線性可分,並且還要處理隨著特征組合而不斷增長的輸入序列。但是NN的設計者可以期望NN網絡自行發現潛在的特征關系,而不需要人們去手工的設置特征關系。這大大的減少了工作量。
核方法,特別是多項式核方法,與NN類似,可以只關註核心特征。但是核方法的計算規模同輸入數據的大小相關。如果輸入過大,則處理速度會非常慢。
6.維度
數據的維度沒有通用的方法來進行確定,一般來說,詞的維度會比詞性的維度大。詞的維度大概從50到幾百維,有的可能達到上千維。比較好的方法是多測試一些維度,從中找到最適合的。
7.向量共享
對於同一個詞在上下文中可能代表不同意義的情況,需要按照經驗進行判定。如果在上下文中,同一個單詞的意義不同,我們則需要聯系語境,分配不同的向量。
8.NN的輸出
一般來說還是一個d類的分類器。但是也可以構造一個d*k的輸出矩陣,表示有d類輸出,但是輸出之間有k種聯系。也就是說輸出不是完全獨立的,是有關聯的。
四、前饋神經網絡
講述神經網絡基本原理,不需額外贅述。
1.常見的非線性函數
A SIGMOID ![]() 最常見的激活函數,但現在在網絡內層不經常用,下面幾種函數是它的替代。
最常見的激活函數,但現在在網絡內層不經常用,下面幾種函數是它的替代。
B TANH ![]()
C HARD TANH 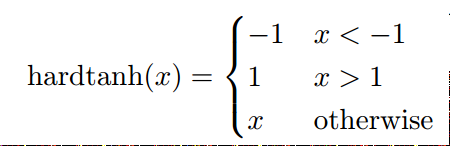 相比起TANH來說更容易計算。
相比起TANH來說更容易計算。
D ReLU 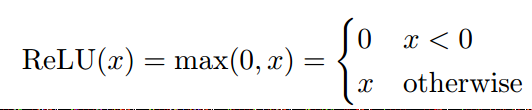 該函數是在實際中,表現最好的函數。
該函數是在實際中,表現最好的函數。
2.輸出層
基本上就是sigmoid函數,選取概率最大的項進行輸出。一般需要網絡能夠計算輸出的概率,例如交叉熵。當網絡不含有隱層時,就是有名的最大熵模型。
3.嵌入層Embedding Layer
負責實現詞嵌入。一般認為是神經網絡的一部分。
五、詞嵌入
當有足夠多的數據時,詞嵌入和訓練神經網絡一樣,初始化網絡為隨機值,然後進行訓練。有些論文研究了初始化參數值的範圍(一般會根據向量的維度來確認)。
在實際中,一般一些經常出現的特征,如詞性標註和獨立的字母,會用隨機值來初始化。而一些存在潛在關系的詞,例如一些獨立的單詞,將會用有監督或無監督的方式來初始化。這些預訓練的向量能在網絡訓練過程中看作是固定的參數,或者,更常見的,同隨機初始化的值一樣進行對待。
在大部分情況下,提供訓練的語料標註往往不足,這樣就不能很好的進行監督學習的預訓練,所以無監督訓練可能會更加常見。無監督訓練的目的是為了發現詞與詞之間的相似性,通常根據這樣一條準則,即,相似上下文環境的詞的相似度很高。
通過大量無監督訓練,能很好的提升模型的泛化能力,能對在監督訓訓練未出現的詞進行更好的處理。
常見的詞嵌入方法包括Word2Vec,GloVE,和the Collobert and Weston (2008, 2011) embeddings algorithm。
論文閱讀:A Primer on Neural Network Models for Natural Language Processing(1)