
『 論文閱讀』A Multi-View Deep Learning Approach for Cross Domain User Modeling in Recommendation Systems
Abstract
MULTI-VIEW-DNN聯合了多個域做的豐富特徵,使用multi-view DNN模型構建推薦,包括app、新聞、電影和TV,相比於最好的演算法,老使用者提升49%,新使用者提升110%。並且可以輕鬆的涵蓋大量使用者,解決冷啟動問題。
主要做user embedding的過程,通多使用者在多個域的行為作為一個ivew,來表徵使用者,參與使用者embedding過程。
Contribution
- 利用豐富的使用者特徵,建立多用途的使用者推薦系統。
- 針對基於內容的推薦,提出了一種深度學習方法。並學習不同的技術擴充套件推薦系統。
- 結合不同領域的資料,提出了Multi-View DNN模型建立推薦系統。
- multi-view DNN模型解決使用者冷啟動問題。
- 基於四個真實的大規模資料集,通過嚴格的實驗證明所提出的推薦系統的有效性。
Data Set
| Type | DataSet | UserCnt | FeatureSize | Joint Users |
|---|---|---|---|---|
| User view | Search | 20M | 3.5M | / |
| Item View | News Apps Movie/TV | 5M 1M 60K | 100K 50K 50K | 1.5M 210K 60K |
DSSM FOR USER MODELING IN RECOMMENDATION SYSTEMS
結構圖:
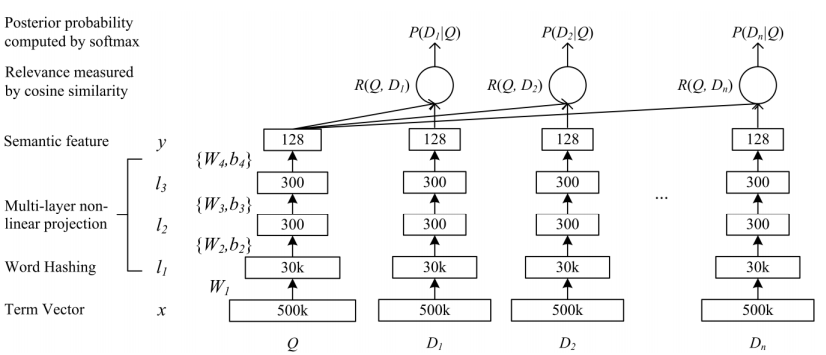
- 把條目對映成低維向量。
- 計算查詢和文件的cosine相似度。
其中:
l1=W1xl1=W1xli=f(Wili−1+bi),i=2word hashing
通過word hashing層將word對映為稠密向量。以good為例。
- 新增首尾標記: #good#
- 拆分word為n-grams: #go, goo, ood, od#
- 通過多個小的n-grams的向量表示word。
這種方法即使有新詞出現,也不會出現問題。
DSSM訓練
對於一次搜尋,如果點選了一個文件,認為他們是相關的。對於搜尋查詢集,DSSM去最大化被點選文件D+D+的條件似然概率**。
P(D+|Q)=exp(γR(Q,D+))∑D′∈Dexp(γ其中D是全集,γγ是平滑因子。損失函式自然就是:
L(W,b)=−log∏(Q,D+)P(D+|Q)L(W,b)=−log∏(Q,D+)P(D+|Q)MULTI-VIEW DEEP NEURAL NETWORK
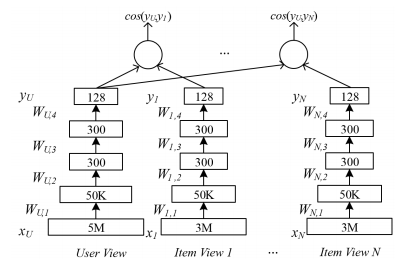
對於User view,計算User View和Item View之間的P(IVi|UV)P(IVi|UV),然後最小化:
L(W,b)=−log∏(UV,IV+)P(IV+i|UV)L(W,b)=−log∏(UV,IV+)P(IVi+|UV)其中P()定義為:
P(IV+|UV)=exp(γcos(UV,IV+))∑IV′∈IVexp(γcos(UV,IV′))P(IV+|UV)=exp(γcos(UV,IV+))∑IV′∈IVexp(γcos(UV,IV′))Data input
對於第j行輸入資料,它的主域Xu,jXu,j和一個啟用View Xa,jXa,j,其餘的View輸入Xi:i≠aXi:i≠a都為0向量。
User features
- search queries:規範化,然後處理成unigram格式。
- clicked URLs:只保留主域名,如www.linkdin.com
News features
news article clicks:
- title( tri-gram)
-
相關推薦
『 論文閱讀』A Multi-View Deep Learning Approach for Cross Domain User Modeling in Recommendation Systems
AbstractMULTI-VIEW-DNN聯合了多個域做的豐富特徵,使用multi-view DNN模型構建推薦,包括app、新聞、電影和TV,相比於最好的演算法,老使用者提升49%,新使用者提升110%。並且可以輕鬆的涵蓋大量使用者,解決冷啟動問題。主要做user embedding的過程,通多使用者在多
『 論文閱讀』Attention-Based Recurrent Neural Network Models for Joint Intent Detection and Slot Filling
來自於論文:《Attention-Based Recurrent Neural Network Models for Joint Intent Detection and Slot Filling》 基於attention的encoder-decoder網
『 論文閱讀』Understanding deep learning requires rethinking generalization
ABSTRACT 雖然其規模巨大,但成功的深層人工神經網路可以獲得訓練和測試集非常小的效能差異。 傳統知識認為這種小的泛化誤差歸功於模型的效能,或者是由於在訓練的時候加入了正則化技術。 通過廣泛的系統實驗,我們展示了這些傳統方法如何不能解釋,而為
『 論文閱讀』LightGBM原理-LightGBM: A Highly Efficient Gradient Boosting Decision Tree
17年8月LightGBM就開源了,那時候就開始嘗試上手,不過更多還是在調參層面,在作者12月論文發表之後看了卻一直沒有總結,這幾天想著一定要翻譯下,自己也梳理下GBDT相關的演算法。 Abstract Gradient Boosting Decision Tr
論文閱讀:A Primer on Neural Network Models for Natural Language Processing(1)
選擇 works embed 負責 距離 feature 結構 tran put 前言 2017.10.2博客園的第一篇文章,Mark。 由於實驗室做的是NLP和醫療相關的內容,因此開始啃NLP這個硬骨頭,希望能學有所成。後續將關註知識圖譜,深度強化學習等內
【論文閱讀】A Closer Look at Spatiotemporal Convolutions for Action Recognition
【論文閱讀】A Closer Look at Spatiotemporal Convolutions for Action Recognition 這是一篇facebook的論文,它和一篇google的論文連結地址的研究內容非常相似,而且幾乎是同一時刻的研究,感覺這兩個公司真的冤家路窄,
論文閱讀:A Survey on Transfer Learning
本文主要內容為論文《A Survey on Transfer Learning》的閱讀筆記,內容和圖片主要參考 該論文 。其中部分內容引用與部落格《遷移學習綜述a survey on transfer learning的整理下載》,感謝博主xf__ma
綜述論文翻譯:A Review on Deep Learning Techniques Applied to Semantic Segmentation
應用於語義分割問題的深度學習技術綜述 摘要 計算機視覺與機器學習研究者對影象語義分割問題越來越感興趣。越來越多的應用場景需要精確且高效的分割技術,如自動駕駛、室內導航、甚至虛擬現實與增強現實等。這個需求與視覺相關的各個領域及應用場景下的深度學習技術的發展相符合,包括語義分割及場景理解等。這篇論文回
Deep learning algorithms for detection of critical findings in head CT scans: a retrospective study
Non-contrast head CT scan is the current standard for initial imaging of patients with head trauma or stroke symptoms. We aimed to develop and validate a s
A Review on Deep Learning Techniques Applied to Semantic Segmentation 論文閱讀
為了以後的學習方便,把幾篇計算機視覺的論文放上來,僅為自己的學習方便。期間有參考了很多部落格和文獻,但是我寫的仍然很粗糙,存在很多的疑問。這篇文章是第一篇有關語義分割的總結,可能大學畢設會用到,暫時先簡單總結一下自己的所得。 大學快要畢業了,開始準備畢設,分割方向逃不了了。提示:排版對手機端
論文閱讀 | DeepDrawing: A Deep Learning Approach to Graph Drawing
作者:Yong Wang, Zhihua Jin, Qianwen Wang, Weiwei Cui, Tengfei Ma and Huamin Qu 本文發表於VIS2019, 來自於香港科技大學的視覺化小組(屈華民教授領導)的研究 1. 簡介 圖資料廣泛用於各個領域,例如生物資訊學,金融和社交網路分析。
論文閱讀 | CrystalBall: A Visual Analytic System for Future Event Discovery and Analysis from Social Media Data
夏洛特 bstr soci 相同 方式 PE VM src 測量 CrystalBall: A Visual Analytic System for Future Event Discovery and Analysis from Social Media Data 論文地
《A Discriminative Feature Learning Approach for Deep Face Recognition》論文筆記
1. 論文思想 在這篇文章中尉人臉識別提出了一種損失函式,叫做center loss,在網路中加入該損失函式之後可以使得網路學習每類特徵的中心,懲罰每類的特徵與中心之間的距離。並且該損失函式是可訓練的,並且在CNN中容易優化。那麼,將center loss與softmax相結合會增加
論文筆記 Memory Fusion Network for Multi-view Sequential Learning (AAAI2018)
這是卡內基梅隆大學與新加坡南洋理工大學在AAAI上發表的一篇利用memory network來處理序列建模的文章。 文章中的multi view其實指代可以很廣泛,許多地方也叫做multi modal,對於多模態序列學習而言,模態往往存在兩種形式的互動(1)模態內關聯(view-sp
SenseGen: A Deep Learning Architecture for Synthetic Sensor Data Generation論文解讀
一、論文概述 SenseGen這篇論文是17年發表在PerCom Workshops上的一篇論文,來自加州大學洛杉磯分校(University of California at Los Aneles,UCLA)網路與嵌入式系統實驗室(Netoworked & Embedded Syste
論文 3DMV: Joint 3D-Multi-View Prediction for 3D Semantic Scene Segmentation
Dataset: ScanNet 獲取方式: 簽署協議書(http://dovahkiin.stanford.edu/scannet-public/ScanNet_TOS.pdf)後傳送至郵箱:[email protected] Data Organization <
【論文閱讀】A Correlated Topic Model Using Word Embeddings
《A Correlated Topic Model Using Word Embeddings》 Abstract 傳統的主題模型能夠通過用邏輯正態分佈代替先驗的Dirichlet來捕捉潛在主題之間的相關結構。word embeddings 已經被證明能夠捕捉語義規律,因此語義相
【論文閱讀】A Neural Probabilistic Language Model
《A Neural Probabilistic Language Model》 Yoshua Bengio 2003 Abstract 統計語言模型建模(Statistical Language Modeling)目標是學習一種語言中單詞序列的聯合概率函式。維度限制會導致:模
【論文閱讀筆記】MULTI-SCALE DENSE NETWORKS FOR RESOURCE EFFICIENT IMAGE CLASSIFICATION
Gao Huang(Cornell University), ICLR 2018 best Papers 文章連結:https://arxiv.org/pdf/1703.09844.pdf 程式碼連結:https://github.com/gaohuang/MSDNet
【論文閱讀】HydraPlus-Net: Attentive Deep Features for Pedestrian Analysis
ase channels 手機 features feature 輸出 傳統 logs evel 轉載請註明出處:https://www.cnblogs.com/White-xzx/ 原文地址:https://arxiv.org/abs/1709.09930 如有不準確或錯