
網絡字節序&大小端存儲
網絡字節序與主機字節序的轉換
在對IP地址結構體SOCKADDR_IN賦值的時候,經常會用到下列的函數htonl,htons,inet_addr,與之相對應的函數是ntohl,ntohs,inet_ntoa。查看這些函數的解析,會發現這些函數其實是與主機字節序和網絡字節序之間轉換有關。就是什麽網絡字節序,什麽是主機字節序呢?下面我寫出他們之間的轉換:
用IP地址127.0.0.1為例:
第一步 127 . 0 . 0 . 1 把IP地址每一部分轉換為8位的二進制數。
第二步 01111111 00000000 00000000 00000001 = 2130706433 (主機字節序)
然後把上面的四部分二進制數從右往左按部分重新排列,那就變為:
第三步 00000001 00000000 00000000 01111111 = 16777343 (網絡字節序)
然後解析上面提到的函數作用就簡單多了,看以下代碼:
SOCKADDR_IN addrSrv;
addrSrv.sin_addr.S_un.S_addr=htonl(2130706433);
addrSrv.sin_family=AF_INET;
addrSrv.sin_port=htons(6000);
先是定義了一個IP地址結構體addrSrv,然後初始化它的IP時addrSrv.sin_addr.S_un.S_addr必須是賦值IP地址的網絡字節序,htonl函數的作用是把一個主機字節序轉換為網絡字節序,也就是上面轉換過程中第二步轉換為第三步的作用,127.0.0.1的主機字節序是2130706433,把主機字節序2130706433轉換為網絡字節序就是htonl(2130706433)=16777343,所以如果你知道網絡字節序是16777343的話,addrSrv.sin_addr.S_un.S_addr=htonl(2130706433);與addrSrv.sin_addr.S_un.S_addr=16777343;是完全一樣的。
addrSrv.sin_addr.S_un.S_addr=htonl(2130706433);這句還可以寫為:
addrSrv.sin_addr.S_un.S_addr=inet_addr("127.0.0.1"); 結果是完全一樣的。
可見inet_addr函數的轉換作用就是上面的第一步到第三步的轉換。
下面再看端口的主機字節序與網絡字節序的轉換。以6000端口為例。
第一步 00010111 01110000 = 6000 (主機字節序)
端口號其實就已經是主機字節序了,首先要把端口號寫為16位的二進制數,分前8位和後8位。
第二步 01110000 00010111 = 28695 (網絡字節序)
然後把主機字節序的前八位與後八位調換位置組成新的16位二進制數,這新的16位二進制數就是網絡字節序的二進制表示了。
因此,如果你知道6000端口的網絡字節序是28695的話。 addrSrv.sin_port=htons(6000);可以直接寫為 addrSrv.sin_port=28695;結果是一樣的,htons的作用就是把端口號主機字節序轉換為網絡字節序。
與htonl,htons,inet_addr,與之相對應的函數是ntohl,ntohs,inet_ntoa,不難看出,ntohl,ntohs,inet_ntoa,這三個函數其實就是執行與他們相對應函數的相反轉換,在這裏就不詳細解析了。
端口port:: ntohs() //網絡字節序轉主機字節序 ntohl() htons() //主機字節序轉網絡字節序 htonl() IP轉換:: inet_aton //將字符串ip轉換成無符號長整型,並轉換成網絡字節序 inet_addr("*.*.*.*") //將字符串ip轉換成無符號長整型(unsigned long int),並轉換成網絡字節序。 inet_htoa(addr.sin_addr.s_addr); //將網絡字節序的ip轉換成"*.*.*.*"形式。 inet_pton //將點分十進制數ip地址轉換陳32位二進制網絡地址 inet_ntop //將32為二進制ip地址轉換為點分十進制ip地址
原文地址:http://blog.csdn.net/u012317833/article/details/39429095
----------------------------------------------------------------------------------------------------------------------------------
一、在進行網絡通信時是否需要進行字節序轉換?
相同字節序的平臺在進行網絡通信時可以不進行字節序轉換,但是跨平臺進行網絡數據通信時必須進行字節序轉換。 原因如下:網絡協議規定接收到得第一個字節是高字節,存放到低地址,所以發送時會首先去低地址取數據的高字節。小端模式的多字節數據在存放時,低地址存放的是低字節,而被發送方網絡協議函數發送時會首先去低地址取數據(想要取高字節,真正取得是低字節),接收方網絡協議函數接收時會將接收到的第一個字節存放到低地址(想要接收高字節,真正接收的是低字節),所以最後雙方都正確的收發了數據。而相同平臺進行通信時,如果雙方都進行轉換最後雖然能夠正確收發數據,但是所做的轉換是沒有意義的,造成資源的浪費。而不同平臺進行通信時必須進行轉換,不轉換會造成錯誤的收發數據,字節序轉換函數會根據當前平臺的存儲模式做出相應正確的轉換,如果當前平臺是大端,則直接返回不進行轉換,如果當前平臺是小端,會將接收到得網絡字節序進行轉換。二、大端和小端
"大端"和"小端"表示多字節值的哪一端存儲在該值的起始地址處;小端存儲在起始地址處,即是小端字節序;大端存儲在起始地址處,即是大端字節序; 或者說: 1.小端法(Little-Endian)就是低位字節排放在內存的低地址端(即該值的起始地址),高位字節排放在內存的高地址端; 2.大端法(Big-Endian)就是高位字節排放在內存的低地址端(即該值的起始地址),低位字節排放在內存的高地址端; 舉個簡單的例子,對於整型數據0x12345678,它在大端法和小端法的系統中,各自的存放方式如下圖1所示:
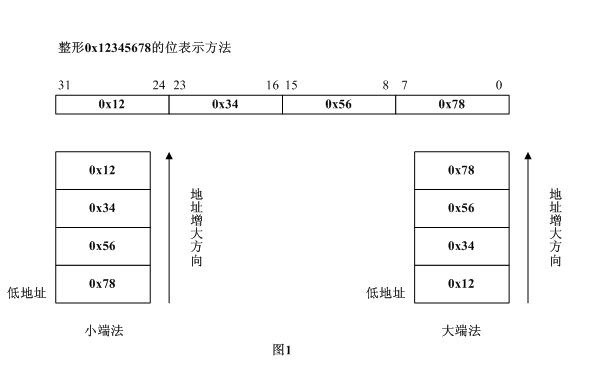
三、網絡字節序
網絡上傳輸的數據都是字節流,對於一個多字節數值,在進行網絡傳輸的時候,先傳遞哪個字節?也就是說,當接收端收到第一個字節的時候,它將這個字節作為高位字節還是低位字節處理,是一個比較有意義的問題; UDP/TCP/IP協議規定:把接收到的第一個字節當作高位字節看待,這就要求發送端發送的第一個字節是高位字節;而在發送端發送數據時,發送的第一個字節是該數值在內存中的起始地址處對應的那個字節,也就是說,該數值在內存中的起始地址處對應的那個字節就是要發送的第一個高位字節(即:高位字節存放在低地址處);由此可見,多字節數值在發送之前,在內存中因該是以大端法存放的; 所以說,網絡字節序是大端字節序; 比如,我們經過網絡發送整型數值0x12345678時,在80X86平臺中,它是以小端發存放的,在發送之前需要使用系統提供的字節序轉換函數htonl()將其轉換成大端法存放的數值;如下圖2所示: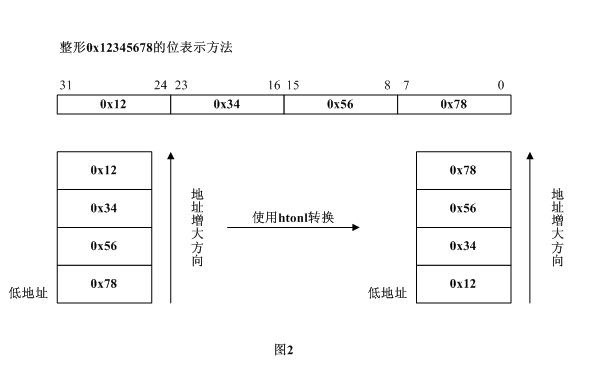 原文地址:http://www.cnblogs.com/fuchongjundream/p/3914770.html
原文地址:http://www.cnblogs.com/fuchongjundream/p/3914770.html
網絡字節序&大小端存儲