
多位元組整數字節序(小端/大端)
《UNIX Network Programming Volume1: The Socket Networking API, Third Edition》
W.Richard Stevens / Bill Fenner / Andrew M.Rudoff
考慮記憶體中儲存一個16位整數,它由2個位元組組成,因此儲存這兩個位元組有兩種方法:
- 小端位元組序——將低序位元組儲存在起始地址;
- 大端位元組序——將高序位元組儲存在起始地址。
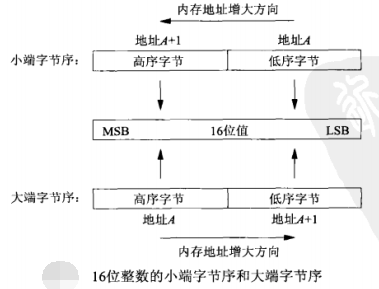
MSB(most significant bit,最高有效位):是這個16位值最左邊一位; LSB(least significant bit,最低有效位):是這個16位值最右邊一位。
- 主機位元組序:某個給定系統所用的位元組序。(遺憾的是,這兩種位元組序格式都有系統在使用。)
- 網路位元組序:網際協議規定使用大端位元組序來傳送這些多位元組整數。
(byteorder.c:在一個短整型變數中存放2位元組的值0x0102,然後檢視它的兩個連續位元組c[0]和c[1],以此確定主機位元組序)
#include <stdio.h>
int main(int argc, char **argv) {
union {
short s;
char c[sizeof(short)];
} un;
un.s = 0x0102;
printf 結果(僅限測試主機):
Host byte order: little-endian
相關推薦
多位元組整數字節序(小端/大端)
《UNIX Network Programming Volume1: The Socket Networking API, Third Edition》 W.Richard Stevens
網絡字節序&大小端存儲
img 技術分享 sockaddr 發送數據 top tac sdn 直接 nbsp 網絡字節序與主機字節序的轉換 在對IP地址結構體SOCKADDR_IN賦值的時候,經常會用到下列的函數htonl,htons,inet_addr,與之相對應的函數是ntohl,ntohs,
多執行緒佇列演算法優化(雙端佇列)(一
多執行緒佇列(Concurrent Queue)的使用場合非常多,高效能伺服器中的訊息佇列,並行演算法中的Work Stealing等都離不開它。對於一個佇列來說有兩個最主要的動作:新增(enqueue)和刪除(dequeue)節點。在一個(或多個)執行緒在對一個佇列進
大端 小端和網絡字節序說明
body 地址 eve powerpc tcp ron 轉換成 字節流 n) 不同CPU存放數據有大端(Big-Endian)和小端(little-Endian)之分 小端字節序和大端字節序表示存儲的字節順序有區別 小端字節序:低字節存於內存低地址;高字節存於內存高地址;
ZZULIOJ. 1111: 多個整數的逆序輸出(函式專題)
1111: 多個整數的逆序輸出(函式專題) 題目描述 輸入n和n個整數,以與輸入順序相反的順序輸出這n個整數。要求不使用陣列,而使用遞迴函式實現。 遞迴函式實現過程如下: void inverse(int n) { if(n >1) { (1) 讀入一個整數,存入num;
1111: 多個整數的逆序輸出(函式專題)
輸入n和n個整數,以與輸入順序相反的順序輸出這n個整數。要求不使用陣列,而使用遞迴函式實現。 遞迴函式實現過程如下: void inverse(int n) { if(n >1) { (1) 讀入一個整數,存入num; (2) 將後面的n-1個數逆序輸出
大端位元組序和小端位元組序問題(big-endian & little-endian)
所謂的大端模式(Big-endian),是指資料的低位(就是權值較小的後面那幾位)儲存在記憶體的高地址中,而資料的高位,儲存在記憶體的低地址中,這樣的儲存模式有點兒類似於把資料當作字串順序處理:地址由小向大增加,而資料從高位往低位放; 所謂的小端模式(Little-endian
3693 求這串字元中的重複次數最多的連續重複子串,多組答案輸出字典序最小的那個串(字尾陣列)
題目:求這串字元中的重複次數最多的連續重複子串,多組答案輸出字典序最小的那個串。 思路:與前一個題目幾乎一樣的,加上了字典序。多判斷就好 //#include<bits/stdc++.h> #include<iostream> #include
刨根究底字符編碼之九——字符編碼方案的演變與字節序
不同 桌面應用 提示 編碼方式 power 同時 建議 travel n) 字符編碼方案的演變與字節序 一、字符編碼方案的演變 1. 前文已經提及,編號字符集CCS(簡稱字符集)與字符編碼方式CEF(簡稱編碼方式)這兩個概念,在早期並沒有必要嚴格區分。 在Unico
刨根究底字符編碼之十一——UTF-8編碼方式與字節序標記
所有 碼元 unix 找到 概念 不可見 執行 大端 位置 UTF-8編碼方式與字節序標記 一、UTF-8編碼方式 1. 接下來將分別介紹Unicode字符集的三種編碼方式:UTF-8、UTF-16、UTF-32。這裏先介紹應用最為廣泛的UTF-8。 為滿足基於AS
Linux網絡編程--字節序
-c bits 小端 %x 打印 string include 變量類型 pre 1 .談到字節序,那麽會有朋友問什麽是字節序 非常easy:【比如一個16位的整數。由2個字節組成,8位為一字節,有的系統會將高字節放在內存低的地址上,有的則將低字節
網絡字節序
big 寫入 好的 實現 問題 style 但是 不同的 .so 轉自:http://blog.sina.com.cn/s/blog_4b5039210100f2a0.html 在C中關於網絡字節序和主機字節序困擾了我一段時間,在python中實現字節流的網絡傳輸,必然這個
主機字節序和網絡字節序轉換
數據表 https www sch 定義 本地 style tails art 為什麽要轉換? 主機字節序:整數在內存中保存的順序,不同的處理器對應不容的模式 Little endian 將低序字節存儲在起始地址 Big endian 將高序字節存儲在起始地址 網
判斷主機、網絡字節序和互相轉換
9.1 判斷 gpo 位數 signed 轉換 pad bsp amp 大端字節序(big-endian):按照內存地址的增長方向,高位數據儲存於低位地址。 小端字節序(little-endian):按照內存地址增長方向,高位數據儲存於高位地址。 判斷主機、網絡字節序:
如何查看.java文件的字節碼(原碼)
數據 int new compile from auto 進行 java public 出自於:https://www.cnblogs.com/tomasman/p/6751751.html 直接了解foreach底層有些困難,我們需要從更簡單的例子著手.下面上一個簡單
java 識別字符串中字節數(中文占兩個字節,英文占一個)
else if gpo pub div 字節 str length 英文 兩個 public static int byteNum(String str) { int m = 0; char arr[] =
字節序
字節序 大小端 大端字節序 小端字節序 網絡字節序 字節序是說整型數字在內存地址中存儲的順序,分為大端字節序、小端字節序兩種:* 大端字節序: 最高有效位存儲於最低地址位,最低有效位存儲於高地址位,既存儲順序與所見順序相同* 小端字節序: 最高有效位存儲於最高地址位,最低有效位存儲於最低地
htons、htonl與字節序大小端
col pre pri color main spa 16bit ets sts 判斷字節序大小端code #include <stdio.h> int main() { if (htons(1) == 1) printf("big
字節序的理解----C語言和Python語言
code n) name mes net oid unsigned import 應該 字節序是指多字節數據在計算機內存中存儲或者網絡傳輸時各字節的存儲順序。常見的主要有以下2種: 小端序(Little-Endian):低位字節排放在內存的低地址端即該值的起始地址,高位字
python字節碼(轉)
三種 sts 變量 原始的 解釋 復制代碼 bject ria james 了解 Python 字節碼是什麽,Python 如何使用它來執行你的代碼,以及知道它是如何幫到你的。 如果你曾經編寫過 Python,或者只是使用過 Python,你或許經常會看到 Python