
Hadoop(一)之初識大數據與Hadoop【轉載】
原文地址:http://www.cnblogs.com/zhangyinhua/p/7647334.html
閱讀目錄(Content)
- 一、引言(大數據時代)
- 1.1、從數據中得到信息
- 1.2、大數據表象概念
- 二、大數據基礎
- 2.1、什麽是大數據?
- 2.2、大數據的基本特征
- 2.3、大數據的意義
- 2.4、大數據的系統架構(整體架構)
- 2.5、大數據處理平臺
- 2.6、大數據中的幾個概念
- 三、Hadoop概述
- 3.1、什麽是Hadoop
- 3.2、Hadoop的優點
- 3.3、Hadoop發展歷程
- 3.4、Hadoop生態圈
前言
從今天起,我將一步一步的分享大數據相關的知識,其實很多程序員感覺大數據很難學,其實並不是你想象的這樣,只要自己想學,還有什麽難得呢?
學習Hadoop有一個8020原則,80%都是在不斷的配置配置搭建集群,只有20%寫程序!
回到頂部(go to top)一、引言(大數據時代)
1.1、從數據中得到信息
我們看一張圖片:

我們知道這個圖片上的人叫張小妹,年齡20歲,職業模特。但是如果只有數據沒有圖片的話,就沒有意義的數據了。所以數據一定是在特定的環境下才有意義的。
我們再來看一張圖片:
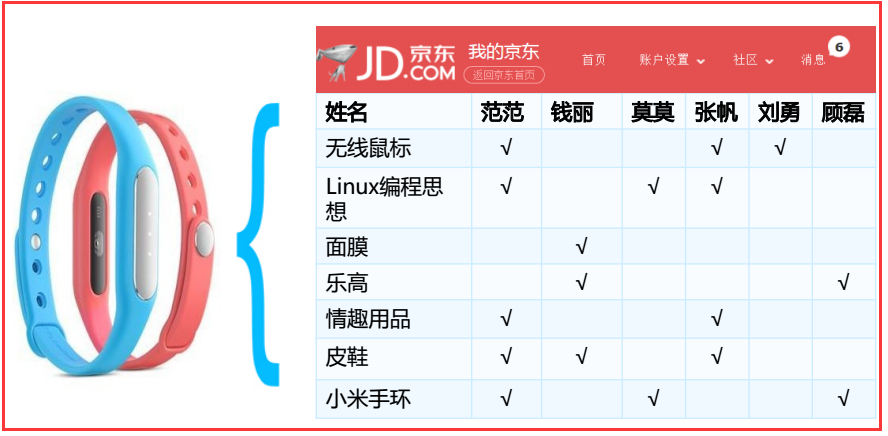
從這張圖片分析出:從縱向分析,範範和張帆的購買東西十分的相似,所以如果要推薦東西給張帆的話,我們就可以選擇小米手環。
從橫向分析,無效鼠標,linux編程思想,皮鞋和小米手環都賣的比較火,其他幾樣銷量少,所以我們推薦就可以把這幾樣放上去。
1.2、大數據表象概念
大家理解什麽是大數據嗎,那大數據到底有多大!我們就以百度的數據來分析一下:

首先:1PB=1024T
分析:我們就看最小的它每天產生的日誌就可以看出來,百度每天要產生100TB~1PB的日誌數據。一般我們電腦的硬盤是1T的。那就需要電腦的100個硬盤到1024塊硬盤,你想想是多麽的恐怖!
回到頂部(go to top)二、大數據基礎
2.1、什麽是大數據?
其實對於大數據官方並沒有給出一個準確的定義,不同機構有著不同的定義。
1)對於“大數據”(Big data)研究機構 Gartner 給出了這樣的定義。“大數據”是需要新處理模式才能具有更強的決策力、洞察發現力和流程優化能力來適應海量、高增長率和多樣化的信息資產。
2)麥肯錫全球研究所給出的定義是:一種規模大到在獲取、存儲、管理、分析方面大大超出了傳統數據庫軟件工具能力範圍的數據集合,具有海量的數據規模、快速的數據流轉、多樣的數據類型和價值密度低四大特征。
3)大數據技術的戰略意義不在於掌握龐大的數據信息,而在於對這些含有意義的數據進行專業化處理。換而言之,
如果把大數據比作一種產業,那麽這種產業實現盈利的關鍵,在於提高對數據的“加工能力”,通過“加工”實現數據的“增值”。
4) 從技術上看,大數據與雲計算的關系就像一枚硬幣的正反面一樣密不可分。大數據必然無法用單臺的計算機進行處
理,必須采用分布式架構。它的特色在於對海量數據進行分布式數據挖掘。但它必須依托雲計算的分布式處理、分布式數據庫和雲存儲、虛擬化技術。
5)隨著雲時代的來臨,大數據(Big data)也吸引了越來越多的關註。分析師團隊認為,大數據(Big data)通常用來形容一個公司創造的大量非結構化數據和半結構化數據,
這些數據在下載到關系型數據庫用於分析時會花費過多時間和金錢。大數據分析常和雲計算聯系到一起,因為實時的大型數據集分析需要像 MapReduce 一樣的框架來向數十、數百或甚至數千的電腦分配工作。
6) 大數據需要特殊的技術,以有效地處理大量的容忍經過時間內的數據。適用於大數據的技術,包括大規模並行處理(MPP)數據庫、數據挖掘、分布式文件系統、分布式數據庫、雲計算平臺、互聯網和可擴展的存儲系統。
7)谷歌給出的大數據定義和特點
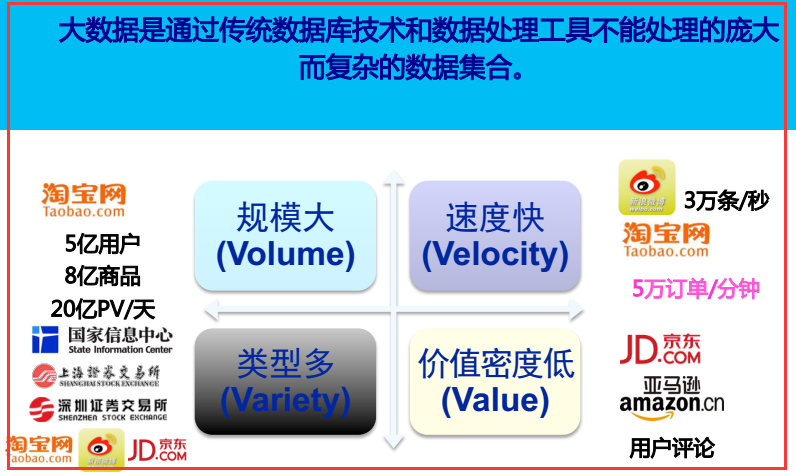
2.2、大數據的基本特征
容量(Volume):數據的大小決定所考慮的數據的價值和潛在的信息
種類(Variety):數據類型的多樣性
速度(Velocity):指獲得數據的速度
可變性(Variability):妨礙了處理和有效地管理數據的過程
真實性(Veracity):數據的質量
復雜性(Complexity):數據量巨大,來源多渠道
價值(Value):合理運用大數據,以低成本創造高價值
2.3、大數據的意義
1)現在的社會是一個高速發展的社會,科技發達,信息流通,人們之間的交流越來越密切,生活也越來越方便,大數據就是這個高科技時代的產物。
阿裏巴巴創辦人馬雲來臺演講中就提到,未來的時代將不是 IT 時代,而是 DT 的時代,DT 就是 Data Technology 數據科技,顯示大數據對於阿裏巴巴集團來說舉足輕重。
2)有人把數據比喻為蘊藏能量的煤礦。煤炭按照性質有焦煤、無煙煤、肥煤、貧煤等分類,而露天煤礦、深山煤礦的挖掘成本又不一樣。與此類似,大數據並不在“大”,而在於“有用”。
價值含量、挖掘成本比數量更為重要。對於很多行業而言, 如何利用這些大規模數據是贏得競爭的關鍵。
3)大數據的價值體現在以下幾個方面:
對大量消費者提供產品或服務的企業可以利用大數據進行精準營銷
做小而美模式的中小微企業可以利用大數據做服務轉型
面臨互聯網壓力之下必須轉型的傳統企業需要與時俱進充分利用大數據的價值
4)不過,“大數據”在經濟發展中的巨大意義並不代表其能取代一切對於社會問題的理性思考,科學發展的邏輯不能被湮沒在海量數據中。
著名經濟學家路德維希·馮·米塞斯曾提醒過:“就今日言,有很多人忙碌於資料之無益累積,以致對問題之說明與解決,喪失了其對特殊的經濟意義的了解。”這確實是需要警惕的。
5)在這個快速發展的智能硬件時代,困擾應用開發者的一個重要問題就是如何在功率、覆蓋範圍、傳輸速率和成本之間找到那個微妙的平衡點。
企業組織利用相關數據和分析可以幫助它們降低成本、提高效率、開發新產品、做出更明智的業務決策等等。
例如,通過結合大數據和高性能的分析,下面這些對企業有益的情況都可能會發生:
及時解析故障、問題和缺陷的根源,每年可能為企業節省數十億美元。
為成千上萬的快遞車輛規劃實時交通路線,躲避擁堵。
根據客戶的購買習慣,為其推送他可能感興趣的優惠信息。
從大量客戶中快速識別出金牌客戶。
使用點擊流分析和數據挖掘來規避欺詐行為。
2.4、大數據的系統架構(整體架構)
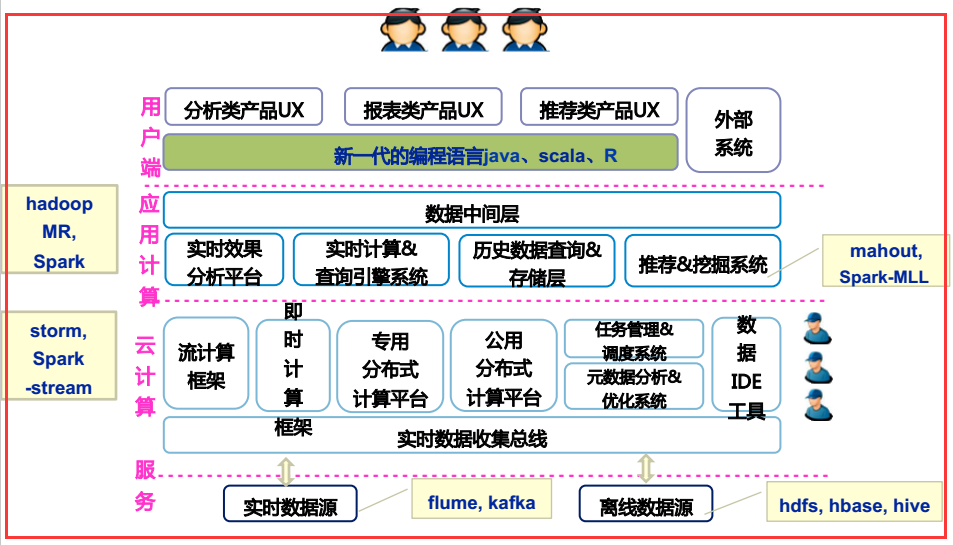
2.5、大數據處理平臺

2.6、大數據中的幾個概念
1)集群(Cluster):服務器集群就是指將很多服務器集中起來一起進行同一種服務,在客戶端看來就像是只有一個服務器。集群可以利用多個計算機進行並行 計算從而獲得很高的計算速度,也可以用多個計算機做備份,
從而使得任何一個機器壞了整個系統還是能正常運行。(通俗來說就是由若幹計算機組成的,共同協作來完成一個大型復雜計算任務的計算機群體。 )
2)數據密集型(DIC):在集群中所計算的數據的量比較大,但是計算過程並不復雜。
3)計算密集型(CIC):數據量並不大,但是計算過程是比較復雜的。
4)向上擴展(Scale-up):對硬件的擴展。受限於硬件的發展。其實就是對cpu、內存、硬盤的擴展
5)向外擴展(Scale-out):通過計算機集群的方式來提高計算能力。 (例如當某個計算任務用 10 臺計算機不能完成時就增加計算機臺數來完成)。受限於網絡資源。其實就是對服務器個數的擴展
6)機器學習(MachineLearning):當數據被處理完,用來獲取所處理的信息。從數據集中獲取信息。
7)雲計算(CloudComputing):通過互聯網來提供動態易擴展且經常是虛擬化的資源
三、Hadoop概述
3.1、什麽是Hadoop
1)Hadoop 是一個由 Apache 基金會所開發的分布式系統基礎架構。
2)用戶可以在不了解分布式底層細節的情況下,開發分布式程序。充分利用集群的威力進行高速運算和存儲。
3)Hadoop 實現了一個分布式文件系統(Hadoop Distributed File System),簡稱 HDFS。 HDFS 有高容錯性的特點,並且設計用來部署在低廉的(low-cost)硬件上;
而且它提供高吞吐量(high throughput)來訪問應用程序的數據,適合那些有著超大數據集(large data set)的應用程序。
HDFS 放寬了(relax) POSIX 的要求,可以以流的形式訪問(streaming access)文件系統中的數據。
4)Hadoop 的框架最核心的設計就是: HDFS 和 MapReduce。 HDFS 為海量的數據提供了存儲,則 MapReduce 為海量的數據提供了計算。
3.2、Hadoop的優點
1)Hadoop 是一個能夠對大量數據進行分布式處理的軟件框架。
2) Hadoop 以一種可靠、高效、可伸縮的方式進行數據處理。
3)Hadoop 是可靠的,因為它假設計算元素和存儲會失敗,因此它維護多個工作數據副本,確保能夠針對失敗的節點重新分布處理。
4)Hadoop 是高效的,因為它以並行的方式工作,通過並行處理加快處理速度。
5)Hadoop 還是可伸縮的,能夠處理 PB 級數據。
6)Hadoop 依賴於社區服務,因此它的成本比較低,任何人都可以使用。
7)Hadoop是一個能夠讓用戶輕松架構和使用的分布式計算平臺。用戶可以輕松地在Hadoop上開發和運行處理海量數據的應用程序。它主要有以下幾個優點:
高可靠性:Hadoop 按位存儲和處理數據的能力值得人們信賴
高擴展性:Hadoop是在可用的計算機集簇間分配數據並完成計算任務的,這些集簇可以方便地擴展到數以千計的節點中。
高效性:Hadoop 能夠在節點之間動態地移動數據,並保證各個節點的動態平衡,因此處理速度非常快
高容錯性:Hadoop 能夠自動保存數據的多個副本,並且能夠自動將失敗的任務重新分配
低成本:與一體機、商用數據倉庫以及 QlikView、 Yonghong Z-Suite 等數據集市相比, hadoop 是開源的,項目的軟件成本因此會大大降低。
8)Hadoop 帶有用 Java 語言編寫的框架,因此運行在 Linux 生產平臺上是非常理想的。 Hadoop 上的應用程序也可以使用其他語言編寫,比如 C++。
3.3、Hadoop發展歷程
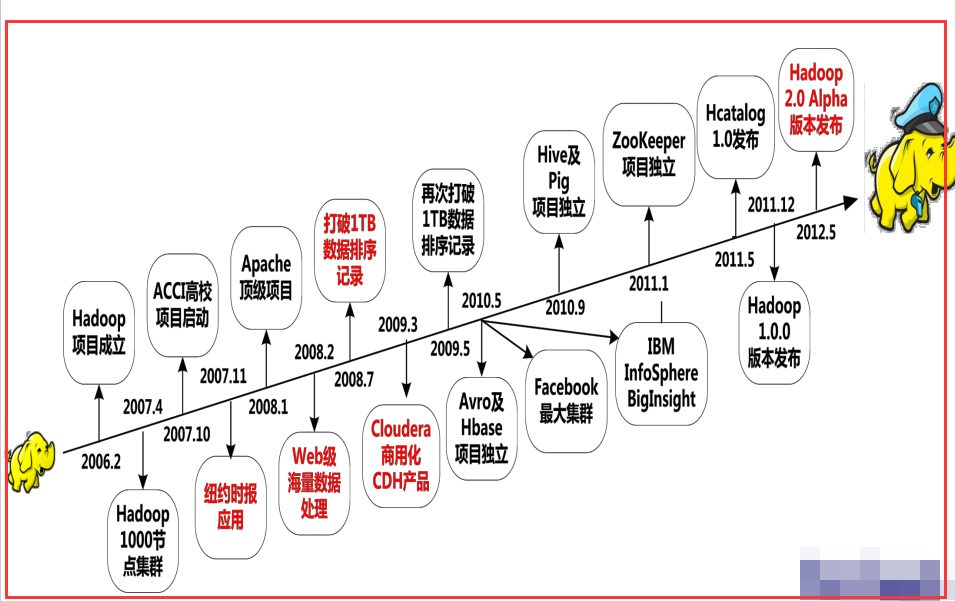
3.4、Hadoop生態圈
經過幾年的發展,Hadoop已經發展成包含多個相關項目的軟件生態系統。(也就是說Hadoop包含著許多的子項目)
1)狹義的Hadoop
核心項目:
Hadoop Common: 在 0.20 及以前的版本中,包含 HDFS、 MapReduce 和其他項目公共內容,從 0.21 開始 HDFS和 MapReduce 被分離為獨立的子項目,其余內容為 Hadoop Common
為Hadoop其他項目提供一些常用工具,如系統配置工具Configuration、遠程過程調用RPC序列化機制、Had抽象文件系統FileSystem等。
HDFS: Hadoop 分布式文件系統(Distributed File System),運行大型商用機集群,是Hadoop體系中海量數據儲存管理的基礎。
MapReduce: 並行計算框架, 0.20 前使用 org.apache.hadoop.mapred 舊接口, 0.20 版本開始引入 org.apache.hadoop.mapreduce 的新 API。
分布式數據處理模型和執行環境,是Hadoop體系中海量數據處理的基礎。
2)廣義的Hadoop
核心項目+其他項目(Avro、Zppkeeper、Hive、Pig、Hbase等):
上面為基礎,面向具體領域或應用的項目有:mahout、X-Rime、Crissbow、lvory等
數據交換、工作流等外圍支撐系統:Chukwa、Flume、Sqoop、Oozie

子項目:
Hbase:

Zookeeper:

Apache Pig:

Apache Hive:

Apache Flume:

Apache sqoop:

Mahout:

Ambari:

原文地址:http://www.cnblogs.com/zhangyinhua/p/7647334.html
Hadoop(一)之初識大數據與Hadoop【轉載】