
字符串模式匹配算法 BM
BM算法最好情況下的時間復雜度是O(n),KMP算法最好情況下的時間復雜度是O(n+m),兩者最壞情況下的時間復雜度均是O(m·n)。其中,n指目標串長度,m指模式串長度。BM算法是比KMP算法更快的字符串模式匹配算法。
KMP算法從左向右比較,通過失配時已匹配的字符信息來確定下一次匹配時模式串的起始位置。BM算法從右向左比較,運用了兩種啟發式規則:壞字符規則和好後綴規則,取這兩種規則的跳躍距離大者作為P向右跳躍的距離。
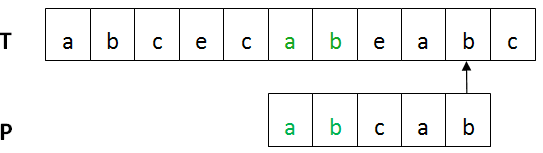
BM算法的基本流程:設目標串T,模式串為P。首先將T與P進行左對齊,然後進行從右向左比較 ,如下圖所示:
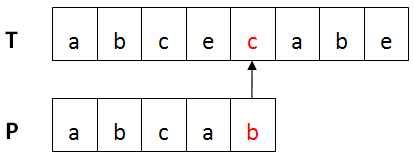
某趟比較不匹配時,通過壞字符規則和好後綴規則來計算模式串向右移動的距離,直到整個匹配過程的結束。
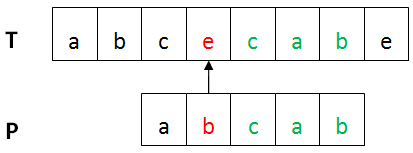
上圖中,第一個不匹配的字符(紅色部分)是壞字符,已匹配部分(綠色)是好後綴。
壞字符(Bad Character)規則:
出現某個字符x不匹配時,分如下兩種情況討論:
1 如果x在P中沒有出現,則從x開始的m個字符不可能與P匹配成功,所以直接跳過該區域。
2 如果x在P中出現,則以該字符為基準右對齊。
設skip(x)是P右移的距離,max(x)是x在P中最右位置,用數學公式表示如下:
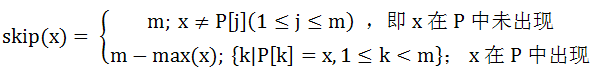
舉例:
下圖紅色部分出現不匹配。
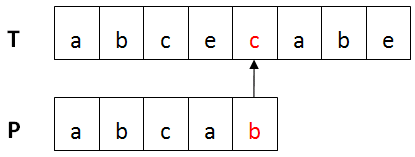
移動距離skip(c) = 5 - 3 = 2,則P向右移動2位。
移動後如下圖:
好後綴(Good Suffix)規則:
出現某個字符x不匹配時,如果已有部分字符匹配,則分如下兩種情況討論:
1 如果在P中位置t已匹配部分P‘在P中的某位置t‘也出現了,並且位置t‘的前一個字符與位置t的前一個字符不相同,則將t‘右移到t的位置。
2 如果已匹配部分P‘在P中的任何位置都沒有再出現,則找到與P‘的後綴P‘‘相同的在P中的最長前綴出現的位置x,將x右移到P‘‘後綴所在的位置。
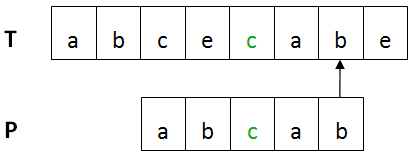
設Shift(j)是P右移的距離,j 是當前匹配的字符位置,s是t‘與t的距離或者x與P‘‘的距離,用數學公式表示如下:
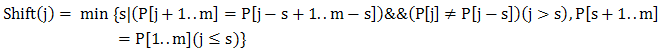
舉例:
下圖中,已匹配部分cab(綠色)在P中再沒出現。
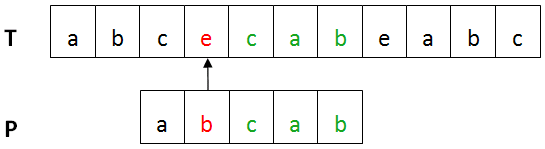
再看下圖,已匹配部分P‘中後綴T‘(藍色)與P中最長前綴P‘‘(紅色)匹配,則將P‘移動到T‘的位置。
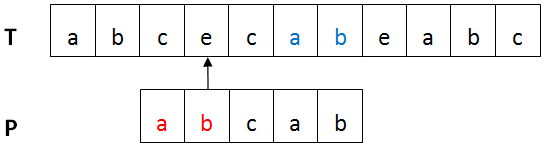
移動後如下圖:
取skip(x)與Shift(j)中的較大者作為跳躍的距離。
C語言代碼
1 /* 2 函數:int* MakeSkip(char *, int) 3 目的:根據壞字符規則做預處理,建立一張壞字符表 4 參數: 5 ptrn => 模式串P 6 PLen => 模式串P長度 7 返回: 8 int* - 壞字符表 9 */ 10 int* MakeSkip(char *ptrn, int pLen) 11 { 12 int i; 13 //為建立壞字符表,申請256個int的空間 14 /*PS:之所以要申請256個,是因為一個字符是8位, 15 所以字符可能有2的8次方即256種不同情況*/ 16 int *skip = (int*)malloc(256*sizeof(int)); 17 18 if(skip == NULL) 19 { 20 fprintf(stderr, "malloc failed!"); 21 return 0; 22 } 23 24 //初始化壞字符表,256個單元全部初始化為pLen 25 for(i = 0; i < 256; i++) 26 { 27 *(skip+i) = pLen; 28 } 29 30 //給表中需要賦值的單元賦值,不在模式串中出現的字符就不用再賦值了 31 while(pLen != 0) 32 { 33 *(skip+(unsigned char)*ptrn++) = pLen--; 34 } 35 36 return skip; 37 } 38 39 40 /* 41 函數:int* MakeShift(char *, int) 42 目的:根據好後綴規則做預處理,建立一張好後綴表 43 參數: 44 ptrn => 模式串P 45 PLen => 模式串P長度 46 返回: 47 int* - 好後綴表 48 */ 49 int* MakeShift(char* ptrn,int pLen) 50 { 51 //為好後綴表申請pLen個int的空間 52 int *shift = (int*)malloc(pLen*sizeof(int)); 53 int *sptr = shift + pLen - 1;//方便給好後綴表進行賦值的指標 54 char *pptr = ptrn + pLen - 1;//記錄好後綴表邊界位置的指標 55 char c; 56 57 if(shift == NULL) 58 { 59 fprintf(stderr,"malloc failed!"); 60 return 0; 61 } 62 63 c = *(ptrn + pLen - 1);//保存模式串中最後一個字符,因為要反復用到它 64 65 *sptr = 1;//以最後一個字符為邊界時,確定移動1的距離 66 67 pptr--;//邊界移動到倒數第二個字符(這句是我自己加上去的,因為我總覺得不加上去會有BUG,大家試試“abcdd”的情況,即末尾兩位重復的情況) 68 69 while(sptr-- != shift)//該最外層循環完成給好後綴表中每一個單元進行賦值的工作 70 { 71 char *p1 = ptrn + pLen - 2, *p2,*p3; 72 73 //該do...while循環完成以當前pptr所指的字符為邊界時,要移動的距離 74 do{ 75 while(p1 >= ptrn && *p1-- != c);//該空循環,尋找與最後一個字符c匹配的字符所指向的位置 76 77 p2 = ptrn + pLen - 2; 78 p3 = p1; 79 80 while(p3 >= ptrn && *p3-- == *p2-- && p2 >= pptr);//該空循環,判斷在邊界內字符匹配到了什麽位置 81 82 }while(p3 >= ptrn && p2 >= pptr); 83 84 *sptr = shift + pLen - sptr + p2 - p3;//保存好後綴表中,以pptr所在字符為邊界時,要移動的位置 85 /* 86 PS:在這裏我要聲明一句,*sptr = (shift + pLen - sptr) + p2 - p3; 87 大家看被我用括號括起來的部分,如果只需要計算字符串移動的距離,那麽括號中的那部分是不需要的。 88 因為在字符串自左向右做匹配的時候,指標是一直向左移的,這裏*sptr保存的內容,實際是指標要移動 89 距離,而不是字符串移動的距離。我想SNORT是出於性能上的考慮,才這麽做的。 90 */ 91 92 pptr--;//邊界繼續向前移動 93 } 94 95 return shift; 96 } 97 98 99 /* 100 函數:int* BMSearch(char *, int , char *, int, int *, int *) 101 目的:判斷文本串T中是否包含模式串P 102 參數: 103 buf => 文本串T 104 blen => 文本串T長度 105 ptrn => 模式串P 106 PLen => 模式串P長度 107 skip => 壞字符表 108 shift => 好後綴表 109 返回: 110 int - 1表示成功(文本串包含模式串),0表示失敗(文本串不包含模式串)。 111 */ 112 int BMSearch(char *buf, int blen, char *ptrn, int plen, int *skip, int *shift) 113 { 114 int b_idx = plen; 115 if (plen == 0) 116 return 1; 117 while (b_idx <= blen)//計算字符串是否匹配到了盡頭 118 { 119 int p_idx = plen, skip_stride, shift_stride; 120 while (buf[--b_idx] == ptrn[--p_idx])//開始匹配 121 { 122 if (b_idx < 0) 123 return 0; 124 if (p_idx == 0) 125 { 126 return 1; 127 } 128 } 129 skip_stride = skip[(unsigned char)buf[b_idx]];//根據壞字符規則計算跳躍的距離 130 shift_stride = shift[p_idx];//根據好後綴規則計算跳躍的距離 131 b_idx += (skip_stride > shift_stride) ? skip_stride : shift_stride;//取大者 132 } 133 return 0; 134 }
參考資料
字符串模式匹配的BM算法
【模式匹配】更快的Boyer-Moore算法
字符串模式匹配算法 BM