
ELK系列~對fluentd參數的理解
這段時候一直在研究ELK框架,主要集成在對fluentd和nxlog的研究上,國內文章不多,主要看了一下官方的API,配合自己的理解,總結了一下,希望可以幫到剛入行的朋友們!
Fluentd(日誌收集與過濾,server)
Fluentd是一個免費,而且完全開源的日誌管理工具,簡化了日誌的收集、處理、和存儲,你可以不需要在維護編寫特殊的日誌處理腳本。Fluentd的性能已經在各領域得到了證明:目前最大的用戶從5000+服務器收集日誌,每天5TB的數據量,在高峰時間處理50,000條信息每秒。它可以在客戶端和服務端分別部署,客戶端收集日誌輸出到服務端。 fluentd的工作由它的配置文件決定,我們可以設置它的類型,格式,端口,綁定主機,tag標簽等。<source> @type tcp tag pilipa format none port 24224 bind 0.0.0.0 </source> <filter docker.**> type parser format json time_format %Y-%m-%dT%H:%M:%S.%L%Z key_name log reserve_data true </filter> <match **> @type stdout</match> </ROOT>
Source節點
source主要是配置一個TCP,格式為所有,端口為默認的24224,綁定主機為自己IP的服務,它對應的客戶端就要是TCP的,我們的nxlog就是這種協議的,架構上說就是一個c/s結構,由nxlog負責把數據發到fluentd上面。
filter節點
filter就是過濾規則,當source.tag復合filter的規則時,就執行這個filter進行過濾行為
match是fluentd收到數據後的處理, @type stdout是指在控制臺輸出,而我們生產環境把它輸出到了elasticsearch上面( @type elasticsearch),處理的格式是json,如果在進行parser.json失敗後,數據就不會正常的寫入指定的數據表了,當然你可以把異常的數據存儲到elasticsearch的其它表裏。
自己在實踐中總結的地方:
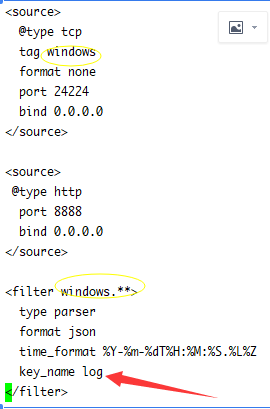
source裏類型為@tcp類型時,它的tag是很重要的,我們的程序需要提供這個tag,當然如果你指定了端口,那這個tag就是當前端口的,而filter要根據這個tag去匹配自己,比如windows的tag,它會找以windows開頭的fitler。
filter裏的key_name,對應客戶端發送消息時的主屬性名稱,有的是log,有的是message,有的是msg,像nxlog這種客戶端它在使用tcp時key)name是message,下面說幾種情況:
1 匹配了filter但沒有找到key_name會有下面提示

2 沒有任務key_name,會在結尾出現\r符號,我們需要去自己在output裏過濾它,否則json轉換失敗

3 找到了對應的key_name
 4 fluentd.conf配置註意點:
4 fluentd.conf配置註意點:
感謝各位的閱讀!
希望本文章可以幫您快速的解決問題!
ELK系列~對fluentd參數的理解