
ML: 降維算法-LDA
判別分析(discriminant analysis)是一種分類技術。它通過一個已知類別的“訓練樣本”來建立判別準則,並通過預測變量來為未知類別的數據進行分類。判別分析的方法大體上有三類,即Fisher判別、Bayes判別和距離判別。
- Fisher判別思想是投影降維,使多維問題簡化為一維問題來處理。選擇一個適當的投影軸,使所有的樣品點都投影到這個軸上得到一個投影值。對這個投影軸的方向的要求是:使每一組內的投影值所形成的組內離差盡可能小,而不同組間的投影值所形成的類間離差盡可能大。
- Bayes判別思想是根據先驗概率求出後驗概率,並依據後驗概率分布作出統計推斷。
- 距離判別思想是根據已知分類的數據計算各類別的重心,對未知分類的數據,計算它與各類重心的距離,與某個重心距離最近則歸於該類
線性判別式分析(Linear Discriminant Analysis,簡稱為LDA)是模式識別的經典算法,在1996年由Belhumeur引入模式識別和人工智能領域。LDA的基本思想是將高維的模式樣本投影到最佳鑒別矢量空間,以達到抽取分類信息和壓縮特征空間維數的效果,投影後保證模式樣本在新的子空間有最大的類間距離和最小的類內距離,即模式在該空間中有最佳的可分離性。
特征選擇(亦即降維)是數據預處理中非常重要的一個步驟。對於分類來說,特征選擇可以從眾多的特征中選擇對分類最重要的那些特征,去除原數據中的噪音。主成分分析(PCA)與線性判別式分析(LDA)是兩種最常用的特征選擇算法。但是他們的目標基本上是相反的,如下列示LDA與PCA之間的區別。
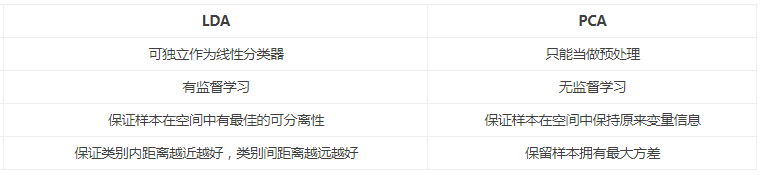
- 出發思想不同。PCA主要是從特征的協方差角度,去找到比較好的投影方式,即選擇樣本點投影具有最大方差的方向;而LDA則更多的是考慮了分類標簽信息,尋求投影後不同類別之間數據點距離更大化以及同一類別數據點距離最小化,即選擇分類性能最好的方向。
- 學習模式不同。PCA屬於無監督式學習,因此大多場景下只作為數據處理過程的一部分,需要與其他算法結合使用,例如將PCA與聚類、判別分析、回歸分析等組合使用;LDA是一種監督式學習方法,本身除了可以降維外,還可以進行預測應用,因此既可以組合其他模型一起使用,也可以獨立使用。
- 降維後可用維度數量不同。LDA降維後最多可生成C-1維子空間(分類標簽數-1),因此LDA與原始維度數量無關,只有數據標簽分類數量有關;而PCA最多有n維度可用,即最大可以選擇全部可用維度。
同一樣例兩種降維方法很直觀的不同對比結果:
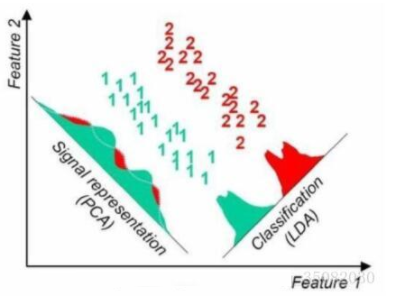
線性判別分析LDA算法由於其簡單有效性在多個領域都得到了廣泛地應用,是目前機器學習、數據挖掘領域經典且熱門的一個算法;但是算法本身仍然存在一些局限性:
- 當樣本數量遠小於樣本的特征維數,樣本與樣本之間的距離變大使得距離度量失效,使LDA算法中的類內、類間離散度矩陣奇異,不能得到最優的投影方向,在人臉識別領域中表現得尤為突出
- LDA不適合對非高斯分布的樣本進行降維
- LDA在樣本分類信息依賴方差而不是均值時,效果不好
- LDA可能過度擬合數據
LDA的應用應用場景:
- 人臉識別中的降維或模式識別
- 根據市場宏觀經濟特征進行經濟預測
- 根據市場或用戶不同屬性進行市場調研
- 根據患者病例特征進行醫學病情預測
MASS::lda
R中使用MASS包的lda函數實現線性判別。lda函數以Bayes判別思想為基礎。當分類只有兩種且總體服從多元正態分布條件下,Bayes判別與Fisher判別、距離判別是等價的。代碼示例:
> if (require(MASS) == FALSE) + { + install.packages("MASS") + } > > model1=lda(Species~.,data=iris) > table <- table(iris$Species,predict(model1)$class) > table setosa versicolor virginica setosa 50 0 0 versicolor 0 48 2 virginica 0 1 49 > sum(diag(prop.table(table)))###判對率 [1] 0.98
結果可觀察到判斷錯誤的樣本只有三個。在判別函數建立後,還可以類似主成分分析那樣對判別得分進行繪圖
> ld <- predict(model1)$x #表示映射到模型中的向量上的值;即score值 > ds <- cbind(iris,as.data.frame(ld)) > head(ds) Sepal.Length Sepal.Width Petal.Length Petal.Width Species LD1 LD2 1 5.1 3.5 1.4 0.2 setosa 8.061800 0.3004206 2 4.9 3.0 1.4 0.2 setosa 7.128688 -0.7866604 3 4.7 3.2 1.3 0.2 setosa 7.489828 -0.2653845 4 4.6 3.1 1.5 0.2 setosa 6.813201 -0.6706311 5 5.0 3.6 1.4 0.2 setosa 8.132309 0.5144625 6 5.4 3.9 1.7 0.4 setosa 7.701947 1.4617210 > p=ggplot(ds,mapping = aes(x=LD1,y=LD2)) > p+geom_point(aes(colour=Species),alpha=0.8,size=3)
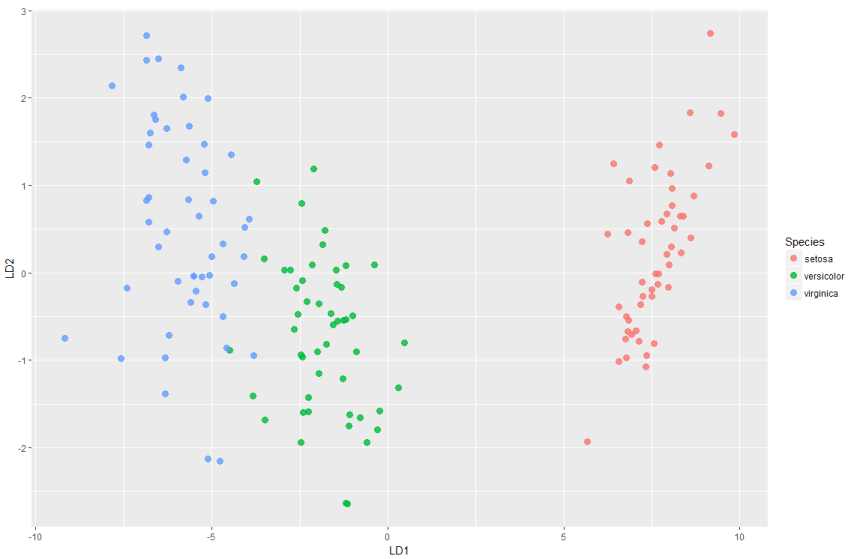
再看一組基於主成份預測數據
> model2 <- lda(Species~LD1+LD2,ds) > table(iris$Species,predict(model2)$class) setosa versicolor virginica setosa 50 0 0 versicolor 0 48 2 virginica 0 1 49
當不同類樣本的協方差矩陣不同時,則應該使用二次判別。在使用lda和qda函數時註意:其假設是總體服從多元正態分布,若不滿足的話則謹慎使用二次判別。
> iris.qda=qda(Species~.,data=iris,cv=T) > table<-table(iris$Species,predict(iris.qda,iris)$class) > table setosa versicolor virginica setosa 50 0 0 versicolor 0 48 2 virginica 0 1 49 > sum(diag(prop.table(table)))###判對率 [1] 0.98
CV參數設置為T,是使用留一交叉檢驗(leave-one-out cross-validation),並自動生成預測值。這種條件下生成的混淆矩陣較為可靠。此外還可以使用predict(model)$posterior提取後驗概率
ML: 降維算法-LDA