
VM搭建Hadoop環境遇到的問題
一、Slave2中sshd服務一直處於啟動失敗狀態
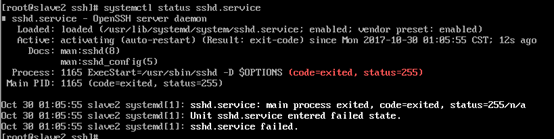
查看配置文件
c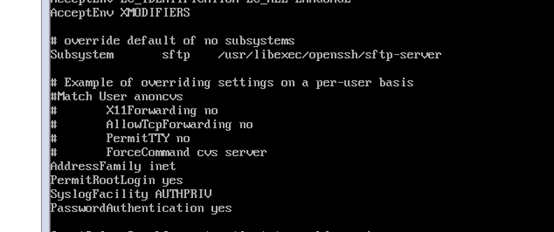
發現配置文件末尾slave2和master不同,更改過後問題解決,可以連接

二、啟動Hadoop時,SSH免密驗證失敗

查看日誌信息,每次日誌均卡在這個位置
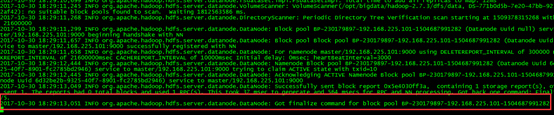
查詢發現master中 datanode一直未啟動
因為在執行./start-dfs.sh中,手動輸入過一次密碼,猜測免密登錄配置錯誤
回憶配置過程:
切換到hadoop角色後,進入/root/.ssh目錄,發現權限不夠
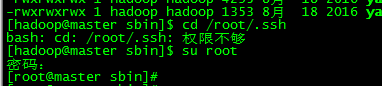
所以采用在root角色下進行免密配置
最終可以實現ssh hadoop@slave1免密登錄,但是在hadoop啟動的時候仍然需要密碼登錄,這就是錯誤原因。
忽略的問題,應該進入的是當前角色的ssh目錄,即~/.ssh,所以拷貝的時候命令應該是:
錯誤:ssh-copy-id -i /root/.ssh/id_rsa.pub hadoop@slave1
正確:ssh-copy-id -i ~/.ssh/id_rsa.pub
重新執行./start-dfs.sh
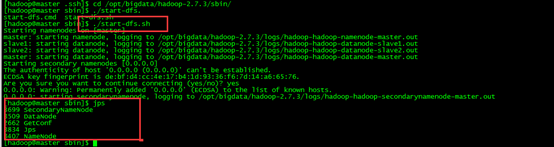
瀏覽器訪問啟動成功
VM搭建Hadoop環境遇到的問題
相關推薦
VM搭建Hadoop環境遇到的問題
訪問 root 搭建 nod 失敗 rsa ont .sh -1 一、Slave2中sshd服務一直處於啟動失敗狀態 查看配置文件 c 發現配置文件末尾slave2和master不同,更改過後問題解決,可以連接 二、啟動Hadoop時,SSH免密驗證失敗 查看
VM+CentOS+hadoop2.7搭建hadoop完全分散式叢集
寫在前邊的話: 最近找了一個雲端計算開發的工作,本以為來了會直接做一些敲程式碼,處理資料的活,沒想到師父給了我一個課題“基於質量資料的大資料分析”,那麼問題來了首先要做的就是搭建這樣一個平臺,毫無疑問,底層採用hadoop叢集,在此之上,進行一些其他元件的安裝和二
[虛擬機器VM][Ubuntu12.04]搭建Hadoop完全分散式環境(一)
前言 大家都知道,Hadoop的部署方式可分為 單機模式 偽分散式 完全分散式 本篇主要講解的就是完全分散式。 搭建完全分散式的叢集環境,需要多臺的硬體裝置,作為初學者,為了搭建叢集去買多臺電腦,多少有點不現實,所以這裡我採用的是VM虛擬機器,模擬搭
[虛擬機器VM][Ubuntu12.04]搭建Hadoop完全分散式環境(三)(終篇)
接前兩篇,這是最終篇,前面的準備工作都完成了之後,我們開始安裝和部署hadoop 安裝和配置Hadoop hadoop叢集中每臺機器的配置都基本相同,我們先配置好master,然後複製到slave1和slave2上 1、下載並解壓,並重命名目錄
CentOS 下 Hadoop 環境搭建--Hadoop
mkdir left res 修改文件 wordcount cat 創建 work tar ---恢復內容開始--- ①解壓Hadoop到自定目錄下面(這裏解壓到/opt/hadoop目錄下) tar -zxvf hadoop-2.5.0.tar.gz -C /opt/
vmware搭建hadoop集群完整過程筆記
器) 修改文件權限 配置環境 chmod 出現問題 2.6.0 img key文件 無權限 搭建hadoop集群完整過程筆記 一、虛擬機和操作系統 環境:ubuntu14+hadoop2.6+jdk1.8 虛擬機:vmware12 二、安裝步驟: 先在一臺機器上
Hadoop初體驗:快速搭建Hadoop偽分布式環境
hadoop 偽分布式 大數據 0.前言 本文旨在使用一個全新安裝好的Linux系統從0開始進行Hadoop偽分布式環境的搭建,以達到快速搭建的目的,從而體驗Hadoop的魅力所在,為後面的繼續學習提供基礎環境。 對使用的系統環境作如下說明:操作系統:CentOS 6.5 64位主機I
ubuntu16.04搭建hadoop集群環境
address hadoop 集群 所有 ipv ret 加載文件 keygen -- manager 1. 系統環境Oracle VM VirtualBoxUbuntu 16.04Hadoop 2.7.4Java 1.8.0_111master:192.168.19.12
eclipse上搭建hadoop開發環境
hadoop一、概述1.實驗使用的Hadoop集群為偽分布式模式,eclipse相關配置已完成;2.軟件版本為hadoop-2.7.3.tar.gz、apache-maven-3.5.0.rar。 二、使用eclipse連接hadoop集群進行開發1.在開發主機上配置hadoop①將hadoop-2.7.3.
大數據Hadoop學習之搭建Hadoop平臺(2.1)
穩定版 發的 log tar sshd scheduler 文件夾 三種 rest 關於大數據,一看就懂,一懂就懵。 一、簡介 Hadoop的平臺搭建,設置為三種搭建方式,第一種是“單節點安裝”,這種安裝方式最為簡單,但是並沒有展示出Hadoop的技術優勢,適
Amabari搭建Hadoop集群(一)
hdp ambari 一、系統環境1.系統版本[root@manager ~]# cat /etc/centos-release CentOS Linux release 7.4.1708 (Core)2.主機規劃主機名IP地址角色manager192.168.10.131ambari-serverv
Amabari搭建Hadoop集群(二)
amabr hdp 一、進入登陸頁面1.在瀏覽器中輸入ambari-server端地址,初始賬戶和密碼都是admin2.登陸後進入向導界面,點擊Launch Install Wizard3.設置集群名稱二、安裝相關組件1.選擇HDP版本,註意選擇使用本地源2.輸入其他節點的主機名或IP,並選擇SSH配
CentOS 6.5 搭建Hadoop 1.2.1集群
nod otn ip地址 maps shuffle 都是 ber 6.5 inux 記錄在64位CentOS 6.5環境下搭建Hadoop 2.5.2集群的步驟,同時遇到問題的解決辦法,這些記錄都僅供參考! 1、操作系統環境配置 1.1、操作系統環境 主機名 IP地址
Hadoop學習(一)搭建Hadoop的分布式集群
例子程序 eve work 鍵盤 規劃 shuffle 系統變量 p s har 搭建Hadoop的分布式集群 Hadoop集群搭建的準備操作: 1、準備四臺服務器 四臺服務器的主機名分別是:potter2、potter3、potter4、potter5。 對以上四
Ubuntu搭建Hadoop的踩坑之旅(三)
namenode 結束 ctu mapreduce 分布 使用 framework 2.6 start 之前的兩篇文章介紹了如何從0開始到搭建好帶有JDK的Ubuntu的過程,本來這篇文章是打算介紹搭建偽分布式集群的。但是後來想想反正偽分布式和完全分布式差不多,所幸直接介紹
虛擬機搭建Hadoop
虛擬機搭建Hadoop最近學習搭建hadoop,通過邊查資料邊搭建,花了半天也搭建好了,借此寫下搭建總結,在這裏感謝博友【數據放大鏡】的文章,很不錯,就是按照他的步驟搭建下來的,在這裏,自己完善了一下,不說了,直接開搞:Ps:由於自己的本本配置略差,所以只裝了3個虛擬機 1:工具列表Linux
虛擬機搭建Hadoop集群
openss 正常 orien gac 使用 encoding text 外網 source 安裝包準備 操作系統:ubuntu-16.04.3-desktop-amd64.iso 軟件包:VirtualBox 安裝包:hadoop-3.0.0.tar.gz,jdk-8u
新手入門篇:虛擬機搭建hadoop環境的詳細步驟
文檔 優勢 indent gic 地址 完成 align 頁面 一段 前兩天看到有人留言問在什麽情況下需要部署hadoop,我給的回答也很簡單,就是在需要處理海量數據的時候才需要考慮部署hadoop。關於這個問題在很早之前的一篇分享文檔也有說到這個問題,數據量少的完全發揮不
ubantu中搭建Hadoop環境20180908(全)
初始 The lib 服務 指向 ref hdfs alter open 一. Ubuntu Java8 的安裝 添加ppa sudo add-apt-repository ppa:webupd8team/java sudo apt-get updat
CentOS6.5x64搭建Hadoop環境
ipv data 查看 大致 ber 裝配 yarn 鏡像 3.2 首先總結一下之所以被搭建大數據環境支配的原因:浮躁。 總是坐不住,總是嫌視頻太長,總是感覺命令太雜太多,所以就不願去面對。 在抖音上聽到一句話:“為什麽人們不願吃學習的苦而能吃社會的苦