
StanFord ML 筆記 第八部分
第八部分內容:
1.正則化Regularization
2.在線學習(Online Learning)
3.ML 經驗
1.正則化Regularization
1.1通俗解釋
引用知乎作者:刑無刀
解釋之前,先說明這樣做的目的:如果一個模型我們只打算對現有數據用一次就不再用了,那麽正則化沒必要了,因為我們沒打算在將來他還有用,正則化的目的是為了讓模型的生命更長久,把它扔到現實的數據海洋中活得好,活得久。
俗氣的解釋1:
讓模型參數不要在優化的方向上縱欲過度。《紅樓夢》裏,賈瑞喜歡王熙鳳得了相思病,病榻中得到一枚風月寶鑒,可以進入和心目中的女神XXOO,它腦子裏的模型目標函數就是“最大化的爽”,所以他就反復去擬合這個目標,多次XXOO,於是人掛掉了,如果給他加一個正則化,讓它爽,又要控制爽的頻率,那麽他可以爽得更久。
俗氣的解釋2:
假如馬化騰心中的商業模型優化目標是讓騰訊發展得更好,他的模型只有一個特征,就是張小龍,根據他的目標以及已有樣本,它應該給張小龍賦予更大的權重,就可以一直讓模型的表現朝這個目標前進,但是,突然有一天馬化騰意識到:這樣下去不行啊,他的權重大得沒邊的話,根本不可持續啊,他要是走了,他要是取代我了。於是馬化騰就需要在優化這個目標的時候給這個唯一的特征加一個正則化參數,讓權重不要過大,從而使得整個模型能夠既朝著設定目標走,又不至於無法持續。
俗氣的解釋3:
我們這群技術男在公司裏,如果模型目標是提高自身能力並最終能夠在公司有一席之地,理想的優化方法是提高各種牛逼算法,各種高大上的計算平臺的熟悉程度,盡量少開無謂的會議,少接領導扯淡的需求,但是如果只是這些的話,很可能在這個公司呆不太久,因為太關註自己的特征權重了,那麽如果這個公司其實非常適合提升自己的能力,那麽要能在這裏呆久點,就得適當限制自己這些特征的權重絕對值,不要那麽絕對堅持用到牛逼算法,偶爾也處理處理領導的扯淡需求,平衡一下,你的模型才能泛化得更廣。
1.2用協方差解釋
引用知乎作者:維吉特伯
其中 和
是列向量,
是矩陣,矩陣的每一行對應一個輸入實例。把平方誤差和(residual sum of squares, RSS)作為損失函數:
假設要擬合一個線性的模型
寫成矩陣形式就是
把 對
求偏導,並令偏導為0,
可以得出最小化損失的解:
然後再對損失添加正則化項(為了簡化推導就用嶺回歸吧,添加 的平方項),下面我就直接寫成向量形式啦:
同樣,再對 求偏導,並令偏導為0
得出解為:
然後,對 進行奇異值分解(SVD):
再拿訓練得到的 再擬合一下訓練數據,再套用一下奇異值分解:
對比一下沒有正則化項的情況:
發現什麽了嗎,正則化之後, 和
之間相差了一個系數
。
因為 ,所以
。
這意味著加入正則化項的嶺回歸擬合的結果被縮小了 倍。那麽,這個
的意義是什麽呢?
再對輸入作進一步假設來簡化問題。如果輸入 的均值為0,也就是對
進行預處理使得:
那麽, 的協方差就可以通過
計算,並且根據之前的奇異值分解
,有
這實際上也可以看作是 的特征分解。
所以 就是
的第
個特征值。
因此系數 可以看作根據協方差矩陣的特征值對不同成分進行收縮(個人理解為進行了一次隱式的特征選擇),並且對特征值小的成分收縮更為劇烈(可以理解為通過把那些方差小的成分舍棄掉了,有點類似主成分分析,把那些重要的成分留下,次要的去除掉)。除了
之外,
也會影響收縮的程度。
值越大,收縮的越劇烈(需要更大的
來補償
),最終模型復雜度越低 。附上來自《The Elements of Statistical Learning》的圖。
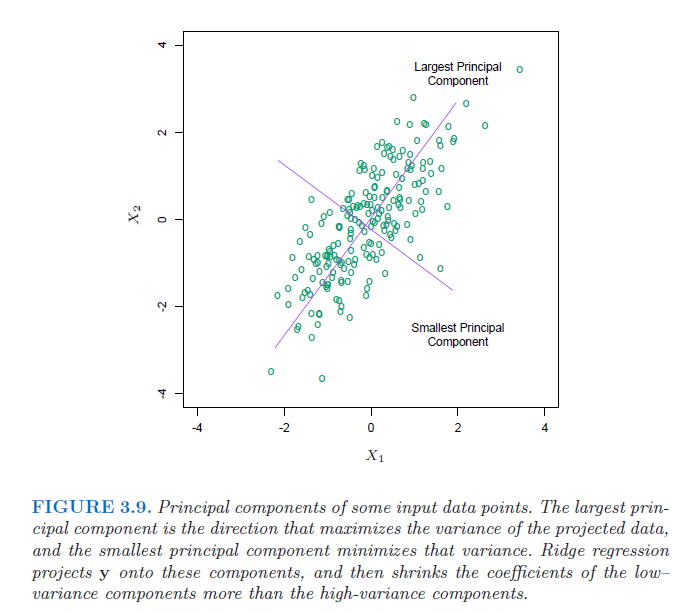
這樣通過正則化項,就去減小了那些沒用(次要)的特征帶來的影響,防止過擬合。
1.3Ng視頻的講解
http://blog.csdn.net/stdcoutzyx/article/details/18500441
1.4個人總結
A.加入先驗概率,正如我們都知道骰子每個概率是1/6,但是實驗10次都是正面,我們能說正面概率為百分之百嗎?加入前面的先驗1/6效果就好多了。
B.在似然函數後面加上了aXXT,後面的XXT就是協方差,前面的a是比例,協方差的意思就是太離譜的數據權重就小,a的作用和高斯的均值一樣。
2.在線學習
參考:https://www.zhihu.com/question/20700829(正則化的話題,很多知乎大神的回答)
StanFord ML 筆記 第八部分