
代碼級性能優化案例(一)
一、壓測服務器環境
服務器配置:4核CPU 8G內存 共4臺
MQ:RabbitMQ
數據庫:DB2
SOA框架:公司內部封裝的Dubbo
緩存框架:Redis,Memcached
統一配置管理系統:公司內部開發的系統
二、壓測性能問題描述
1、 單臺40TPS,加到4臺服務器能到60TPS,擴展性幾乎沒有。2、 在實際生產環境中,經常出現數據庫死鎖導致整個服務中斷不可用。
3、 數據庫事務亂用,導致事務占用時間太長。
4、 在實際生產環境中,服務器經常出現內存溢出和CPU時間被占滿。
5、 程序開發的過程中,考慮不全面,容錯很差,經常因為一個小bug而導致服務不可用。
6、 程序中沒有打印關鍵日誌,或者打印了日誌,信息卻是無用信息沒有任何參考價值。
7、 配置信息和變動不大的信息依然會從數據庫中頻繁讀取,導致數據庫IO很大。
8、 項目拆分不徹底,一個tomcat中會布署多個項目WAR包。
9、 因為基礎平臺的bug,或者功能缺陷導致程序可用性降低。
10、程序接口中沒有限流策略,導致很多vip商戶直接拿我們的生產環境進行壓測,直接影響真正的服務可用性。
11、沒有故障降級策略,項目出了問題後解決的時間較長,或者直接粗暴的回滾項目,但是不一定能解決問題。
12、沒有合適的監控系統,不能準實時或者提前發現項目瓶頸。
三、優化解決方案
1、數據庫死鎖優化解決
我們從第二條開始分析,先看一個基本例子展示數據庫死鎖的發生: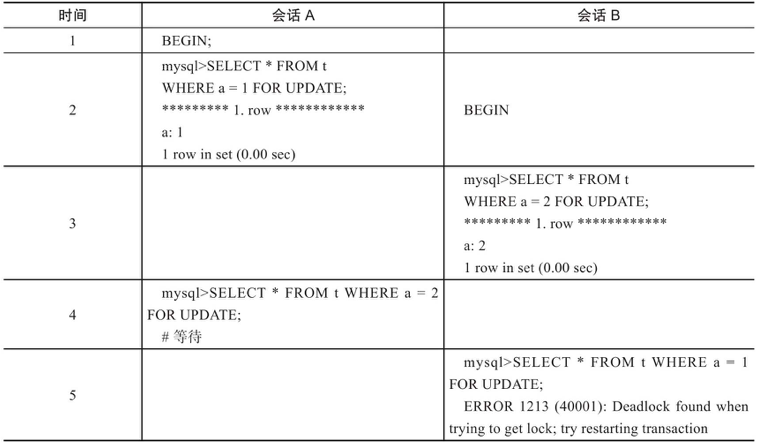
註:
在上述事例中,會話B會拋出死鎖異常,死鎖的原因就是A和B二個會話互相等待。
分析:出現這種問題就是我們在項目中混雜了大量的事務+for update語句,針對數據庫鎖來說有下面三種基本鎖:

當for update語句和gap lock和next-key lock鎖相混合使用,又沒有註意用法的時候,就非常容易出現死鎖的情況。
那我們用大量的鎖的目的是什麽,經過業務分析發現,其實就是為了防重,同一時刻有可能會有多筆支付單發到相應系統中,而防重措施是通過在某條記錄上加鎖的方式來進行。
針對以上問題完全沒有必要使用悲觀鎖的方式來進行防重,不僅對數據庫本身造成極大的壓力,同時也會把對於項目擴展性來說也是很大的擴展瓶頸,我們采用了三種方法來解決以上問題:
-
使用Redis來做分布式鎖,Redis采用多個來進行分片,其中一個Redis掛了也沒關系,重新爭搶就可以了。
-
使用主鍵防重方法,在方法的入口處使用防重表,能夠攔截所有重復的訂單,當重復插入時數據庫會報一個重復錯,程序直接返回。
-
使用版本號的機制來防重。
以上三種方式都必須要有過期時間,當鎖定某一資源超時的時候,能夠釋放資源讓競爭重新開始。
2、數據庫事務占用時間過長
偽代碼示例:
public void test() { Transaction.begin //事務開啟 try { dao.insert //插入一行記錄 httpClient.queryRemoteResult() //請求訪問 dao.update //更新一行記錄 Transaction.commit() //事務提交 } catch(Exception e) { Transaction.rollFor //事務回滾 } }
項目中類似這樣的程序有很多,經常把類似httpClient,或者有可能會造成長時間超時的操作混在事務代碼中,不僅會造成事務執行時間超長,而且也會嚴重降低並發能力。
那麽我們在用事務的時候,遵循的原則是快進快出,事務代碼要盡量小。針對以上偽代碼,我們要用httpClient這一行拆分出來,避免同事務性的代碼混在一起,這不是一個好習慣。
3、CPU時間被占滿分析
下面以我之前分析的一個案例作為問題的起始點,首先看下面的圖:
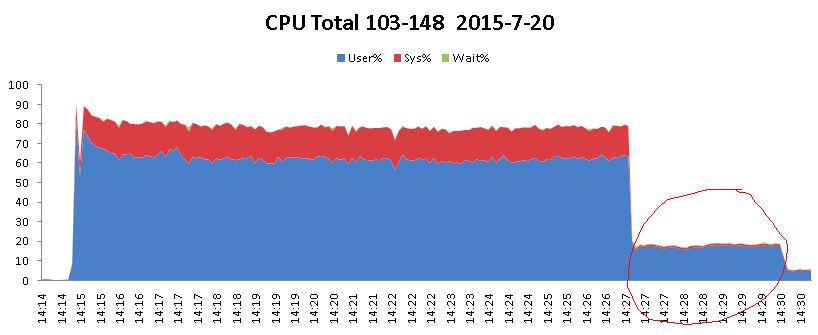
項目在壓測的過程中,cpu一直居高不下,那麽通過分析得出如下分析:
4、數據庫連接池影響
我們針對線上的環境進行模擬,盡量真實的在測試環境中再現,采用數據庫連接池為咱們默認的C3P0。
那麽當壓測到二萬批,100個用戶同時訪問的時候,並發量突然降為零!報錯如下:
com.yeepay.g3.utils.common.exception.YeepayRuntimeException: Could not get JDBC Connection; nested exception is java.sql.SQLException: An attempt by a client to checkout a Connection has timed out.
那麽針對以上錯誤跟蹤C3P0源碼,以及在網上搜索資料:http://blog.sina.com.cn/s/blog_53923f940100g6as.html
發現C3P0在大並發下表現的性能不佳。
5、線程池使用不當引起
private static final ExecutorService executorService = Executors.newCachedThreadPool(); /** * 異步執行短頻快的任務 * @param task */ public static void asynShortTask(Runnable task){ executorService.submit(task); //task.run(); } CommonUtils.asynShortTask(new Runnable() { @Override public void run() { String sms = sr.getSmsContent(); sms = sms.replaceAll(finalCode, AES.encryptToBase64(finalCode, ConstantUtils.getDB_AES_KEY())); sr.setSmsContent(sms); smsManageService.addSmsRecord(sr); } });
以上代碼的場景是每一次並發請求過來,都會創建一個線程,將DUMP日誌導出進行分析發現,項目中啟動了一萬多個線程,而且每個線程都極為忙碌,徹底將資源耗盡。
那麽問題到底在哪裏呢???就在這一行!
private static final ExecutorService executorService = Executors.newCachedThreadPool();
在並發的情況下,無限制的申請線程資源造成性能嚴重下降,在圖表中顯拋物線形狀的元兇就是它!!!那麽采用這種方式最大可以產生多少個線程呢??
答案是:Integer的最大值!看如下源碼:

那麽嘗試修改成如下代碼:
private static final ExecutorService executorService = Executors.newFixedThreadPool(50);

可以看到采用的是無界隊列,也就是說隊列是可以無限的存放可執行的線程,造成大量對象無法釋放和回收。
最終線程池技術方案
方案一:
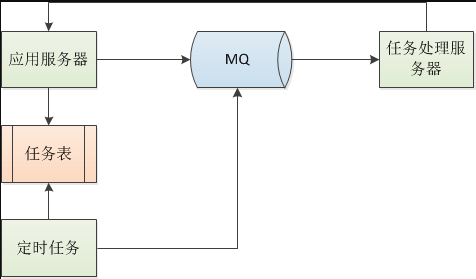
註:因為服務器的CPU只有4核,有的服務器甚至只有2核,所以在應用程序中大量使用線程的話,反而會造成性能影響,針對這樣的問題,我們將所有異步任務全部拆出應用項目,以任務的方式發送到專門的任務處理器處理,處理完成回調應用程序器。後端定時任務會定時掃描任務表,定時將超時未處理的異步任務再次發送到任務處理器進行處理。
方案二:
使用AKKA技術框架,下面是我以前寫的一個簡單的壓測情況:
http://www.jianshu.com/p/6d62256e3327
6、日誌打印問題
先看下面這段日誌打印程序:
QuataDTO quataDTO = null; try { quataDTO = getRiskLimit(payRequest.getQueryRiskInfo(), payRequest.getMerchantNo(), payRequest.getIndustryCatalog(), cardBinResDTO.getCardType(), cardBinResDTO.getBankCode(), bizName); } catch (Exception e) { logger.info("獲取風控限額異常", e); }
像這樣的代碼是嚴格不符合規範的,雖然每個公司都有自己的打印要求。
- 首先日誌的打印必須是以logger.error或者logger.warn的方式打印出來。
- 日誌打印格式:[系統來源] 錯誤描述 [關鍵信息],日誌信息要能打印出能看懂的信息,有前因和後果。甚至有些方法的入參和出參也要考慮打印出來。
- 在輸入錯誤信息的時候,Exception不要以e.getMessage的方式打印出來。
合理的日誌格式是:
logger.warn("[innersys] - [" + exceptionType.description + "] - [" + methodName + "] - " + "errorCode:[" + errorCode + "], " + "errorMsg:[" + errorMsg + "]", e); logger.info("[innersys] - [入參] - [" + methodName + "] - " + LogInfoEncryptUtil.getLogString(arguments) + "]"); logger.info("[innersys] - [返回結果] - [" + methodName + "] - " + LogInfoEncryptUtil.getLogString(result));
我們在程序中大量的打印日誌,雖然能夠打印很多有用信息幫助我們排查問題,但是更多是日誌量太多不僅影響磁盤IO,更多會造成線程阻塞對程序的性能造成較大影響。
在使用Log4j1.2.14版本的時候,使用如下格式:
%d %-5p %c:%L [%t] - %m%n
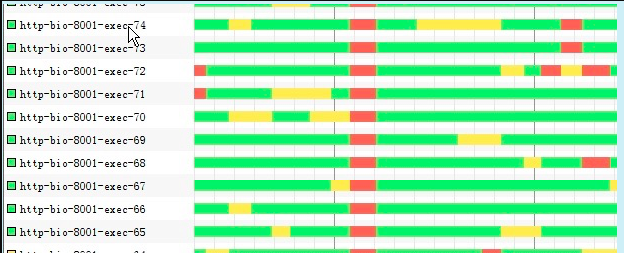
那麽在壓測的時候會出現下面大量的線程阻塞,如下圖:

再看壓測圖如下:

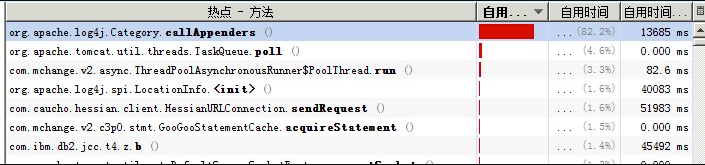
原因可以根據log4j源碼分析如下:
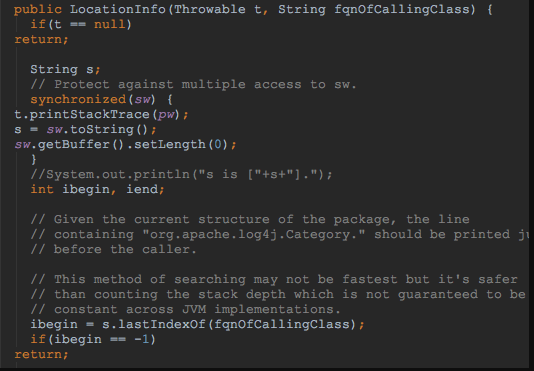
註:Log4j源碼裏用了synchronized鎖,然後又通過打印堆棧來獲取行號,在高並發下可能就會出現上面的情況。
於是修改log4j配置文件為:

上面問題解決,線程阻塞的情況很少出現,極大的提高了程序的並發能力,如下圖所示:
http://www.jianshu.com/p/c4a748002e66
代碼級性能優化案例(一)