
機器學習之邏輯回歸
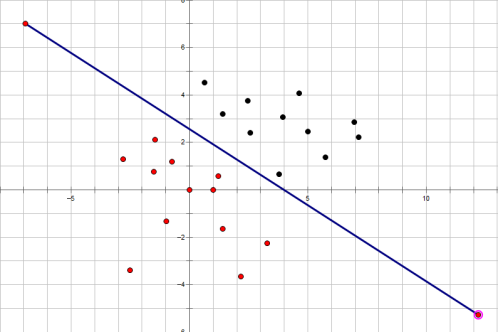
給定一張圖片,如何讓計算機幫助我們識別它是不是一張貓的圖片,這個問題可以看成一個簡單的分類問題。如下圖所示,平面上有兩種不同顏色(黑色,紅色)的點,我們要做到就是要找到類似與那條直線那樣的界限。當某個點位於直線上方時,那麽就可以判定該點是黑色的,當某個點位於直線的下方時,那麽就可以判定該點是紅色的。
- 正向傳播
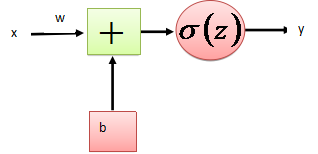
正向傳播考慮的是如何得到這條直線的方程,可以先來假定這條直線的函數為,這裏的W和b先任意取一個數(可能會很不準確),當我們把x帶入裏面後會有一個輸出y,從圖中我們發現當y值越大,那麽它就越可能屬於黑色點一類,當y值越小,那麽它就越有可能屬於紅色點一類。這種接近程度通常可以用概率來表示,由此引入
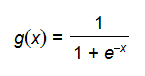
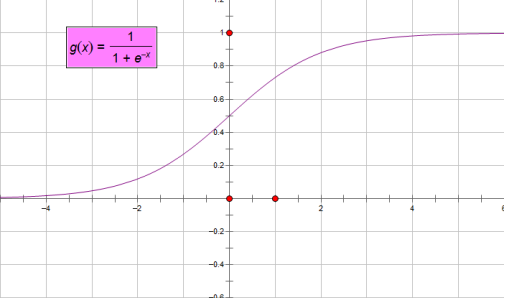
正如圖像所示,sigmoid函數的值域為(0,1),定義域為(-∞,+∞)。下面求兩個極限
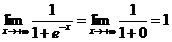
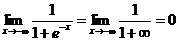
這就意味著無論我們在實數的定義域內取何值,經過sigmoid函數運算後結果都可以收斂於(0,1)之間,而一件事發生的概率取值正好滿足此區間。
對於sigmoid函數的理解
令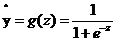 ,
,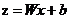 ,當我們輸入x後用事先任取的w,b參與運算後會得到一個z值,這個z值越大,就認為這點越接近黑色的點,將z帶入sigmoid函數z值越大g(z)的值就越接近1,可以認為該點是黑色的點的概率越接近1。Z值越小,認為這點越接近紅色的點(越遠離黑色的點),將z帶入sigmoid函數z值越小
,當我們輸入x後用事先任取的w,b參與運算後會得到一個z值,這個z值越大,就認為這點越接近黑色的點,將z帶入sigmoid函數z值越大g(z)的值就越接近1,可以認為該點是黑色的點的概率越接近1。Z值越小,認為這點越接近紅色的點(越遠離黑色的點),將z帶入sigmoid函數z值越小
- 反向傳播
反向傳播考慮的是直線的方程準不準,即參數w,b的取值是否合理。利用數據訓練的過程實質上就是不斷叠代尋找最合適的參數的過程。判斷參數準不準,就要用一個偏差來衡量實際輸出與真實結果y(真實y取1或0,1表示這點是黑色,0表示這點不是黑色)之間的距離。由此需要來定義損失函數。
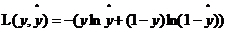
這樣定義是為了避免在進行梯度下降法中得到局部最優解(不太理解)。
當y=0時,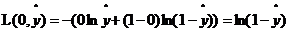 ,如果想讓損失函數取值較小即距離越小,那麽
,如果想讓損失函數取值較小即距離越小,那麽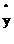 就應該接近0。
就應該接近0。
當y=1時,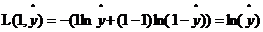 ,如果想讓損失函數取值較小即距離越小,那麽
,如果想讓損失函數取值較小即距離越小,那麽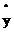 就應該接近1。
就應該接近1。
梯度下降法
梯度的方向是函數變化速度最快的方向,為了使損失函數取到最小值,所以需要使用按照梯度下降的方向來逐步叠代求出函數的最小值。
令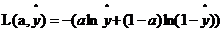
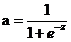
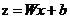
那麽由鏈式求導法有一下關系

得到
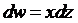
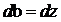
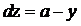
那麽更新後的w,b變為
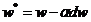
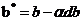
其中α為學習率,需要人為設置。對於更新後的w,b為了達到較好的訓練效果,需要再次正向傳播得到輸出,再進行反向傳播縮小差距更新w,b多次叠代。
以上所談如下圖所示僅為一個樣本輸入一層傳播的情況。
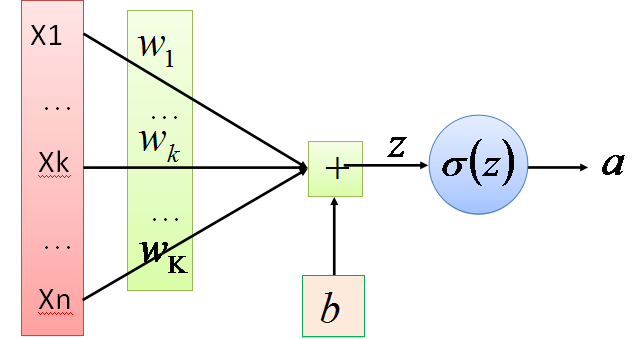
對於如下圖所示的多個樣本輸入的一層傳播情況,需要將樣本數據寫成矩陣形式,相應的運算變為矩陣運算。
機器學習之邏輯回歸