
Java幾種常見的編碼方式
幾種常見的編碼格式
為什麽要編碼
不知道大家有沒有想過一個問題,那就是為什麽要編碼?我們能不能不編碼?要回答這個問題必須要回到計算機是如何表示我們人類能夠理解的符號的,這些符號也就是我們人類使用的語言。由於人類的語言有太多,因而表示這些語言的符號太多,無法用計算機中一個基本的存儲單元—— byte 來表示,因而必須要經過拆分或一些翻譯工作,才能讓計算機能理解。我們可以把計算機能夠理解的語言假定為英語,其它語言要能夠在計算機中使用必須經過一次翻譯,把它翻譯成英語。這個翻譯的過程就是編碼。所以可以想象只要不是說英語的國家要能夠使用計算機就必須要經過編碼。這看起來有些霸道,但是這就是現狀,這也和我們國家現在在大力推廣漢語一樣,希望其它國家都會說漢語,以後其它的語言都翻譯成漢語,我們可以把計算機中存儲信息的最小單位改成漢字,這樣我們就不存在編碼問題了。
所以總的來說,編碼的原因可以總結為:
計算機中存儲信息的最小單元是一個字節即 8 個 bit,所以能表示的字符範圍是 0~255 個
人類要表示的符號太多,無法用一個字節來完全表示
要解決這個矛盾必須需要一個新的數據結構 char,從 char 到 byte 必須編碼
如何“翻譯”
明白了各種語言需要交流,經過翻譯是必要的,那又如何來翻譯呢?計算中提拱了多種翻譯方式,常見的有 ASCII、ISO-8859-1、GB2312、GBK、UTF-8、UTF-16 等。它們都可以被看作為字典,它們規定了轉化的規則,按照這個規則就可以讓計算機正確的表示我們的字符。目前的編碼格式很多,例如 GB2312、GBK、UTF-8、UTF-16 這幾種格式都可以表示一個漢字,那我們到底選擇哪種編碼格式來存儲漢字呢?這就要考慮到其它因素了,是存儲空間重要還是編碼的效率重要。根據這些因素來正確選擇編碼格式,下面簡要介紹一下這幾種編碼格式。
ASCII 碼
學過計算機的人都知道 ASCII 碼,總共有 128 個,用一個字節的低 7 位表示,0~31 是控制字符如換行回車刪除等;32~126 是打印字符,可以通過鍵盤輸入並且能夠顯示出來。
ISO-8859-1
128 個字符顯然是不夠用的,於是 ISO 組織在 ASCII 碼基礎上又制定了一些列標準用來擴展 ASCII 編碼,它們是 ISO-8859-1~ISO-8859-15,其中 ISO-8859-1 涵蓋了大多數西歐語言字符,所有應用的最廣泛。ISO-8859-1 仍然是單字節編碼,它總共能表示 256 個字符。 GB2312
它的全稱是《信息交換用漢字編碼字符集 基本集》,它是雙字節編碼,總的編碼範圍是 A1-F7,其中從 A1-A9 是符號區,總共包含 682 個符號,從 B0-F7 是漢字區,包含 6763 個漢字。
GBK
全稱叫《漢字內碼擴展規範》,是國家技術監督局為 windows95 所制定的新的漢字內碼規範,它的出現是為了擴展 GB2312,加入更多的漢字,它的編碼範圍是 8140~FEFE(去掉 XX7F)總共有 23940 個碼位,它能表示 21003 個漢字,它的編碼是和 GB2312 兼容的,也就是說用 GB2312 編碼的漢字可以用 GBK 來解碼,並且不會有亂碼。
GB18030
全稱是《信息交換用漢字編碼字符集》,是我國的強制標準,它可能是單字節、雙字節或者四字節編碼,它的編碼與 GB2312 編碼兼容,這個雖然是國家標準,但是實際應用系統中使用的並不廣泛。
UTF-16
說到 UTF 必須要提到 Unicode(Universal Code 統一碼),ISO 試圖想創建一個全新的超語言字典,世界上所有的語言都可以通過這本字典來相互翻譯。可想而知這個字典是多麽的復雜,關於 Unicode 的詳細規範可以參考相應文檔。Unicode 是 Java 和 XML 的基礎,下面詳細介紹 Unicode 在計算機中的存儲形式。
UTF-16 具體定義了 Unicode 字符在計算機中存取方法。UTF-16 用兩個字節來表示 Unicode 轉化格式,這個是定長的表示方法,不論什麽字符都可以用兩個字節表示,兩個字節是 16 個 bit,所以叫 UTF-16。UTF-16 表示字符非常方便,每兩個字節表示一個字符,這個在字符串操作時就大大簡化了操作,這也是 Java 以 UTF-16 作為內存的字符存儲格式的一個很重要的原因。
UTF-8
UTF-16 統一采用兩個字節表示一個字符,雖然在表示上非常簡單方便,但是也有其缺點,有很大一部分字符用一個字節就可以表示的現在要兩個字節表示,存儲空間放大了一倍,在現在的網絡帶寬還非常有限的今天,這樣會增大網絡傳輸的流量,而且也沒必要。而 UTF-8 采用了一種變長技術,每個編碼區域有不同的字碼長度。不同類型的字符可以是由 1~6 個字節組成。
UTF-8 有以下編碼規則:
如果一個字節,最高位(第 8 位)為 0,表示這是一個 ASCII 字符(00 - 7F)。可見,所有 ASCII 編碼已經是 UTF-8 了。
如果一個字節,以 11 開頭,連續的 1 的個數暗示這個字符的字節數,例如:110xxxxx 代表它是雙字節 UTF-8 字符的首字節。
如果一個字節,以 10 開始,表示它不是首字節,需要向前查找才能得到當前字符的首字節
Java 中需要編碼的場景
前面描述了常見的幾種編碼格式,下面將介紹 Java 中如何處理對編碼的支持,什麽場合中需要編碼。
I/O 操作中存在的編碼
我們知道涉及到編碼的地方一般都在字符到字節或者字節到字符的轉換上,而需要這種轉換的場景主要是在 I/O 的時候,這個 I/O 包括磁盤 I/O 和網絡 I/O,關於網絡 I/O 部分在後面將主要以 Web 應用為例介紹。下圖是 Java 中處理 I/O 問題的接口:

Reader 類是 Java 的 I/O 中讀字符的父類,而 InputStream 類是讀字節的父類,InputStreamReader 類就是關聯字節到字符的橋梁,它負責在 I/O 過程中處理讀取字節到字符的轉換,而具體字節到字符的解碼實現它由 StreamDecoder 去實現,在 StreamDecoder 解碼過程中必須由用戶指定 Charset 編碼格式。值得註意的是如果你沒有指定 Charset,將使用本地環境中的默認字符集,例如在中文環境中將使用 GBK 編碼。
寫的情況也是類似,字符的父類是 Writer,字節的父類是 OutputStream,通過 OutputStreamWriter 轉換字符到字節。如下圖所示: 
同樣 StreamEncoder 類負責將字符編碼成字節,編碼格式和默認編碼規則與解碼是一致的。
如下面一段代碼,實現了文件的讀寫功能:
String file = "c:/stream.txt";
String charset = "UTF-8";
// 寫字符換轉成字節流
FileOutputStream outputStream = new FileOutputStream(file);
OutputStreamWriter writer = new OutputStreamWriter(
outputStream, charset);
try {
writer.write("這是要保存的中文字符");
} finally {
writer.close();
}
// 讀取字節轉換成字符
FileInputStream inputStream = new FileInputStream(file);
InputStreamReader reader = new InputStreamReader(
inputStream, charset);
StringBuffer buffer = new StringBuffer();
char[] buf = new char[64];
int count = 0;
try {
while ((count = reader.read(buf)) != -1) {
buffer.append(buffer, 0, count);
}
} finally {
reader.close();
}
在我們的應用程序中涉及到 I/O 操作時只要註意指定統一的編解碼 Charset 字符集,一般不會出現亂碼問題,有些應用程序如果不註意指定字符編碼,中文環境中取操作系統默認編碼,如果編解碼都在中文環境中,通常也沒問題,但是還是強烈的不建議使用操作系統的默認編碼,因為這樣,你的應用程序的編碼格式就和運行環境綁定起來了,在跨環境下很可能出現亂碼問題。
內存中操作中的編碼
在 Java 開發中除了 I/O 涉及到編碼外,最常用的應該就是在內存中進行字符到字節的數據類型的轉換,Java 中用 String 表示字符串,所以 String 類就提供轉換到字節的方法,也支持將字節轉換為字符串的構造函數。如下代碼示例:
String s = "這是一段中文字符串";
byte[] b = s.getBytes("UTF-8");
String n = new String(b,"UTF-8");
另外一個是已經被被廢棄的 ByteToCharConverter 和 CharToByteConverter 類,它們分別提供了 convertAll 方法可以實現 byte[] 和 char[] 的互轉。如下代碼所示:
ByteToCharConverter charConverter = ByteToCharConverter.getConverter("UTF-8");
char c[] = charConverter.convertAll(byteArray);
CharToByteConverter byteConverter = CharToByteConverter.getConverter("UTF-8");
byte[] b = byteConverter.convertAll(c);
這兩個類已經被 Charset 類取代,Charset 提供 encode 與 decode 分別對應 char[] 到 byte[] 的編碼和 byte[] 到 char[] 的解碼。如下代碼所示:
Charset charset = Charset.forName("UTF-8");
ByteBuffer byteBuffer = charset.encode(string);
CharBuffer charBuffer = charset.decode(byteBuffer);
編碼與解碼都在一個類中完成,通過 forName 設置編解碼字符集,這樣更容易統一編碼格式,比 ByteToCharConverter 和 CharToByteConverter 類更方便。
Java 中還有一個 ByteBuffer 類,它提供一種 char 和 byte 之間的軟轉換,它們之間轉換不需要編碼與解碼,只是把一個 16bit 的 char 格式,拆分成為 2 個 8bit 的 byte 表示,它們的實際值並沒有被修改,僅僅是數據的類型做了轉換。如下代碼所以:
ByteBuffer heapByteBuffer = ByteBuffer.allocate(1024); ByteBuffer byteBuffer = heapByteBuffer.putChar(c);
以上這些提供字符和字節之間的相互轉換只要我們設置編解碼格式統一一般都不會出現問題。
Java 中如何編解碼
前面介紹了幾種常見的編碼格式,這裏將以實際例子介紹 Java 中如何實現編碼及解碼,下面我們以“I am 君山”這個字符串為例介紹 Java 中如何把它以 ISO-8859-1、GB2312、GBK、UTF-16、UTF-8 編碼格式進行編碼的。
public static void encode() {
String name = "I am 君山";
toHex(name.toCharArray());
try {
byte[] iso8859 = name.getBytes("ISO-8859-1");
toHex(iso8859);
byte[] gb2312 = name.getBytes("GB2312");
toHex(gb2312);
byte[] gbk = name.getBytes("GBK");
toHex(gbk);
byte[] utf16 = name.getBytes("UTF-16");
toHex(utf16);
byte[] utf8 = name.getBytes("UTF-8");
toHex(utf8);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
}
我們把 name 字符串按照前面說的幾種編碼格式進行編碼轉化成 byte 數組,然後以 16 進制輸出,我們先看一下 Java 是如何進行編碼的。
下面是 Java 中編碼需要用到的類圖
圖 1. Java 編碼類圖 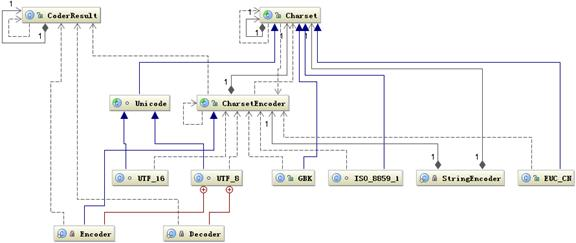
首先根據指定的 charsetName 通過 Charset.forName(charsetName) 設置 Charset 類,然後根據 Charset 創建 CharsetEncoder 對象,再調用 CharsetEncoder.encode 對字符串進行編碼,不同的編碼類型都會對應到一個類中,實際的編碼過程是在這些類中完成的。下面是 String. getBytes(charsetName) 編碼過程的時序圖
圖 2.Java 編碼時序圖 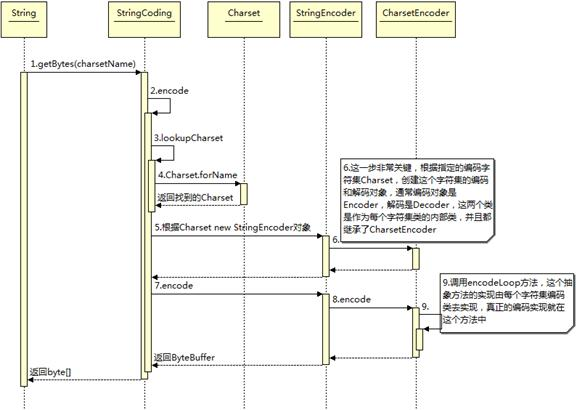
從上圖可以看出根據 charsetName 找到 Charset 類,然後根據這個字符集編碼生成 CharsetEncoder,這個類是所有字符編碼的父類,針對不同的字符編碼集在其子類中定義了如何實現編碼,有了 CharsetEncoder 對象後就可以調用 encode 方法去實現編碼了。這個是 String.getBytes 編碼方法,其它的如 StreamEncoder 中也是類似的方式。下面看看不同的字符集是如何將前面的字符串編碼成 byte 數組的?
如字符串“I am 君山”的 char 數組為 49 20 61 6d 20 541b 5c71,下面把它按照不同的編碼格式轉化成相應的字節。
按照 ISO-8859-1 編碼
字符串“I am 君山”用 ISO-8859-1 編碼,下面是編碼結果: 
從上圖看出 7 個 char 字符經過 ISO-8859-1 編碼轉變成 7 個 byte 數組,ISO-8859-1 是單字節編碼,中文“君山”被轉化成值是 3f 的 byte。3f 也就是“?”字符,所以經常會出現中文變成“?”很可能就是錯誤的使用了 ISO-8859-1 這個編碼導致的。中文字符經過 ISO-8859-1 編碼會丟失信息,通常我們稱之為“黑洞”,它會把不認識的字符吸收掉。由於現在大部分基礎的 Java 框架或系統默認的字符集編碼都是 ISO-8859-1,所以很容易出現亂碼問題,後面將會分析不同的亂碼形式是怎麽出現的。
按照 GB2312 編碼
字符串“I am 君山”用 GB2312 編碼,下面是編碼結果: 
GB2312 對應的 Charset 是 sun.nio.cs.ext. EUC_CN 而對應的 CharsetDecoder 編碼類是 sun.nio.cs.ext. DoubleByte,GB2312 字符集有一個 char 到 byte 的碼表,不同的字符編碼就是查這個碼表找到與每個字符的對應的字節,然後拼裝成 byte 數組。查表的規則如下:
c2b[c2bIndex[char >> 8] + (char & 0xff)]
如果查到的碼位值大於 oxff 則是雙字節,否則是單字節。雙字節高 8 位作為第一個字節,低 8 位作為第二個字節,如下代碼所示:
if (bb > 0xff) { // DoubleByte
if (dl - dp < 2)
return CoderResult.OVERFLOW;
da[dp++] = (byte) (bb >> 8);
da[dp++] = (byte) bb;
} else { // SingleByte
if (dl - dp < 1)
return CoderResult.OVERFLOW;
da[dp++] = (byte) bb;
}
從上圖可以看出前 5 個字符經過編碼後仍然是 5 個字節,而漢字被編碼成雙字節,在第一節中介紹到 GB2312 只支持 6763 個漢字,所以並不是所有漢字都能夠用 GB2312 編碼。
按照 GBK 編碼
字符串“I am 君山”用 GBK 編碼,下面是編碼結果: 
你可能已經發現上圖與 GB2312 編碼的結果是一樣的,沒錯 GBK 與 GB2312 編碼結果是一樣的,由此可以得出 GBK 編碼是兼容 GB2312 編碼的,它們的編碼算法也是一樣的。不同的是它們的碼表長度不一樣,GBK 包含的漢字字符更多。所以只要是經過 GB2312 編碼的漢字都可以用 GBK 進行解碼,反過來則不然。
按照 UTF-16 編碼
字符串“I am 君山”用 UTF-16 編碼,下面是編碼結果: 
用 UTF-16 編碼將 char 數組放大了一倍,單字節範圍內的字符,在高位補 0 變成兩個字節,中文字符也變成兩個字節。從 UTF-16 編碼規則來看,僅僅將字符的高位和地位進行拆分變成兩個字節。特點是編碼效率非常高,規則很簡單,由於不同處理器對 2 字節處理方式不同,Big-endian(高位字節在前,低位字節在後)或 Little-endian(低位字節在前,高位字節在後)編碼,所以在對一串字符串進行編碼是需要指明到底是 Big-endian 還是 Little-endian,所以前面有兩個字節用來保存 BYTE_ORDER_MARK 值,UTF-16 是用定長 16 位(2 字節)來表示的 UCS-2 或 Unicode 轉換格式,通過代理對來訪問 BMP 之外的字符編碼。
按照 UTF-8 編碼
字符串“I am 君山”用 UTF-8 編碼,下面是編碼結果: 
UTF-16 雖然編碼效率很高,但是對單字節範圍內字符也放大了一倍,這無形也浪費了存儲空間,另外 UTF-16 采用順序編碼,不能對單個字符的編碼值進行校驗,如果中間的一個字符碼值損壞,後面的所有碼值都將受影響。而 UTF-8 這些問題都不存在,UTF-8 對單字節範圍內字符仍然用一個字節表示,對漢字采用三個字節表示。它的編碼規則如下:
private CoderResult encodeArrayLoop(CharBuffer src,
ByteBuffer dst){
char[] sa = src.array();
int sp = src.arrayOffset() + src.position();
int sl = src.arrayOffset() + src.limit();
byte[] da = dst.array();
int dp = dst.arrayOffset() + dst.position();
int dl = dst.arrayOffset() + dst.limit();
int dlASCII = dp + Math.min(sl - sp, dl - dp);
// ASCII only loop
while (dp < dlASCII && sa[sp] < ‘\u0080‘)
da[dp++] = (byte) sa[sp++];
while (sp < sl) {
char c = sa[sp];
if (c < 0x80) {
// Have at most seven bits
if (dp >= dl)
return overflow(src, sp, dst, dp);
da[dp++] = (byte)c;
} else if (c < 0x800) {
// 2 bytes, 11 bits
if (dl - dp < 2)
return overflow(src, sp, dst, dp);
da[dp++] = (byte)(0xc0 | (c >> 6));
da[dp++] = (byte)(0x80 | (c & 0x3f));
} else if (Character.isSurrogate(c)) {
// Have a surrogate pair
if (sgp == null)
sgp = new Surrogate.Parser();
int uc = sgp.parse(c, sa, sp, sl);
if (uc < 0) {
updatePositions(src, sp, dst, dp);
return sgp.error();
}
if (dl - dp < 4)
return overflow(src, sp, dst, dp);
da[dp++] = (byte)(0xf0 | ((uc >> 18)));
da[dp++] = (byte)(0x80 | ((uc >> 12) & 0x3f));
da[dp++] = (byte)(0x80 | ((uc >> 6) & 0x3f));
da[dp++] = (byte)(0x80 | (uc & 0x3f));
sp++; // 2 chars
} else {
// 3 bytes, 16 bits
if (dl - dp < 3)
return overflow(src, sp, dst, dp);
da[dp++] = (byte)(0xe0 | ((c >> 12)));
da[dp++] = (byte)(0x80 | ((c >> 6) & 0x3f));
da[dp++] = (byte)(0x80 | (c & 0x3f));
}
sp++;
}
updatePositions(src, sp, dst, dp);
return CoderResult.UNDERFLOW;
}
UTF-8 編碼與 GBK 和 GB2312 不同,不用查碼表,所以在編碼效率上 UTF-8 的效率會更好,所以在存儲中文字符時 UTF-8 編碼比較理想。
幾種編碼格式的比較
對中文字符後面四種編碼格式都能處理,GB2312 與 GBK 編碼規則類似,但是 GBK 範圍更大,它能處理所有漢字字符,所以 GB2312 與 GBK 比較應該選擇 GBK。UTF-16 與 UTF-8 都是處理 Unicode 編碼,它們的編碼規則不太相同,相對來說 UTF-16 編碼效率最高,字符到字節相互轉換更簡單,進行字符串操作也更好。它適合在本地磁盤和內存之間使用,可以進行字符和字節之間快速切換,如 Java 的內存編碼就是采用 UTF-16 編碼。但是它不適合在網絡之間傳輸,因為網絡傳輸容易損壞字節流,一旦字節流損壞將很難恢復,想比較而言 UTF-8 更適合網絡傳輸,對 ASCII 字符采用單字節存儲,另外單個字符損壞也不會影響後面其它字符,在編碼效率上介於 GBK 和 UTF-16 之間,所以 UTF-8 在編碼效率上和編碼安全性上做了平衡,是理想的中文編碼方式。
Java Web 涉及到的編碼
對於使用中文來說,有 I/O 的地方就會涉及到編碼,前面已經提到了 I/O 操作會引起編碼,而大部分 I/O 引起的亂碼都是網絡 I/O,因為現在幾乎所有的應用程序都涉及到網絡操作,而數據經過網絡傳輸都是以字節為單位的,所以所有的數據都必須能夠被序列化為字節。在 Java 中數據被序列化必須繼承 Serializable 接口。
這裏有一個問題,你是否認真考慮過一段文本它的實際大小應該怎麽計算,我曾經碰到過一個問題:就是要想辦法壓縮 Cookie 大小,減少網絡傳輸量,當時有選擇不同的壓縮算法,發現壓縮後字符數是減少了,但是並沒有減少字節數。所謂的壓縮只是將多個單字節字符通過編碼轉變成一個多字節字符。減少的是 String.length(),而並沒有減少最終的字節數。例如將“ab”兩個字符通過某種編碼轉變成一個奇怪的字符,雖然字符數從兩個變成一個,但是如果采用 UTF-8 編碼這個奇怪的字符最後經過編碼可能又會變成三個或更多的字節。同樣的道理比如整型數字 1234567 如果當成字符來存儲,采用 UTF-8 來編碼占用 7 個 byte,采用 UTF-16 編碼將會占用 14 個 byte,但是把它當成 int 型數字來存儲只需要 4 個 byte 來存儲。所以看一段文本的大小,看字符本身的長度是沒有意義的,即使是一樣的字符采用不同的編碼最終存儲的大小也會不同,所以從字符到字節一定要看編碼類型。
另外一個問題,你是否考慮過,當我們在電腦中某個文本編輯器裏輸入某個漢字時,它到底是怎麽表示的?我們知道,計算機裏所有的信息都是以 01 表示的,那麽一個漢字,它到底是多少個 0 和 1 呢?我們能夠看到的漢字都是以字符形式出現的,例如在 Java 中“淘寶”兩個字符,它在計算機中的數值 10 進制是 28120 和 23453,16 進制是 6bd8 和 5d9d,也就是這兩個字符是由這兩個數字唯一表示的。Java 中一個 char 是 16 個 bit 相當於兩個字節,所以兩個漢字用 char 表示在內存中占用相當於四個字節的空間。
這兩個問題搞清楚後,我們看一下 Java Web 中那些地方可能會存在編碼轉換?
用戶從瀏覽器端發起一個 HTTP 請求,需要存在編碼的地方是 URL、Cookie、Parameter。服務器端接受到 HTTP 請求後要解析 HTTP 協議,其中 URI、Cookie 和 POST 表單參數需要解碼,服務器端可能還需要讀取數據庫中的數據,本地或網絡中其它地方的文本文件,這些數據都可能存在編碼問題,當 Servlet 處理完所有請求的數據後,需要將這些數據再編碼通過 Socket 發送到用戶請求的瀏覽器裏,再經過瀏覽器解碼成為文本。這些過程如下圖所示: 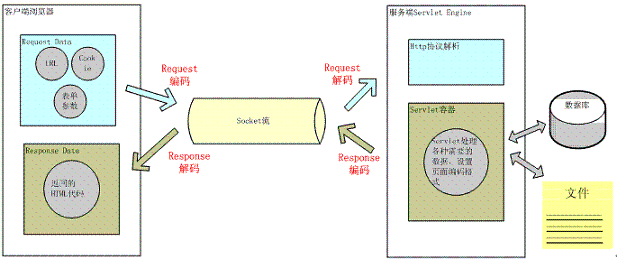
如上圖所示一次 HTTP 請求設計到很多地方需要編解碼,它們編解碼的規則是什麽?下面將會重點闡述一下:
URL 的編解碼
用戶提交一個 URL,這個 URL 中可能存在中文,因此需要編碼,如何對這個 URL 進行編碼?根據什麽規則來編碼?有如何來解碼?如下圖一個 URL:
圖 4.URL 的幾個組成部分 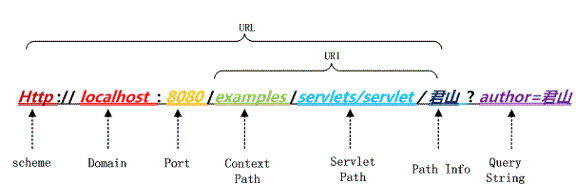
上圖中以 Tomcat 作為 Servlet Engine 為例,它們分別對應到下面這些配置文件中:
Port 對應在 Tomcat 的 <Connector port="8080"/> 中配置,而 Context Path 在 <Context path="/examples"/> 中配置,Servlet Path 在 Web 應用的 web.xml 中的
<servlet-mapping>
<servlet-name>junshanExample</servlet-name>
<url-pattern>/servlets/servlet/*</url-pattern>
</servlet-mapping>
<url-pattern> 中配置,PathInfo 是我們請求的具體的 Servlet,QueryString 是要傳遞的參數,註意這裏是在瀏覽器裏直接輸入 URL 所以是通過 Get 方法請求的,如果是 POST 方法請求的話,QueryString 將通過表單方式提交到服務器端,這個將在後面再介紹。
上圖中 PathInfo 和 QueryString 出現了中文,當我們在瀏覽器中直接輸入這個 URL 時,在瀏覽器端和服務端會如何編碼和解析這個 URL 呢?為了驗證瀏覽器是怎麽編碼 URL 的我們選擇 FireFox 瀏覽器並通過 HTTPFox 插件觀察我們請求的 URL 的實際的內容,以下是 URL:HTTP://localhost:8080/examples/servlets/servlet/ 君山 ?author= 君山在中文 FireFox3.6.12 的測試結果 
Java幾種常見的編碼方式