
深度學習的異構加速技術(二):螺獅殼裏做道場
作者簡介:kevinxiaoyu,高級研究員,隸屬騰訊TEG-架構平臺部,主要研究方向為深度學習異構計算與硬件加速、FPGA雲、高速視覺感知等方向的構架設計和優化。“深度學習的異構加速技術”系列共有三篇文章,主要在技術層面,對學術界和工業界異構加速的構架演進進行分析。
一、綜述
在“深度學習的異構加速技術(一)”一文所述的AI加速平臺的第一階段中,無論在FPGA還是ASIC設計,無論針對CNN還是LSTM與MLP,無論應用在嵌入式終端還是雲端(TPU1),其構架的核心都是解決帶寬問題。不解決帶寬問題,空有計算能力,利用率卻提不上來。就像一個8核CPU,若其中一個內核就將內存帶寬100%占用,導致其他7個核讀不到計算所需的數據,將始終處於閑置狀態。對此,學術界湧現了大量文獻從不同角度對帶寬問題進行討論,可歸納為以下幾種:
A、流式處理與數據復用
B、片上存儲及其優化
C、位寬壓縮
D、稀疏優化
E、片上模型與芯片級互聯
F、新興技術:二值網絡、憶阻器與HBM
下面對上述方法如何解決帶寬問題,分別論述。
二、不同招式的PK與演進
2.1、流式處理與數據復用
流式處理是應用於FPGA和專用ASIC高效運算結構,其核心是基於流水線的指令並行,即當前處理單元的結果不寫回緩存,而直接作為下一級處理單元的輸入,取代了當前處理單元結果回寫和下一處理單元數據讀取的存儲器訪問。多核CPU和GPU多采用數據並行構架,與流式處理構架的對比如圖2.1所示。圖左為數據並行的處理方式,所有運算單元受控於一個控制模塊,統一從緩存中取數據進行計算,計算單元之間不存在數據交互。當眾多計算單元同時讀取緩存,將產生帶寬競爭造成瓶頸;圖右為基於指令並行的二維流式處理,即每個運算單元都有獨立的指令(即定制運算邏輯),數據從相鄰計算單元輸入,並輸出到下一級計算單元,只有與存儲相鄰的一側存在數據交互,從而大大降低了對存儲帶寬的依賴,代表為FPGA和專用ASIC的定制化設計。
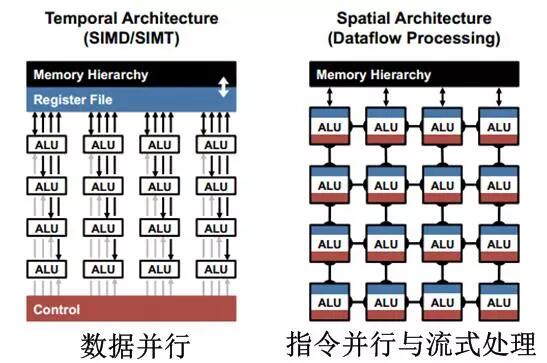
圖2.1 數據並行與流式處理的對比
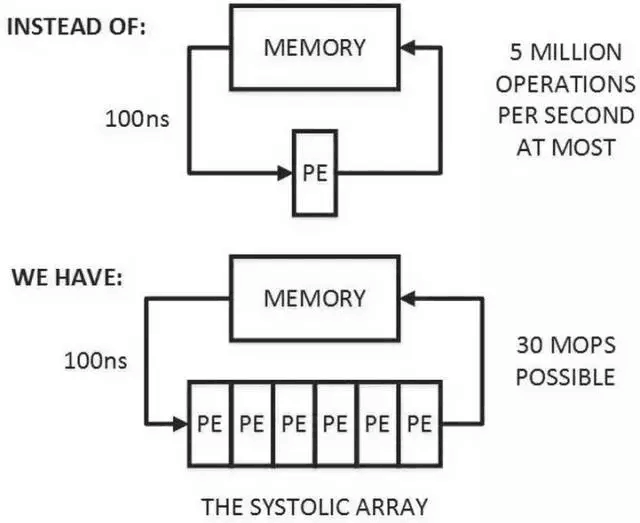
圖2.2 一維脈動陣列(上)TPU中的二維脈動陣列(下)
當流式處理中各個處理單元(Processing Element, PE)具有相同結構時,有一個專屬名稱——脈動矩陣,一維的脈動矩陣如圖2.2(上)所示。當一個處理單元從存儲器讀取數據處理,經過若幹同構PE處理後寫回到存儲器。對存儲器而言,只需滿足單PE的讀寫帶寬即可,降低了數據存取頻率。脈動架構的思想很簡單:讓數據盡量在處理單元中多流動一段時間。當一個數據從第一個PE輸入直至到達最後一個PE,它已經被處理了多次。因此,它可以在小帶寬下實現高吞吐[1]。
TPU中采用的二維脈動陣列如圖2.2(下)所示,用以實現矩陣-矩陣乘和向量-矩陣乘。數據分別從Cell陣列的上側和左側流入,從下側流出。每個Cell是一個乘加單元,每個周期完成一次乘法和一次加法。當使用該脈動陣列做卷積運算時,二維FeatureMap需要展開成一維向量,同時Kernel經過旋轉,而後輸入,如TPU專利中的圖2.3所示。

圖2.3 TPU專利中,脈動陣列在卷積運算時的數據重排
在極大增加數據復用的同時,脈動陣列也有兩個缺點,即數據重排和規模適配。第一,脈動矩陣主要實現向量/矩陣乘法。以CNN計算為例,CNN數據進入脈動陣列需要調整好形式,並且嚴格遵循時鐘節拍和空間順序輸入。數據重排的額外操作增加了復雜性,據推測由軟件驅動實現。第二,在數據流經整個陣列後,才能輸出結果。當計算的向量中元素過少,脈動陣列規模過大時,不僅難以將陣列中的每個單元都利用起來,數據的導入和導出延時也隨著尺寸擴大而增加,降低了計算效率。因此在確定脈動陣列的規模時,在考慮面積、能耗、峰值計算能力的同時,還要考慮典型應用下的效率。
寒武紀的DianNao系列芯片構架也采用了流式處理的乘加樹(DianNao[2]、DaDianNao[3]、PuDianNao[4])和類脈動陣列的結構(ShiDianNao[5])。為了兼容小規模的矩陣運算並保持較高的利用率,同時更好的支持並發的多任務,DaDianNao和PuDianNao降低了計算粒度,采用了雙層細分的運算架構,即在頂層的PE陣列中,每個PE由更小規模的多個運算單元構成,更細致的任務分配和調度雖然占用了額外的邏輯,但有利於保證每個運算單元的計算效率並控制功耗,如圖2.4所示。
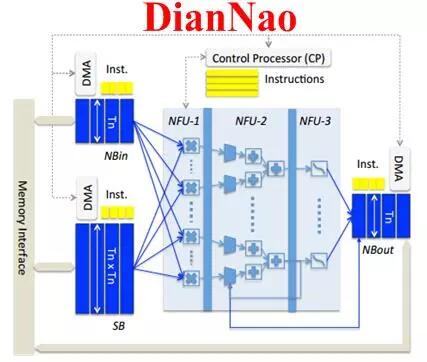
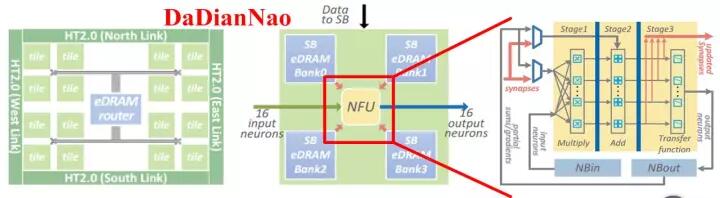
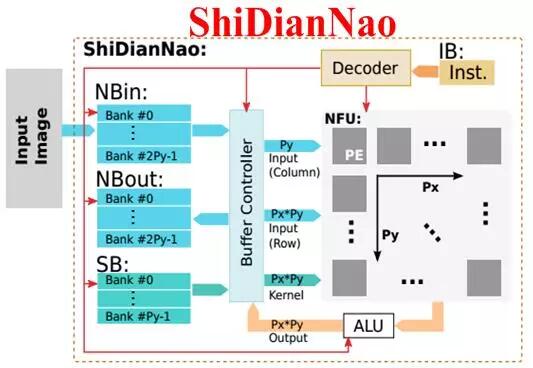
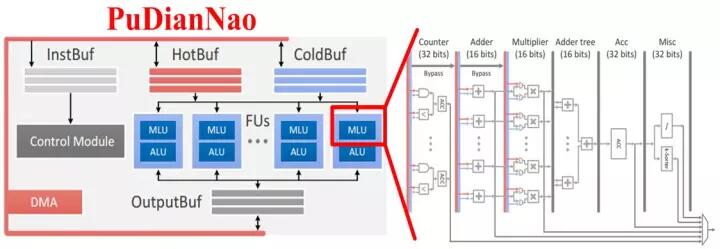
圖2.4 基於流式處理的計算單元組織結構:從上到下依次為DianNao、DaDianNao整體框架與處理單元、ShiDianNao、PuDianNao的總體框圖和每個MLU處理單元的內部結構
除了采用流式處理減少PE對輸入帶寬的依賴,還可通過計算中的數據復用降低帶寬,CNN中的復用方式如圖2.5所示。
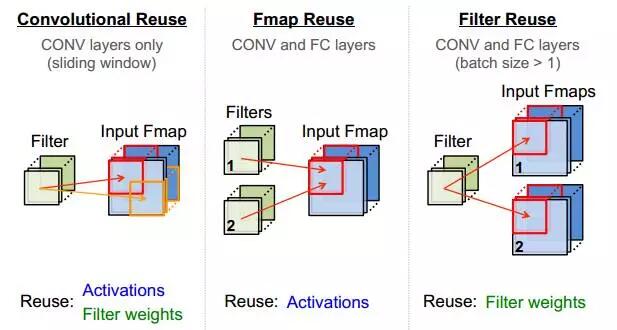 | 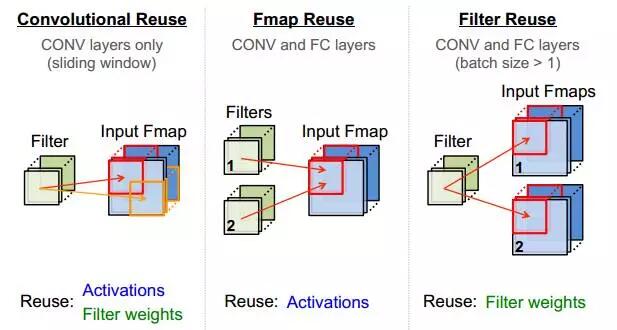 | 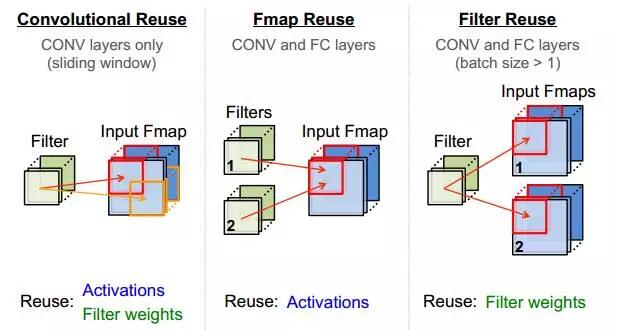 |
|---|---|---|
| (a) | (b) | (c) |
圖2.5 CNN中的數據復用
在圖2.5 的(a) (b)(c)分別對應卷積核的整張FeatureMap復用、一組FeatureMap對多組Filter的復用、Filter通過增加BatchSize而復用。當上述三種方式結合使用時,可極大提升數據復用率,這也是TPU在處理CNN時逼近峰值算力,達到86Tops/s的原因之一。
2.2、片上存儲及其優化
片外存儲器(如DDR等)具有容量大的優勢,然而在ASIC和FPGA設計中,DRAM的使用常存在兩個問題,一是帶寬不足,二是功耗過大。由於需要高頻驅動IO,DRAM的訪問能耗通常是單位運算的200倍以上,DRAM訪問與其它操作的能耗對比如圖2.6所示。
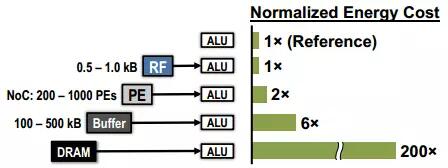
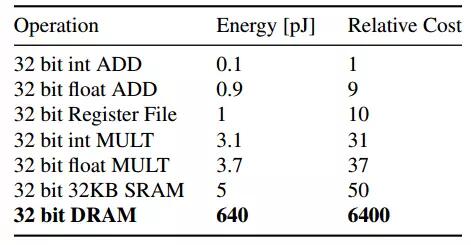
圖2.6 片外DRAM訪問的能耗開銷
為了解決帶寬和能耗問題,通常采用兩種方式:片上緩存和臨近存儲。
1)增加片上緩存,有利於在更多情況下增加數據復用。例如矩陣A和B相乘時,若B能全部存入緩存,則僅加載B一次,復用次數等價於A的行數;若緩存不夠,則需多次加載,增加帶寬消耗。當片上緩存足夠大,可以存下所有計算所需的數據,或通過主控處理器按需發送數據,即可放棄片外DRAM,極大降低功耗和板卡面積,這也是半導體頂會ISSCC2016中大部分AI ASIC論文采用的方案。
2)臨近存儲。當從片上緩存加載數據時,若采用單一的片上存儲,其接口經常不能滿足帶寬的需求,集中的存儲和較長的讀寫路徑也會增加延遲。此時可以增加片上存儲的數量並將其分布於計算單元數據接口的臨近位置,使計算單元可以獨享各自的存儲器帶寬。隨著數量的增加,片上存儲的總帶寬也隨之增加,如圖2.7所示。
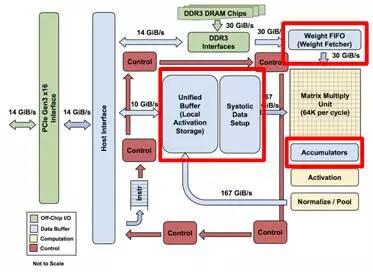
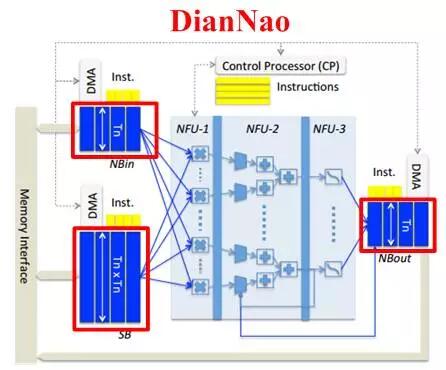
圖2.7 TPU(上)和DianNao(下)的片上存儲器分布
圖2.7中的脈動陣列和乘加樹都是規模較大的計算單元,屬於粗粒度。當采用細粒度計算單元的結構時,如圖2.8所示,可采用分層級存儲方式,即除了在片上配置共享緩存之外,在每個計算單元中也配置專屬存儲器,使計算單元獨享其帶寬並減少對共享緩存的訪問。寒武紀的DaDianNao采用也是分層級存儲,共三層構架,分別配置了中央存儲器,四塊環形分布存儲器,和輸入輸出存儲器,如圖2.9所示,極大增強了片上的存儲深度和帶寬,輔以芯片間的互聯總線,可將整個模型放在片上,實現片上Training和Inference。
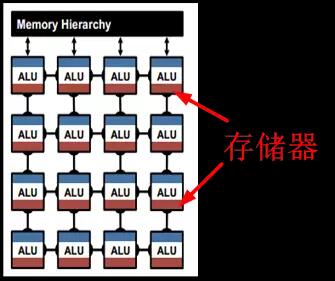
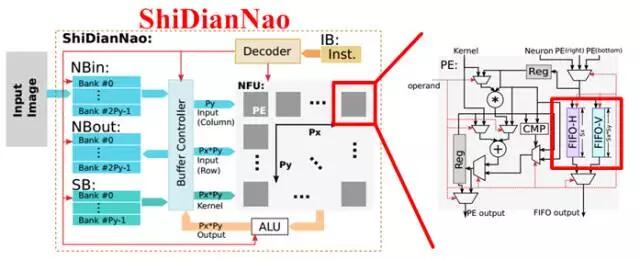
圖2.8 細粒度計算單元與鄰近存儲,上圖中深紅色為存儲器
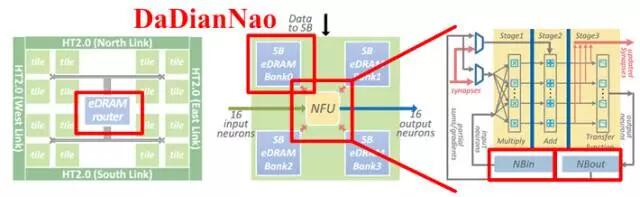
圖2.9DaDianNao的計算單元與存儲器分布
2.3、位寬壓縮
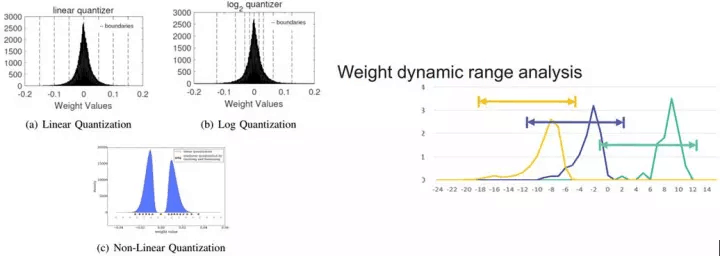
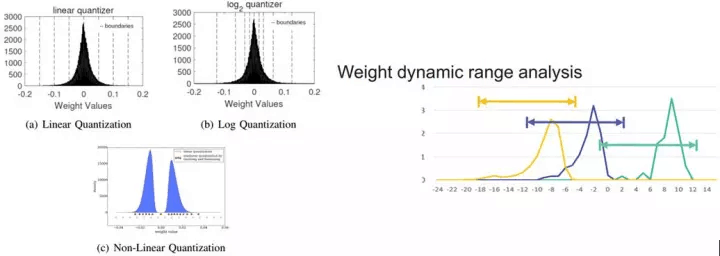
在兩年前,深度學習的定制處理器構架還處於初始階段,在Inference中繼承了CPU和GPU的32bit浮點量化,每次乘法運算不僅需要12字節的讀寫(8bit量化時為3字節),32位運算單元占用較大的片上面積,增加了能耗和帶寬消耗。PuDianNao的論文中指出[4],16bit乘法器在ASIC占用面積上是32bit乘法器的1/5,即在相同尺寸的面積上可布局5倍數量的乘法器。當使用8bit時將獲得更高收益。因此,學術界孜孜不倦的追求更低的量化精度,從16bit,到自定義的9bit[6],8bit,甚至更激進的2bit和1bit的二值網絡[7-8]。當高位寬轉為低位寬的量化時,不可避免的帶來精度損失。對此,可通過量化模式、表征範圍的調整、編碼等方式、甚至增加模型深度(二值網絡)來降低對精度的影響,其中量化模式、表征範圍的調整方法如圖2.10 所示。
 |  |
|---|---|
| (a) | (b) |
圖2.10 (a) 幾種量化模式,和 (b) 動態位寬調整
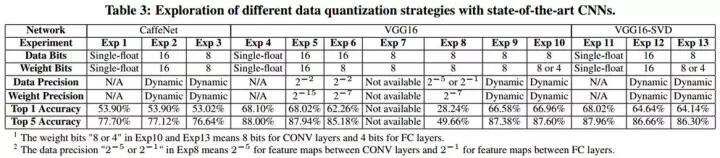
圖2.10 (a) 中為不同的量化模式,同樣的8bit,可根據模型中數值的分布情況采用為線性量化、Log量化、或非線性量化表示。圖2.10 (b)是Jiantao Qiu等提出的動態位寬調整[9],使8bit的量化在不同層之間使用不同的偏移量和整數、小數分配,從而在最小量化誤差的約束下動態調整量化範圍和精度,結合重訓練,可大幅降低低位寬帶來的影響。在CNN模型中的測試結果見下表:
低位寬意味著在處理相同的任務時更小的算力、帶寬和功耗消耗。在算力不變的前提下,成倍的增加吞吐。對於數據中心,可大幅度降低運維成本,使用更少的服務器或更廉價的計算平臺即可滿足需求(TPU的數據類型即為8/16bit);對於更註重能耗比和小型化嵌入式前端,可大幅降低成本。目前,8bit的量化精度已經得到工業界認可,GPU也宣布在硬件上提供對8bit的支持,從而將計算性能提高近4倍,如圖2.11所示。FPGA巨頭Xilinx也在AI加速的官方文檔中論述了8bit量化的可行性[10]。
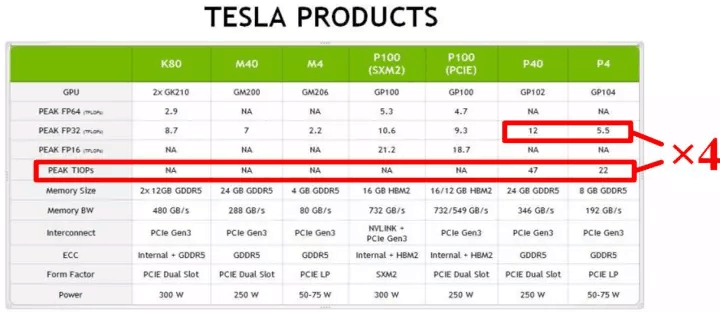
圖2.11 NVIDIA對int8的支持
2.4、稀疏優化
上述的論述主要針對稠密矩陣計算。在實際應用中,有很大一部分AI應用和矩陣運算屬於稀疏運算,其主要來源於兩個方面:
1) 算法本身存在稀疏。如NLP(Natural Language Processing,自然語言處理)、推薦算法等應用中,通常一個幾萬維的向量中,僅有幾個非零元素,統統按照稠密矩陣處理顯然得不償失。
2) 算法改造成稀疏。為了增加普適性,深度學習的模型本身存在冗余。在針對某一應用完成訓練後,很多參數的貢獻極低,可以通過剪枝和重新訓練將模型轉化為稀疏。如深鑒科技的韓松在FPGA2017上提出針對LSTM的模型剪枝和專用的稀疏化處理架構,如圖2.12 所示[11]。
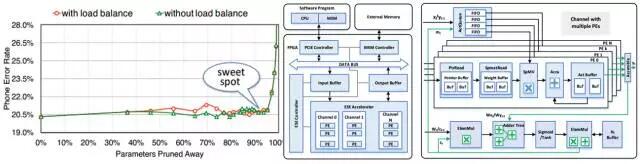
圖2.12 LSTM模型剪枝比例與精度(左)和稀疏處理構架(右)
圖2.12 左圖,為LSTM模型剪枝掉90%的參數後,基本沒有精度損失,模型得到了極大的稀疏化。圖右側為針對稀疏的FPGA處理構架,將處理的PE之間進行異步調度,在每個PE的數據入口使用獨立的數據緩存,僅將非零元素壓入參與計算,獲得了3倍於Pascal Titan X的性能收益和11.5倍的功耗收益。稀疏化並不僅限於LSTM,在CNN上也有對應的應用。
與之對應的,寒武紀也開發了針對稀疏神經網絡的Cambricon-X[12]處理器,如圖2.13所示。類似的,Cambricon-X也在每個PE的輸入端口加入了Indexing的步驟,將非零元素篩選出後再輸入進PE。與深鑒不同的是,Cambricon-X支持不同稀疏程度的兩種indexing編碼,在不同稀疏程度的模型下使用不同的編碼方式,以優化帶寬消耗。
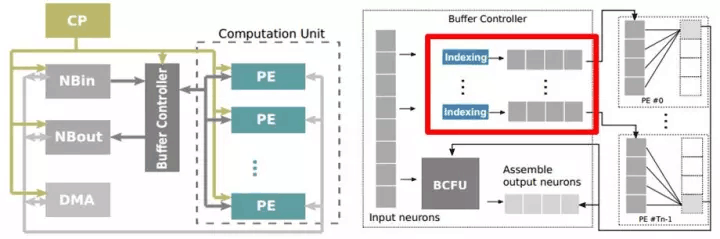
圖2.13 寒武紀Cambricon-X稀疏神經網絡處理器結構
可針對稀疏的優化有兩個目的,一是從緩存中讀入的都是有效數據從而避免大量無用的零元素占滿帶寬的情況,二是保證片上PE的計算效率,使每個PE的每次計算的輸入都是“幹貨”。當模型剪枝結合稀疏處理構架,將成倍提升FPGA和ASIC的計算能力,效果顯著,是異構加速的熱點之一。
綜上所述,稀疏化是從模型角度,從根本上減少計算量,在構架演進缺乏突破的情況下,帶來的收益是構架優化所不能比擬的。尤其在結合位寬壓縮後,性能提升非常顯著。然而稀疏化需要根據構架特點,且會帶來精度損失,需要結合模型重訓練來彌補,反復調整。上述過程增加了稀疏優化的門檻,需要算法開發和硬件優化團隊的聯合協作。對此,深鑒科技等一些公司推出稀疏+重訓練的專用工具,簡化了這一過程,在大量部署的場景下,將帶來相當的成本優勢。
2.5、片上模型與芯片級互聯
為了解決帶寬問題,通常的做法是增加數據復用。在每次計算的兩個值中,一個是權值Weight,一個是輸入Activation。如果有足夠大的片上緩存,結合適當的位寬壓縮方法,將所有Weight都緩存在片上,每次僅輸入Activation,就可以在優化數據復用之前就將帶寬減半。然而從GoogleNet50M到ResNet 150M的參數數量,在高成本的HBM普及之前,ASIC在相對面積上無法做到如此大的片上存儲。而隨著模型研究的不斷深入,更深、參數更多的模型還會繼續出現。對此,基於芯片級互聯和模型拆分的處理模式,結合多片互聯技術,將多組拆分層的參數配置於多個芯片上,在Inference過程中用多芯片共同完成同一任務的處理。寒武紀的DaDianNao就是實現這樣的一種芯片互聯結合大緩存的設計,如圖2.14所示。
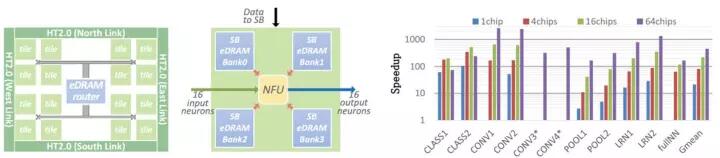
圖2.14DaDianNao中的存儲器分布(圖中藍色部分)和多片互聯時的加速能力(以GPU K20M為單位性能的比較)
為了將整個模型放在片上,DaDianNao一方面將片上緩存的容量增加到36MB(DaDianNao為36MB和4608個乘加器,TPU為28MB緩存和65536乘加器),充分保證計算單元的讀寫帶寬,另一方面通過HT2.0實現6.4GB/s*4通道的片間通信帶寬,降低數據才層與層之間傳遞的延遲,完全取代了片外DRAM的交互,解決帶寬制約計算的問題。與之相應的,微軟在Hot Chips 2017上提出將LSTM模型拆分後部署到多片FPGA,以擺脫片外存儲器訪問以實現Inference下的超低延遲[2]。
2.6、新興技術:二值網絡、憶阻器與HBM
除了采用上述方式解決帶寬問題,學術界近期湧現出了兩種更為激進的方法,二值網絡和憶阻器;工業界在存儲器技術上也有了新的突破,即HBM。
二值網絡是將Weight和Activation中的一部分,甚至全部轉化為1bit,將乘法簡化為異或等邏輯運算,大大降低帶寬,非常適合DSP資源有限而邏輯資源豐富的FPGA,以及可完全定制的ASIC。相對而言,GPU的計算單元只能以32/16/8bit為單位進行運算,即使運行二值模型,加速效果也不會比8bit模型快多少。因此,二值網絡成為FPGA和ASIC在低功耗嵌入式前端應用的利器。目前二值網絡的重點還在模型討論階段,討論如何通過增加深度與模型調整來彌補二值後的精度損失。在簡單的數據集下的效果已得到認可,如MNIST,Cifar-10等。
既然帶寬成為計算瓶頸,那麽有沒有可能把計算放到存儲器內部呢?既然計算單元臨近存儲的構架能提升計算效率,那麽能否把計算和存儲二者合一呢?憶阻器正是實現存儲器內部計算的一種器件,通過電流、電壓和電導的乘法關系,在輸入端加入對應電壓,在輸出即可獲得乘加結果,如圖2.15所示[13]。當將電導作為可編程的Weight值,輸入作為Activation,即可實現神經網絡計算。目前在工藝限制下,8bit的可編程電導技術還不成熟,但在更低量化精度下尚可。將存儲和計算結合,將形成一種有別於馮諾依曼體系的全新型構架,稱為在存儲計算(In-Memory Computing),有著巨大的想象空間。
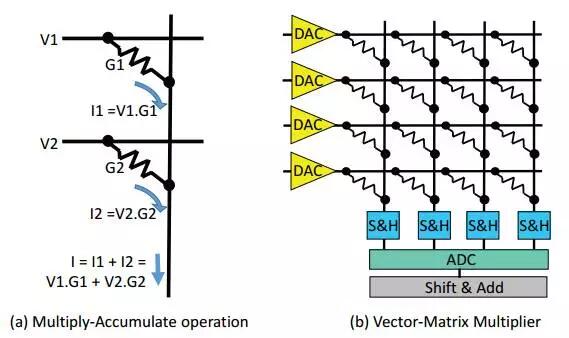
圖2.15 憶阻器完成乘加示意圖(左)與向量-矩陣運算(右)
隨著工業界芯片制造技術的發展與摩爾定律的逐漸失效,簡單通過提升工藝制程來在面積不變的條件下增加晶體管數量的方式已經逐漸陷入瓶頸。相應的,二維技術的局限使工藝向第三維度邁進。例如在存儲領域,3D構架和片內垂直堆疊技術可在片上成倍增加緩存容量,其代表為高帶寬存儲器(HighBandwidth Memory,HBM)和混合存儲器立方體(HybridMemory Cube,HMC)。據Intel透露,Lake Crest的片上HBM2可提供最高12倍於DDR4的帶寬。目前,NVIDIAP100和V100 GPU已集成HBM2,片內帶寬高達900GB/s;TPU2的片內HBM帶寬為600GB/s;Xilinx集成HBM的FPGA將在18年上市。這一技術革新使得對於當前的深度學習模型,即使不采用芯片級互聯方案也有望將整個模型置於片上,釋放了FPGA/ASIC對片外DRAM的需求,為AI芯片發展提供巨大動力。
三、結語
上面的論述主要以當前學術界在AI處理器構架方面的討論為主。然而在工業界,AI的大量需求已經在某些領域集中爆發,如雲服務、大數據處理、安防、手機端應用等。甚至在一些應用中已經落地,如Google的TPU,華為的麒麟970等。AI處理器的發展和現狀如何?我們下期見!
參考文獻
[1] 唐杉, 脈動陣列-因Google TPU獲得新生. http://mp.weixin.qq.com/s/g-BDlvSy-cx4AKItcWF7jQ
[2] Chen Y, Chen Y, Chen Y, et al.DianNao: a small-footprint high-throughput accelerator for ubiquitousmachine-learning[C]// International Conference on Architectural Support forProgramming Languages and Operating Systems. ACM, 2014:269-284.
[3] Luo T, Luo T, Liu S, et al.DaDianNao: A Machine-Learning Supercomputer[C]// Ieee/acm InternationalSymposium on Microarchitecture. IEEE, 2015:609-622.
[4] Liu D, Chen T, Liu S, et al.PuDianNao: A Polyvalent Machine Learning Accelerator[C]// TwentiethInternational Conference on Architectural Support for Programming Languages andOperating Systems. ACM, 2015:369-381.
[5] Du Z, Fasthuber R, Chen T, et al.ShiDianNao: shifting vision processing closer to the sensor[C]// ACM/IEEE,International Symposium on Computer Architecture. IEEE, 2015:92-104.
[6] Eric Chung, Jeremy Fowers, KalinOvtcharov, et al. Accelerating Persistent Neural Networks at Datacenter Scale.Hot Chips 2017.
[7] Meng W, Gu Z, Zhang M, et al.Two-bit networks for deep learning on resource-constrained embedded devices[J].arXiv preprint arXiv:1701.00485, 2017.
[8] Hubara I, Courbariaux M, SoudryD, et al. Binarized neural networks[C]//Advances in neural informationprocessing systems. 2016: 4107-4115.
[9] Qiu J, Wang J, Yao S, et al.Going deeper with embedded fpga platform for convolutional neuralnetwork[C]//Proceedings of the 2016 ACM/SIGDA International Symposium onField-Programmable Gate Arrays. ACM, 2016: 26-35.
[10] Xilinx, Deep Learningwith INT8Optimizationon Xilinx Devices, https://www.xilinx.com/support/documentation/white_papers/wp486-deep-learning-int8.pdf
[11] Han S, Kang J, Mao H, et al.Ese: Efficient speech recognition engine with compressed lstm on fpga[J]. arXivpreprint arXiv:1612.00694, 2016.
[12] Zhang S, Du Z, Zhang L, et al. Cambricon-X: An accelerator for sparseneural networks[C]// Ieee/acm International Symposium on Microarchitecture.IEEE Computer Society, 2016:1-12.
[13] Shafiee A, Nag A, MuralimanoharN, et al. ISAAC: A convolutional neural network accelerator with in-situ analogarithmetic in crossbars[C]//Proceedings of the 43rd International Symposium onComputer Architecture. IEEE Press, 2016: 14-26.
相關閱讀
一站式滿足電商節雲計算需求的秘訣騰訊雲批量計算:用搭積木的方式構建高性能計算系統
「騰訊雲遊戲開發者技術沙龍」11月24 日深圳站報名開啟 暢談遊戲加速 此文已由作者授權騰訊雲技術社區發布,轉載請註明文章出處 原文鏈接:https://cloud.tencent.com/community/article/581797深度學習的異構加速技術(二):螺獅殼裏做道場