
深度學習—加快梯度下降收斂速度(二):Monmentum、RMSprop、Adam
阿新 • • 發佈:2019-02-15
上篇部落格講的是利用處理(分組資料集)訓練資料集的方法,加快梯度下降法收斂速度,本文將介紹如何通過處理梯度的方法加快收斂速度。首先介紹Monmentum,再次介紹RMSprop,最後介紹兩種演算法的綜合體Adam。
1.Monmentum
在介紹Monmentum之前,首先介紹加權平均法。加入給出一組資料的散點圖,要求用一條曲線儘可能準確地描述散點圖的趨勢,如下圖所示(圖來自吳恩達課件):
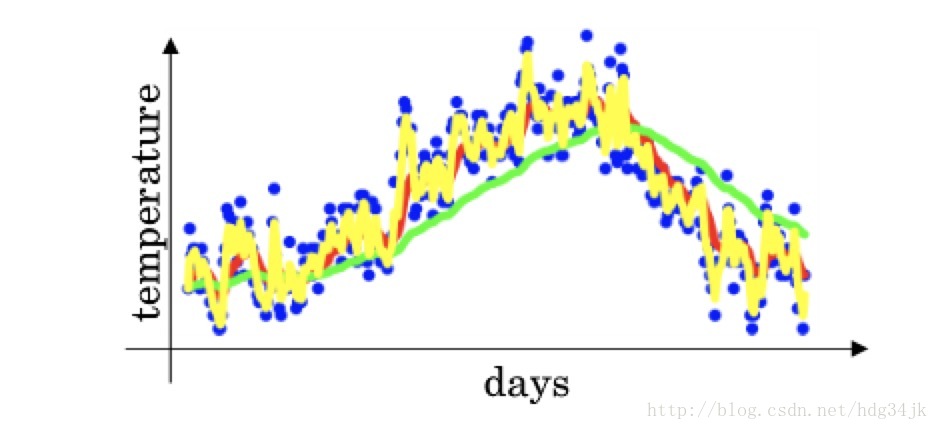
描述時利用加權平均:
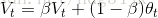
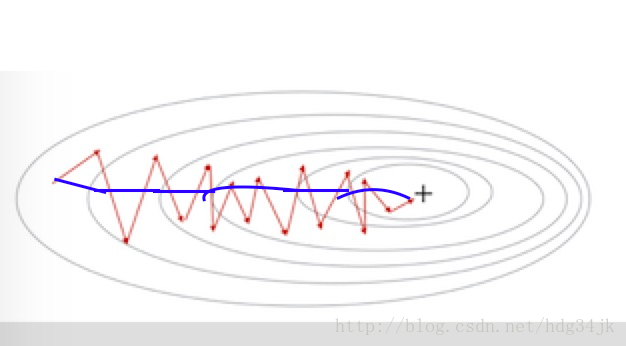
通過控制β的大小,控制曲線的平滑度,通常取β=0.9。如果將mini-batch梯度加權平均,則,mini-batch收斂曲線(藍線)將會更加平滑,在橫軸方向走的更快:
在曲線開頭階段,不能準確的描述散點圖,需要將偏差修正:
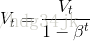
Monmentum具體加權平均過程:
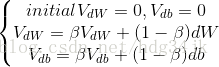
加權平均之後,再利用加權平均的結果更新引數:
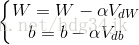
2.RMSprop
RMSprop具體操作如下:
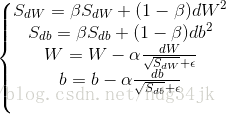
3.Adam
Adam是Monmentum與RMSprop的結合演算法,具體如下:

在做訓練時,可以將上述方法加入到迭代裡面。求得梯度之後,便利用monmentum或RMSprop或Adam方法求得梯度的變體,然後利用該變體更新引數即可。