
SQL : IN 和 Exists 的區別
表展示
首先,查詢中涉及到的兩個表,一個user和一個order表,具體表的內容如下:
user表:
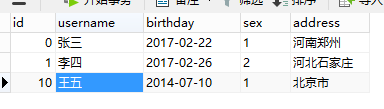
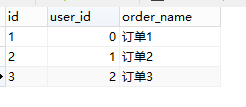
order表:
in
確定給定的值是否與子查詢或列表中的值相匹配。in在查詢的時候,首先查詢子查詢的表,然後將內表和外表做一個笛卡爾積,然後按照條件進行篩選。所以相對內表比較小的時候,in的速度較快。
具體sql語句如下:
SELECT *
FROM
user
WHERE
user.id IN (
SELECT
order.user_id
FROM
order
)
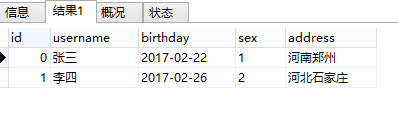
這條語句很簡單,通過子查詢查到的user_id 的數據,去匹配user表中的id然後得到結果。該語句執行結果如下:

它的執行流程是什麽樣子的呢?讓我們一起來看一下。
首先,在數據庫內部,查詢子查詢,執行如下代碼:
SELECT
order.user_id
FROM
order
執行完畢後,得到結果如下:

此時,將查詢到的結果和原有的user表做一個笛卡爾積,結果如下:
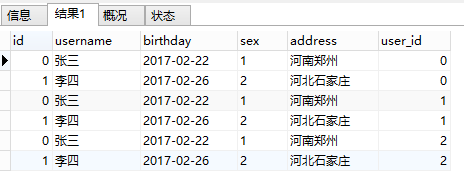
此時,再根據我們的user.id IN order.user_id的條件,將結果進行篩選(既比較id列和user_id 列的值是否相等,將不相等的刪除)。最後,得到兩條符合條件的數據。
exists
指定一個子查詢,檢測行的存在。遍歷循環外表,然後看外表中的記錄有沒有和內表的數據一樣的。匹配上就將結果放入結果集中。
具體sql語句如下:
SELECT*
FROM
user
WHERE
EXISTS (
SELECT
order.user_id
FROM
order
WHERE
user.id = order.user_id
)
這條sql語句的執行結果和上面的in的執行結果是一樣的。

但是,不一樣的是它們的執行流程完全不一樣:
使用exists關鍵字進行查詢的時候,首先,我們先查詢的不是子查詢的內容,而是查我們的主查詢的表,也就是說,我們先執行的sql語句是:
SELECT `user`.* FROM `user`
得到的結果如下:

然後,根據表的每一條記錄,執行以下語句,依次去判斷where後面的條件是否成立:
EXISTS (
SELECT
order.user_id
FROM
order
WHERE
user.id = order.user_id
)
如果成立則返回true不成立則返回false。如果返回的是true的話,則該行結果保留,如果返回的是false的話,則刪除該行,最後將得到的結果返回。
區別及應用場景
in 和 exists的區別: 如果子查詢得出的結果集記錄較少,主查詢中的表較大且又有索引時應該用in, 反之如果外層的主查詢記錄較少,子查詢中的表大,又有索引時使用exists。其實我們區分in和exists主要是造成了驅動順序的改變(這是性能變化的關鍵),如果是exists,那麽以外層表為驅動表,先被訪問,如果是IN,那麽先執行子查詢,所以我們會以驅動表的快速返回為目標,那麽就會考慮到索引及結果集的關系了 ,另外IN時不對NULL進行處理。
in 是把外表和內表作hash 連接,而exists是對外表作loop循環,每次loop循環再對內表進行查詢。一直以來認為exists比in效率高的說法是不準確的。
not in 和not exists
如果查詢語句使用了not in 那麽內外表都進行全表掃描,沒有用到索引;而not extsts 的子查詢依然能用到表上的索引。所以無論那個表大,用not exists都比not in要快。
SQL : IN 和 Exists 的區別