
爬蟲:網頁裏元素的xpath結構,scrapy不一定就找的到
這種情況原因是html界面關聯的js文件可能會動態修改DOM結構,這樣瀏覽器完成了動態修改DOM,在 瀏覽器上看到的DOM結構,就和後臺抓到的DOM結構不通
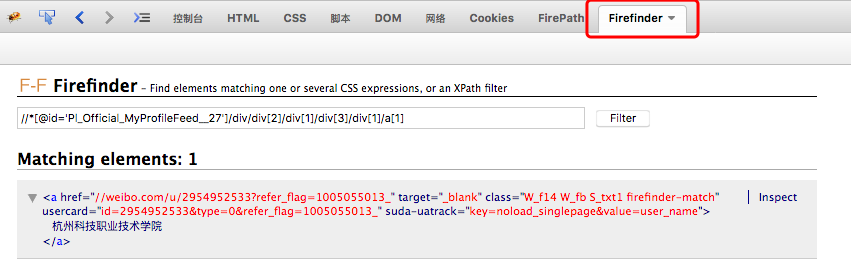
舉例:新浪微博發的微博,在瀏覽器通過firebug的插件FirePath可以很容易計算出xpath

通過Firefinder可以查看xpath的匹配情況
但是查看頁面的源代碼,可以發現,微博的內容都是包含在js裏的FM.view裏的,這些會被js動態生成DOM,但是抓取返回的內容都是下面這些內容,是還沒有生成DOM的

爬蟲:網頁裏元素的xpath結構,scrapy不一定就找的到
相關推薦
爬蟲:網頁裏元素的xpath結構,scrapy不一定就找的到
源代碼 發現 插件 結構 完成 網頁 分享 動態生成 http 這種情況原因是html界面關聯的js文件可能會動態修改DOM結構,這樣瀏覽器完成了動態修改DOM,在 瀏覽器上看到的DOM結構,就和後臺抓到的DOM結構不通 舉例:新浪微博發的微博,在瀏覽器通過firebug的
連結串列去重原理示意圖:改變原連結串列結構,不用新建連結串列
package interview.datastructure; import java.util.Hashtable; /** * 實現連結串列的插入和刪除結點的操作 */ public class Link_list { //定義一個結點 class Node { Node
廣州雲棲大會:阿裏雲攜手虎牙,首次落地直播行業邊緣節點及雲企業網服務
數據處理 最大的 國內 低延時 詳細 自己的 通道 能夠 images 摘要: 阿裏雲和虎牙直播在直播領域進行了長期的技術合作,特別是在邊緣計算節點取得了良好效果,共同建設了邊緣節點服務(ENS),落地直播行業“高帶寬、高並發、計算密集”的邊緣計算節點服務標準。 2018年
Python爬蟲解析網頁的三種方法,lxml、BeautifulSoup、re案例!
常用的類庫為lxml,BeautifulSoup,re(正則) 學習Python中有不明白推薦加入交流群 號:960410445 &nb
最簡單的基於Flash的流媒體示例:網頁播放器(HTTP,RTMP,HLS)
=====================================================Flash流媒體文章列表:=====================================================本文繼續上一篇文章,記錄一些基於Flas
問題:combo只顯示一個選項,其他不顯示(調整框的高度即可。)
== .com idc 普通 內容 重新 運行 padding href 解決辦法:調整框的高度即可。 轉自:http://blog.163.com/strive_only/blog/static/89380168200971010114665/ 雖然我也是用了好一段VC的
Qt之自定義搜索框——QLineEdit裏增加一個Layout,還不影響正常輸入文字(好像是一種比較通吃的方法)
too 步驟 set box 文本 csdn sub void 鼠標 簡述 關於搜索框,大家都經常接觸。例如:瀏覽器搜索、Windows資源管理器搜索等。 當然,這些對於Qt實現來說毫無壓力,只要思路清晰,分分鐘搞定。 方案一:調用QLineEdit現
揭秘:技術人突破瓶頸期,離不開這幾個關鍵點
設置 良好的 發展 ring demo 號稱 有關 esp 技術交流群 作為一個技術人,不知道你有沒有遇到過下面的情況?“我學不到新東西”“我感覺沒啥成長”“每天都在重復勞動”……其實,每個技術從業者,多多少少都會遇到工作或學習瓶頸期。產生瓶頸期,往往不是因為我們不夠努力,
結構中如果包含AnsiString,是不是就不能簡單的復制?
手表 爆炸 復制 南方 故事 天空 難受 中間 兩個 今年春遲,春節已過去很久天氣依然寒冷。對於生於南方的我來說, 10 攝氏度 以下的氣溫足以讓我很難受。 周末,天空透過窗隙投進來一束灰白的光,讓我讀取到今天又是陰冷的一天。伸手去摸床頭櫃上的手表,時間已是中午。記得昨晚是
判定閏年問題:年份能被4整除,並且不能被100整除,或者年份能被400整除
-o text 閏年 技術 ima 技術分享 .com size images 判定閏年問題:年份能被4整除,並且不能被100整除,或者年份能被400整除
前端基礎進階(十三):透徹掌握Promise的使用,讀這篇就夠了(轉)
https://www.jianshu.com/p/fe5f173276bd Promise的重要性我認為我沒有必要多講,概括起來說就是必須得掌握,而且還要掌握透徹。這篇文章的開頭,主要跟大家分析一下,為什麼會有Promise出現。 在實際的使用當中,有非常多的應用場景我們不能立即知道應該如
星耀資本陳亮:區塊鏈行業剛剛開始,遠不到下半場呢
當真格基金創始人徐小平半年前的某個半夜三點,告訴一個創業者區塊鏈時代來了的時候,不僅開啟了國人在區塊鏈上創業呈指數級增長的熱情,也看到了資本在本年度紛紛路人轉擁躉的瘋狂局面。很多時候,但凡看到一個不錯的區塊鏈專案,數十家投資機構蜂擁而至的熱鬧屢見不鮮。在這波熱鬧裡,一家叫做星
jq獲取元素內文字,但不包括其子元素內的文字值的方法,不包括後代
權宣告:本文為博主原創文章,未經博主允許不得轉載。 https://blog.csdn.net/zhangwenwu2/article/details/78365667 <li id="listItem"> This is some text
HR吐槽某博士程式設計師:簡歷寫了12頁,是不是讀書讀傻了
一名公司的一名HR在網際網路社群吐槽起面試的一個博士:一個博士36歲才畢業,博士讀了八年,簡歷寫了12頁,起碼2萬字算是一堆數學符號,這種人是不是讀書讀傻了? 很快,這名HR的吐槽引來了各路網友的口誅筆伐:這種超出自己認知的東西,還是不要隨便討論,顯得自己很膚淺;可能只是你的認知達不到,就
YOLOV3實戰2:訓練自己的資料集,你不可能出錯!
大家好,我是小p,今天給大家帶來一期用darknet版本YOLO V3訓練自己資料集的教程,希望大家喜歡。 歡迎加入物件檢測群813221712討論和交流,進群請看群公告! 一、搭建環境 搭建環境和驗證環境是否已經正確配置已在YOLOV3實戰1中詳細介紹,請一定
問題描述:開機出現bootmgr is missing,進不去系統
4、沒有WIN7安裝盤,無法進行系統修復。使用nt6 hdd installer進行硬碟安裝WIN7,試圖進行系統修復。重啟後仍然出現bootmgr is missing,卻不進入安裝WIN7介面。使用老毛桃PE下“嘗試引導本機系統”,進入安裝WIN7介面。選擇“系統修復”,提示“要恢復的系統與當前系統不相容
超級乾貨:最低效的思維陷阱,是不會找問題
很多時候我們做分析,面對的往往不是一個問題,而是許多個問題。這時就要抽絲剝繭,找到最關鍵的問題。 如何梳理問題之間的聯絡,甄別不同問題間的因果,這才是最考驗思考能力的地方。 在我的工作生涯中,通常會遇到兩類“關鍵問題”,下面分別來講。 第一種“關鍵問題”:高維問題 什麼意思呢?我先舉個例子,大家往下看
C語言入門:插入排序(程式碼實現,而不是排序方法闡述)
適用於理解排序方法思路而不清楚程式碼如何實現的C語言入門者 簡易流程圖: //插入排序,這裡以6個數的排序為例 #include <stdio.h> int main (void) { int a[6],i,j,mid,k; p
圖解陣列指標與多維陣列(附:為什麼指標加一,地址不一定加一)
這裡不是單純討論什麼是陣列指標,什麼是指標陣列,而是在掌握了一些知識後再回頭看看陣列指標與陣列到底怎麼理解。(陣列指標:指向陣列的指標。指標陣列:指標構成的陣列) 先放上一道題: 答案是10,20,30。 雖然是很常見的題,對於一個剛開始學C語言可能就可以做出來,但
C++實現:求1+2+3+...+n,要求不能使用乘除法、for、while、if、else、switch、case等關鍵字及條件判斷語句(A?B:C)
程式碼: class Solution { public: class Sum { public: Sum() { s_count++; s_sum += s_count;