
使用線程池多線程爬取鏈接,檢驗鏈接正確性
阿新 • • 發佈:2017-11-20
需求 完成 cep gen -- 開始 獲取url tool 可能
我們網站大多數鏈接都是活鏈接都是運營配置的,而有的時候運營會將鏈接配置錯誤使訪問出錯,有時也會因為程序bug造成訪問出錯,因此對主站寫了個監控腳本,使用python爬取主站設置的鏈接並訪問,統計訪問出錯的鏈接,因為鏈接有上百個,所以使用了多線程進行,因為http訪問是io密集型,所以python多線程還是可以很好的完成並發訪問的。
首先是index.py
使用了線程池管理線程,做到了配置需要檢驗的鏈接,然後爬取配置的鏈接頁面中的所有鏈接,同時因為可能子頁面許多url鏈接是和主站重復的,也可以做剔除
配置文件使用了yml文件: is_checkIndex 是否檢查與首頁重復,如果為True,則剔除和首頁重復的url
爬取鏈接使用了requests和正則表達式
最後是統計出錯的鏈接,在這裏也做了篩選,只篩選與網站相關的url,像一些合作網站等廣告鏈接是不會記錄返回
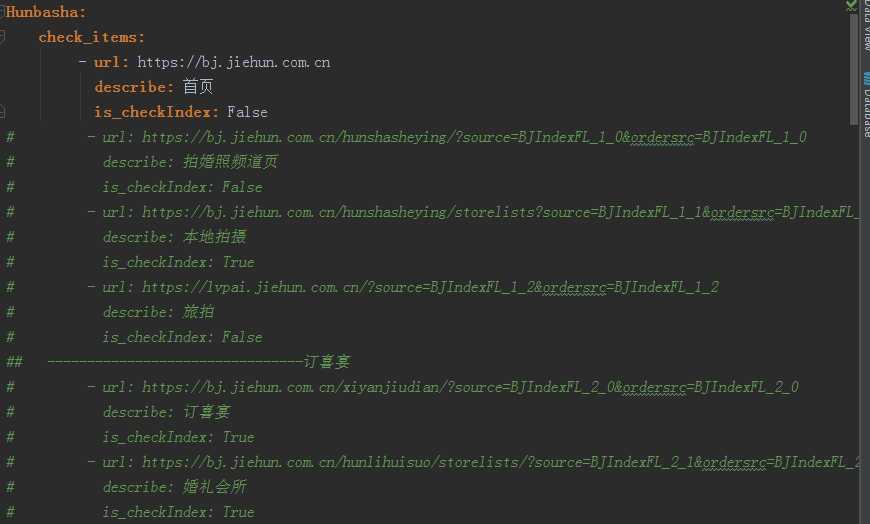
# encoding=utf-8 from queue import Queue import queue from Tool.hrefTool import HrefTest import threading import time from Tool.Log.logTool import LogTool index_url = ‘https://bj.jiehun.com.cn‘ class HunIndex: def __init__(self, url, is_checkIndex, index_items): self.url_queue = Queue() self.headers = { ‘User-Agent‘: ‘Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6‘, } self.thread_stop = False self.items = HrefTest.get_hostsit_href(url, self.headers)if is_checkIndex: self.index_items = index_items self.start_time = time.time() self.stop_time = None self.error_list = [] self.url = url self.is_checkIndex = is_checkIndex self.execute_items = [] def get_index_urlitem(self): LogTool.info(‘開始獲取頁面url,當前頁面:{url}‘.format(url=self.url)) if self.is_checkIndex: self.execute_items.extend([item for item in self.items if item not in self.index_items]) else: self.execute_items.extend(self.items) for item in list(set(self.execute_items)): if HrefTest.check_url(item[0]): item1 = (HrefTest.change_url(item[0], index_url), item[1]) self.url_queue.put(item1, block=True, timeout=5) LogTool.info(‘頁面url獲取完成,共{sum_url}個url‘.format(sum_url=self.url_queue.qsize())) def _parse_url(self, item): try: LogTool.info(‘檢查url: %s, 標題:%s‘ % (str(item[0]), str(item[1]))) response = HrefTest.get(item[0], self.headers) except Exception as e: LogTool.error(‘請求失敗,url=%s, error_messge:%s‘ % (str(item[0]), e)) print(‘error-%s, message-%s‘ % (item[0], e)) error = list(item) print(‘error‘, list(item)) error.append(‘error_message=%s‘ % e) self.error_list.append(error) else: if not response.status_code == 200: LogTool.error(‘請求失敗,url=%s, error_code:%s‘ % (str(item[0]), response.status_code)) print(‘error-%s error_code:%s‘ % (item[0], response.status_code)) error = list(item).append(‘error_message=%s‘ % response.status_code) print(‘error‘, item) print(‘----‘, error) self.error_list.append(error) else: LogTool.info(‘請求成功,測試通過,url=%s,title=%s‘ % (str(item[0]), str(item[1]))) print(‘success-%s‘ % item[0]) pass def parse_url(self): while not self.thread_stop: try: item = self.url_queue.get(timeout=5) except queue.Empty: self.thread_stop = True break self._parse_url(item) self.url_queue.task_done() def run(self): thread_list = [] t_url = threading.Thread(target=self.get_index_urlitem) thread_list.append(t_url) for i in range(35): t_parse = threading.Thread(target=self.parse_url) thread_list.append(t_parse) for t in thread_list: t.setDaemon(True) t.start() for q in [self.url_queue]: q.join() self.stop_time = time.time() if __name__ == ‘__main__‘: page_url = ‘https://bj.jiehun.com.cn/hunshasheying/storelists?source=BJIndexFL_1_1&ordersrc=BJIndexFL_1_1‘ hun = HunIndex(page_url, True) hun.run() sum_time = int(hun.stop_time - hun.start_time) print(sum_time)
爬取鏈接:
def get_hostsit_href(cls, url, headers): ‘‘‘ 獲取url頁面所有href a標簽 :param url: 要抓取的url :param headers: 請求頭 :return: 所有符合的url 及標題 ‘‘‘ try: response = requests.request(‘GET‘, url=url, headers=headers) except Exception as e: print(‘error-{url} message-{e}‘.format(url=url, e=e)) else: # print(response.text) # pattern = re.compile(‘<a.*href="(.*?)".{0}=?"?.*"?>(.*?)</a>‘) pattern = re.compile(‘href="(.*?)"{1}.?.{0,10}?=?"?.*"?>(.+)?</a>‘) # pattern = re.compile(‘<a\b[^>]+\bhref="([^"]*)"[^>]*>([\s\S]*?)</a>‘) items = re.findall(pattern, response.text) return items
比較簡單 正則寫的不是很匹配,但是已經能匹配出90%以上的鏈接,完全滿足需求了,因為對這方面還不是很熟悉,還有待學習。
效果:
因為鏈接訪問,即使多線程也要看網速等影響因素,網速好首頁300多個鏈接用時20秒左右,不好要40來秒,作為日常檢測還是可以的,如果檢測我們網站主站所有主頻道頁面,基本在10分鐘內可以完成,但是如果要是完成分城市站的所有監控那就有點雞肋了,寫過一級鏈接檢測完接著檢測二級鏈接的,用了半個多小時,4萬多個鏈接,有點過分了。。,並且有的鏈接可能只是id不同,並沒有很大的實際意義(例如商品類的url只是id不同,那這類檢測在這4萬多個中可能就有很多個重復的類似鏈接),後續看如何優化。。
使用線程池多線程爬取鏈接,檢驗鏈接正確性