
卷積算法歸納總結(淺識)
歸納卷積神經網絡的常用算法
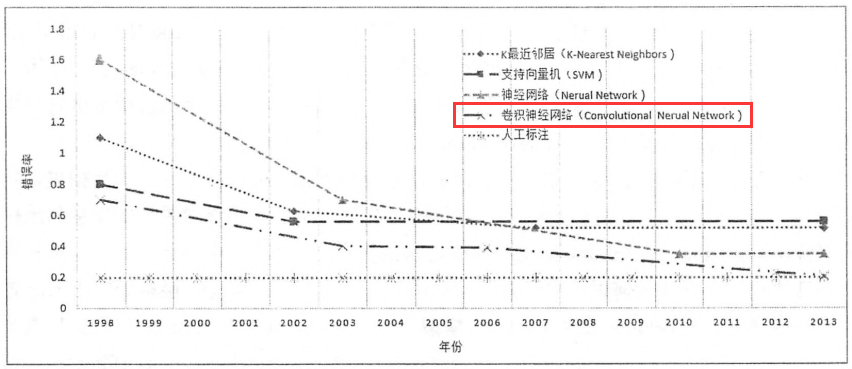
在卷積算法之前,是有很多圖片分類和識別的機器學習算法,像SVM向量機的原理特別復雜,卷積算法還是比較易懂,一方面避免全連接帶來的龐大參數,主要通過提取特征值,算法準確率也是最高的,幾乎可以跟人工識別相提並論了。
經典算法:
1,LeNet算法:
LeNet算法的流程是:
Input –>conv2->relu->pool->conv2->relu->pool->CF->softmax->output
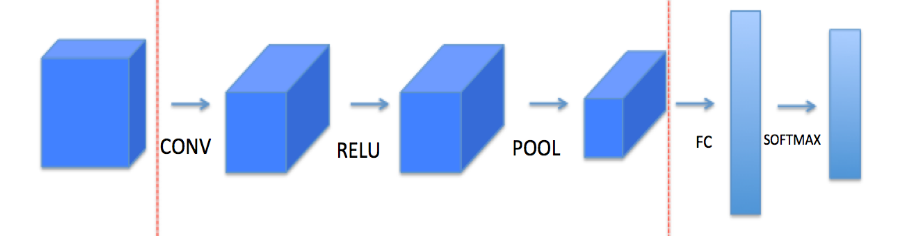
Input:輸入; 矩陣為(w,h,c) w:寬的像素;h:高的像素;c:通道
Conv:卷積計算
卷積就是把一個圖層(w,h)
Conv2:表示二維圖的卷積
一個圖層可能是64*64,通過W過濾層為(6,6) 通常有多個過濾層,輸出層為矩陣維度為64-6+1=59 ,即(59,59)
以下面的圖簡單為例:
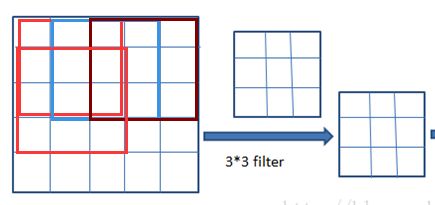
Pool:是池化操作,可能翻譯原因表述不一樣,池化層是單層的,池化層分為最大值池化和平均值池化;其實,也就是提取特征值最明顯的值,最大值池化的效果相對來說更好,所以建議使用。

FC:也就是全連接了,即WX+b=Y
Softmax:歸一化的處理,分類
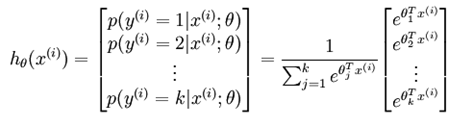
在conv2到pool過程中,還有一層no_linear_normal的操作,也是比較難懂,作用似乎沒那麽大,就被忽略了。
2,AlexNet算法:
其實就是一個leNet的變形,先來看一張圖:
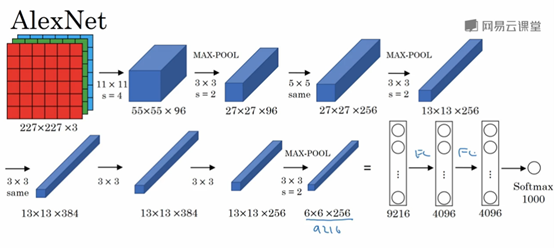
大體過程可分為:
Input->conv2->pool->conv2->pool->pool->pool->pool->pool->FC->FC->FC->softmax
當然中間還有一些relu激化函數就略過了,在激活函數前會通過LRN進行局部歸一化,減少使用復雜的激化函數。
3,VGG-16 算法:
VGG-16 跟VGG-19算法 主要是在層次多少區別,算法效果差不多,所以一般建議使用VGG-16
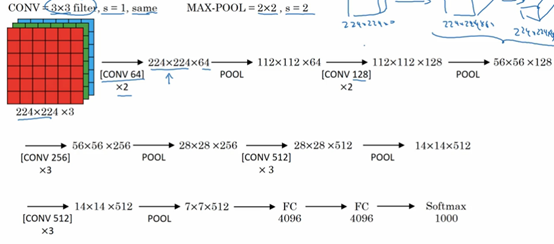
VGG算法跟alexNet的最大不同是這個算法重點是conv2卷積多次,達到集中特征收集的目的
==========================================================
高效的算法:
殘差算法:ResNet算法
卷積算法,流程都是通過多個過濾器進行特征值提取,中間的過程容易造成層次越多,原始特征丟失越嚴重,損失函數在逆向優化時梯度下降太快,所以需要加一些特征優化降低這個速度。對於一些神經深度越大的,這種算法越見優勢。
首先來一般的神經深度過程:
Input –>linear->rule->linear->relu->a
而resNet是加了一步
Input –>linear->rule->linear->?->relu->a
運算過程: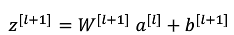
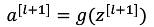
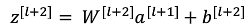
接下來是:?
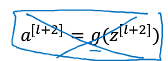
不是,這樣網絡越大,會增加錯誤幾率,所以得保真:
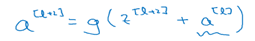
把上上步的a[L] 拿過來加進去求激活函數,這樣就能保真。再看一張圖:
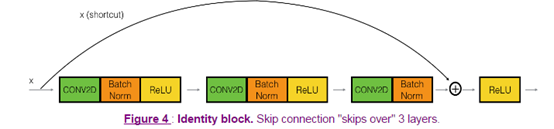
總體的流程如圖:

這不是真正的跳躍,而是把原先的a值拿來求激活函數。
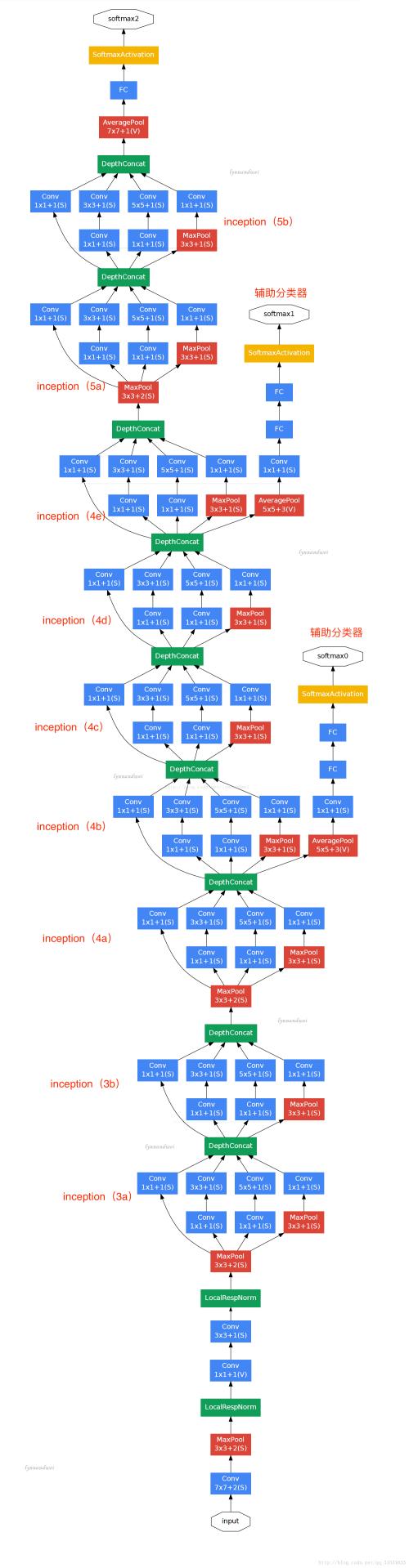
Inception network 算法
其實是谷歌的一個卷積算法 googleNet,這個算法真的比較負責,當然他的深度可以很深,也可以通過增加卷積的conv2的層次,識別一張圖片裏的多個事物;首先,我們先來一張圖:
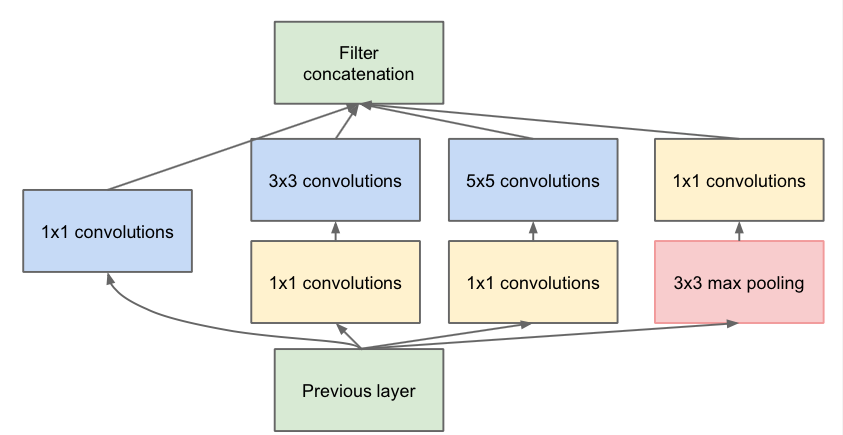
Previous layer是前一層 激活函數之後的
然後進行conv2或者pool進行,然後把各個層的卷積組成一個大的卷積。
有輔助卷積是可以識別出更多的物體。
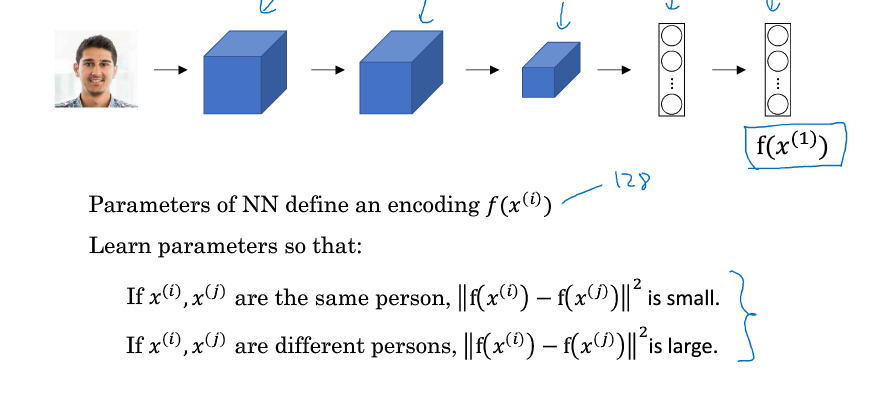
FaceNet算法 是人物識別
人物識別通常可用於監控,或者關卡或者上班的臉譜識別,通過卷積然後根據卷積後的CF後的特征計算誤差;通常會需要某個人物的十多張圖片作為訓練,然後再找其他的圖片作為對比。
自己本人圖片的計算誤差小於等於跟他人圖片的誤差
這裏只是作為學習的一個總結,具體實現要leNet-5,googleNet,inception Network, faceNet等關鍵詞去githup搜索相應的開源代碼去研究;這些都是開源出來的,至少你可以查到他的論文,不過幾乎都是英文。這才原汁原味。
參考:吳恩達視頻教程
卷積算法歸納總結(淺識)