
今天用node的cheerio模塊做了個某乎的爬蟲
一時興起,想做個爬蟲,經過各種深思熟慮,最後選擇了某乎,畢竟現在某乎的數據質量還是挺高的。說幹就幹
打開某乎首頁,隨便搜索了一串關鍵字,相關的問題和答案就展現在眼前,我就思考怎麽把這些搜索結果全部通過爬蟲爬下來,方便收集(我也不知道收集來幹嘛嘻嘻)。
發現搜索結果每頁只會顯示10條數據,某乎用的是點擊加載更多數據,於是打開chrome的network工具,點擊加載更多的按鈕,發現多了一個新的ajax請求,很明顯這個請求就是用來請求後十條數據的。
分析這個請求頭,觀察這個get請求的url最後的參數,offset=10,用腳都想的出來,這明顯就是告訴後臺我要的數據從哪條開始,而我要通過爬蟲把後面的數據爬下來就是要在這個參數上做些手腳,我只要改一下後面的offset構造新的url,然後發送新的請求,就可以得到其他頁面的數據。
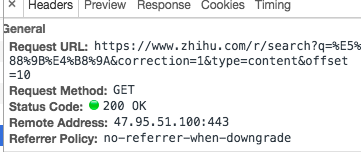
然而事情並沒有那麽簡單,我們先自己手動構造一個請求url,用瀏覽器打開看一下,服務器返回如下圖:
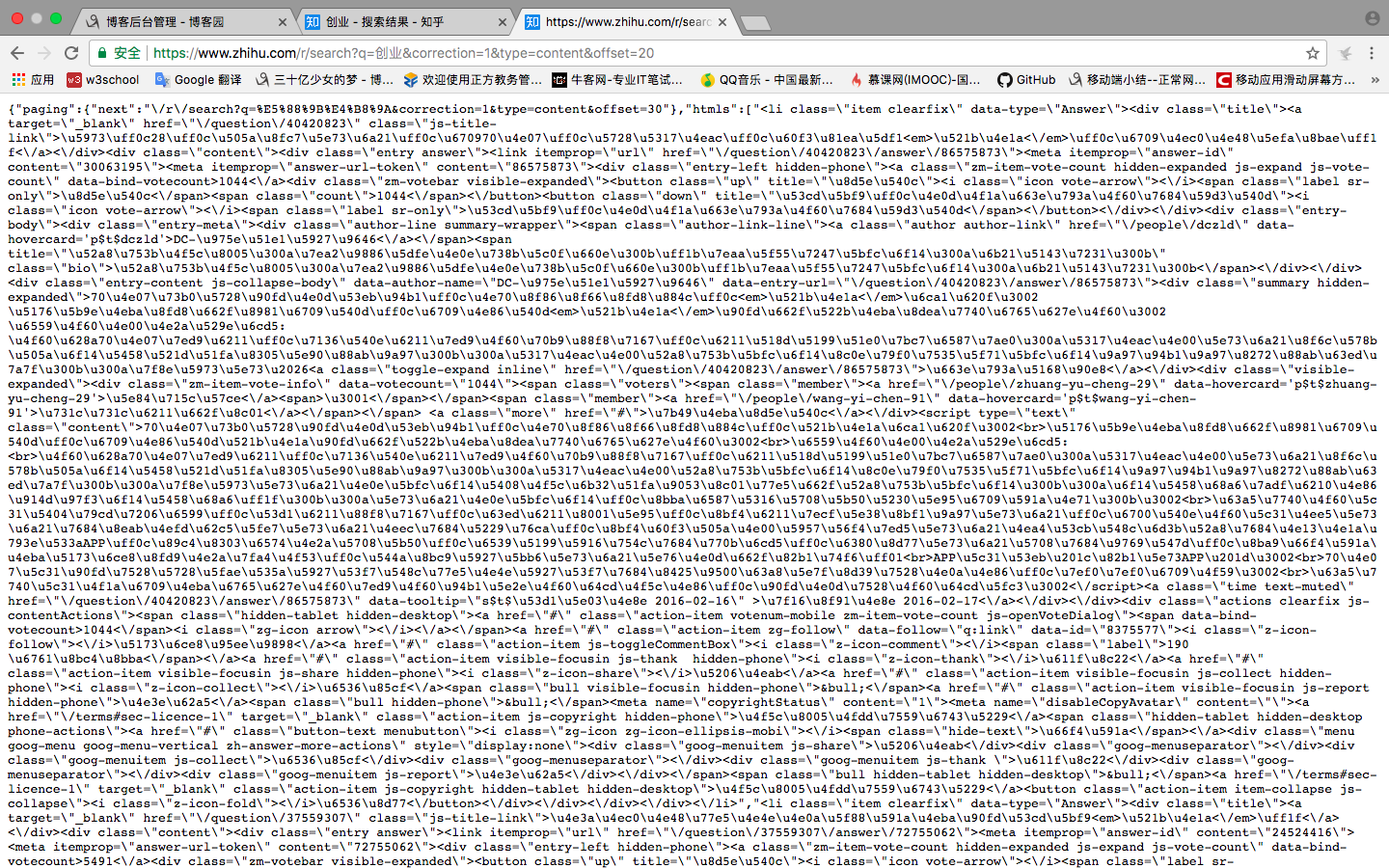
我滴個乖乖,這是什麽鬼,但是不要慌張,雖然一眼看上去很恐怖,但是仔細分析一下就知道這是用了unicode編碼而已,還有一堆轉意字符。
我用的是node的https模塊來進行get請求,拿到數據之後,先把拿到的數據(也就是上一張圖上的那些亂七八糟的東西)用正則匹配把\/替換成/,把\"替換成",然後用node的cheerio模塊就能解析出dom結構,然後就是提取出我們需要的信息,到這裏我們已經可以把搜索結果的所有問題都爬下來了,但是這只是抓取到了問題,問題的答案我們還要跳轉對應問題的鏈接才知道,同樣打開chrome的開發者工具,這次用elements的功能,看一下問題對應的超鏈接

果然,事情再一次沒有想象中的簡單,從數據可以看到,答案只抓取到了兩個,然而答案並不應該只有兩條,所以可以初步推測,當我們進入答案的頁面,後臺返回頁面的時候只返回了兩條答案,其他答案應該是用ajax後加載的。為了驗證我的假設,我把答案頁面的javascript禁止了,然後刷新,果然答案只返回了兩條,所以,可以證明我的假設是正確的,下面要做的就是找到加載更多答案的那個ajax請求,國際慣例,打開chrome的network工具,查看有哪些ajax請求,如下圖:
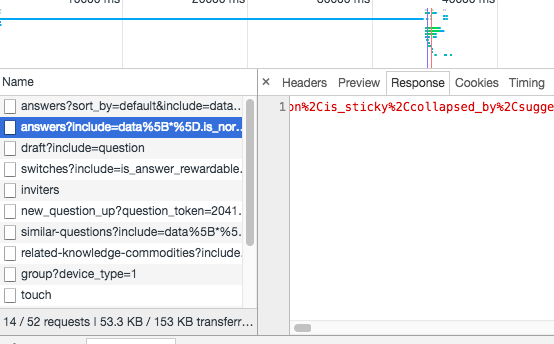
經過各種分析(響應大小,響應內容分析等等),最終鎖定目標,上圖被選中的get請求就是加載更多答案的那個get請求,把這個get請求url拷貝下來,我們在瀏覽器中打開看一下,結果如下圖:
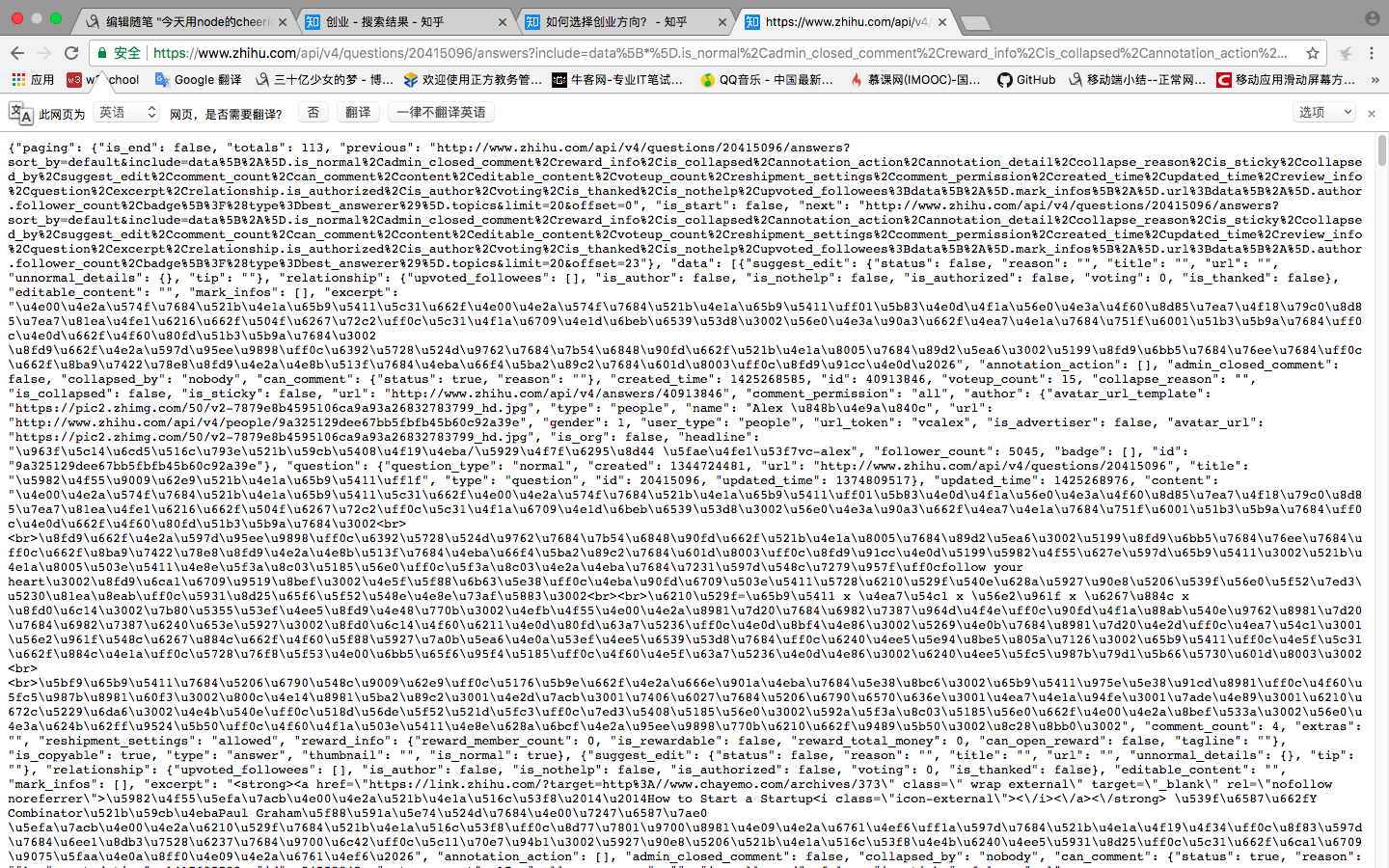
標準結局,結果又是一堆亂七八糟的東西,但是靜下心來仔細分析,可以看到結果其實是一個json格式的數據,並且做了unicode編碼,所以我們要做的就是把這些結果解碼,之後用JSON.parse()方法把這個json字符串轉換為json對象,然後就是對這個json對象進行一頓操作,最後分析出來。我們需要的內容就在這裏面,把我們需要的內容拿到之後保存在txt文檔中。
這樣爬蟲基本上就算完成了。效果如下圖:

踩坑總結:
1.正則表達式轉意字符,例: 我們要匹配 " 這個符號,正則表達式中需要在該符號之前加上轉意字符\
2.剛開始url請求更多答案的時候,服務器是返回100狀態給我的,經過各種分析,最後發現是有登陸信息才能請求所有答案,所以我用node請求答案的時候需要做的一件事就是假裝我是瀏覽器,並且我已經登陸了,嘻嘻嘻,這無非就是在請求頭上做手腳。比如修改UA,添加一些對應的cookie,authorization等等
為了造福人民,我已經把源碼在git開源了,點擊這裏,如能star,必將以身相許,嘻嘻嘻
今天用node的cheerio模塊做了個某乎的爬蟲