
漫談 SLAM 技術(上)
歡迎大家前往騰訊雲社區,獲取更多騰訊海量技術實踐幹貨哦~
作者:解洪文
導語
隨著最近幾年機器人、無人機、無人駕駛、VR/AR的火爆,SLAM技術也為大家熟知,被認為是這些領域的關鍵技術之一。本文對SLAM技術及其發展進行簡要介紹,分析視覺SLAM系統的關鍵問題以及在實際應用中的難點,並對SLAM的未來進行展望。
1. SLAM技術
SLAM(Simultaneous Localization and Mapping),同步定位與地圖構建,最早在機器人領域提出,它指的是:機器人從未知環境的未知地點出發,在運動過程中通過重復觀測到的環境特征定位自身位置和姿態,再根據自身位置構建周圍環境的增量式地圖,從而達到同時定位和地圖構建的目的。由於SLAM的重要學術價值和應用價值,一直以來都被認為是實現全自主移動機器人的關鍵技術。
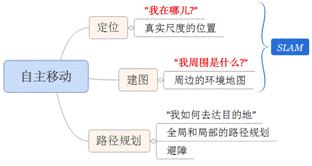
如下圖,通俗的來講,SLAM回答兩個問題:“我在哪兒?”“我周圍是什麽?”,就如同人到了一個陌生環境中一樣,SLAM試圖要解決的就是恢復出觀察者自身和周圍環境的相對空間關系,“我在哪兒”對應的就是定位問題,而“我周圍是什麽”對應的就是建圖問題,給出周圍環境的一個描述。回答了這兩個問題,其實就完成了對自身和周邊環境的空間認知。有了這個基礎,就可以進行路徑規劃去達要去的目的地,在此過程中還需要及時的檢測躲避遇到的障礙物,保證運行安全。
2. SLAM發展簡介
自從上世紀80年代SLAM概念的提出到現在,SLAM技術已經走過了30多年的歷史。SLAM系統使用的傳感器在不斷拓展,從早期的聲吶,到後來的2D/3D激光雷達,再到單目、雙目、RGBD、ToF等各種相機,以及與慣性測量單元IMU等傳感器的融合;SLAM的算法也從開始的基於濾波器的方法(EKF、PF等)向基於優化的方法轉變,技術框架也從開始的單一線程向多線程演進。下面介紹這些過程中一些代表性的SLAM技術。
(1)激光雷達SLAM發展
基於激光雷達的SLAM(Lidar SLAM)采用2D或3D激光雷達(也叫單線或多線激光雷達),如下圖所示。在室內機器人(如掃地機器人)上,一般使用2D激光雷達,在無人駕駛領域,一般使用3D激光雷達。

激光雷達的優點是測量精確,能夠比較精準的提供角度和距離信息,可以達到<1°的角度精度以及cm級別的測距精度,掃描範圍廣(通常能夠覆蓋平面內270°以上的範圍),而且基於掃描振鏡式的固態激光雷達(如Sick、Hokuyo等)可以達到較高的數據刷新率(20Hz以上),基本滿足了實時操作的需要;缺點是價格比較昂貴(目前市面上比較便宜的機械旋轉式單線激光雷達也得幾千元),安裝部署對結構有要求(要求掃描平面無遮擋)。
激光雷達SLAM建立的地圖常常使用占據柵格地圖(Ocupanccy Grid)表示,每個柵格以概率的形式表示被占據的概率,存儲非常緊湊,特別適合於進行路徑規劃。
現任Udacity創始人CEO、前Google副總裁、谷歌無人車領導者Sebastian Thrun大神(下圖)在他2005年的經典著作《Probabilistic Robotics》一書中詳細闡述了利用2D激光雷達基於概率方法進行地圖構建和定位的理論基礎,並闡述了基於RBPF粒子濾波器的FastSLAM方法,成為後來2D激光雷達建圖的標準方法之一GMapping[1][2]的基礎,該算法也被集成到機器人操作系統(Robot Operation System,ROS)中。

2013年,文獻[3]對ROS中的幾種2D SLAM的算法HectorSLAM,KartoSLAM,CoreSLAM,LagoSLAM和GMapping做了比較評估,讀者可前往細看。
2016年,Google開源其激光雷達SLAM算法庫Cartographer[4],它改進了GMapping計算復雜,沒有有效處理閉環的缺點,采用SubMap和Scan Match的思想構建地圖,能夠有效處理閉環,達到了較好的效果。
(2)視覺SLAM發展
相比於激光雷達,作為視覺SLAM傳感器的相機更加便宜、輕便,而且隨處可得(如人人都用的手機上都配有攝像頭),另外圖像能提供更加豐富的信息,特征區分度更高,缺點是圖像信息的實時處理需要很高的計算能力。幸運的是隨著計算硬件的能力提升,在小型PC和嵌入式設備,乃至移動設備上運行實時的視覺SLAM已經成為了可能。
視覺SLAM使用的傳感器目前主要有單目相機、雙目相機、RGBD相機三種,其中RGBD相機的深度信息有通過結構光原理計算的(如Kinect1代),也有通過投射紅外pattern並利用雙目紅外相機來計算的(如Intel RealSense R200),也有通過TOF相機實現的(如Kinect2代),對用戶來講,這些類型的RGBD都可以輸出RGB圖像和Depth圖像。

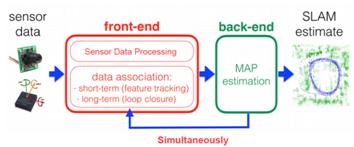
現代流行的視覺SLAM系統大概可以分為前端和後端,如下圖所示。前端完成數據關聯,相當於VO(視覺裏程計),研究幀與幀之間變換關系,主要完成實時的位姿跟蹤,對輸入的圖像進行處理,計算姿態變化,同時也檢測並處理閉環,當有IMU信息時,也可以參與融合計算(視覺慣性裏程計VIO的做法);後端主要對前端的輸出結果進行優化,利用濾波理論(EKF、PF等)或者優化理論進行樹或圖的優化,得到最優的位姿估計和地圖。
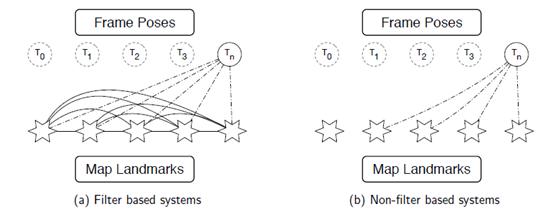
采用濾波器的SLAM,如下圖(a),估計n時刻的相機位姿Tn需要使用地圖中所有路標的信息,而且每幀都需要更新這些路標的狀態,隨著新的路標的不斷加入,狀態矩陣的規模增長迅速,導致計算和求解耗時越來越嚴重,因此不適宜長時間大場景的操作;而采用優化算法的SLAM,如下圖(b),通常結合關鍵幀使用,估計n時刻的相機位姿Tn可以使用整個地圖的一個子集,不需要在每幅圖像都更新地圖數據,因此現代比較成功的實時SLAM系統大都采取優化的方法。
下面介紹視覺SLAM發展歷程中幾個比較有代表性的SLAM系統進行介紹:
MonoSLAM[5]是2007年由Davison 等開發的第一個成功基於單目攝像頭的純視覺SLAM 系統。MonoSLAM使用了擴展卡爾曼濾波,它的狀態由相機運動參數和所有三維點位置構成, 每一時刻的相機方位均帶有一個概率偏差,每個三維點位置也帶有一個概率偏差, 可以用一個三維橢球表示, 橢球中心為估計值, 橢球體積表明不確定程度(如下圖所示),在此概率模型下, 場景點投影至圖像的形狀為一個投影概率橢圓。MonoSLAM 為每幀圖像中抽取Shi-Tomasi角點[6], 在投影橢圓中主動搜索(active search)[7]特征點匹配。由於將三維點位置加入估計的狀態變量中,則每一時刻的計算復雜度為O(n3) , 因此只能處理幾百個點的小場景。

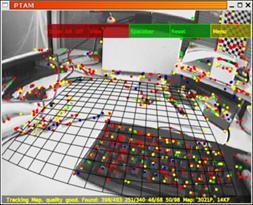
同年,Davison在Oxford的師父Murray和Klein發表了實時SLAM系統PTAM(Parallel Tracking and Mapping)[8]並開源(如下圖),它是首個基於關鍵幀BA的單目視覺SLAM 系統, 隨後在2009 年移植到手機端上[9]。PTAM在架構上做出了創新的設計,它將姿態跟蹤(Tracking)和建圖(Mapping)兩個線程分開並行進行,這在當時是一個創舉,第一次讓大家覺得對地圖的優化可以整合到實時計算中,並且整個系統可以跑起來。這種設計為後來的實時SLAM(如ORB-SLAM)所效仿,成為了現代SLAM系統的標配。具體而言,姿態跟蹤線程不修改地圖,只是利用已知地圖來快速跟蹤;而建圖線程專註於地圖的建立、維護和更新。即使建立地圖線程耗時稍長,姿態跟蹤線程仍然有地圖可以跟蹤(如果設備還在已建成的地圖範圍內)。此外,PTAM還實現丟失重定位的策略,如果成功匹配點(Inliers)數不足(如因圖像模糊、快速運動等)造成跟蹤失敗時,則開始重定位[10]——將當前幀與已有關鍵幀的縮略圖進行比較,選擇最相似的關鍵幀作為當前幀方位的預測。
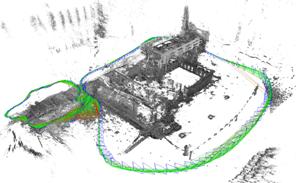
2011年,Newcombe 等人提出了單目DTAM 系統[11], 其最顯著的特點是能實時恢復場景三維模型(如下圖)。基於三維模型,DTAM 既能允許AR應用中的虛擬物體與場景發生物理碰撞,又能保證在特征缺失、圖像模糊等情況下穩定地直接跟蹤。DTAM采用逆深度(Inverse Depth)[12]方式表達深度。如下圖,DTAM將解空間離散為M×N×S 的三維網格,其中M× N為圖像分辨率,S為逆深度分辨率,采用直接法構造能量函數進行優化求解。DTAM 對特征缺失、圖像模糊有很好的魯棒性,但由於DTAM 為每個像素都恢復稠密的深度圖, 並且采用全局優化,因此計算量很大,即使采用GPU 加速, 模型的擴展效率仍然較低。

2013年,TUM機器視覺組的Engel 等人提出了一套同樣也是基於直接法的視覺裏程計(visual odometry, VO)系統,該系統2014年擴展為視覺SLAM 系統LSD-SLAM[13],並開源了代碼。與DTAM相比,LSD-SLAM 僅恢復半稠密深度圖(如下圖),且每個像素深度獨立計算, 因此能達到很高的計算效率。LSD-SLAM 采用關鍵幀表達場景,每個關鍵幀K包含圖像 Ik、逆深度圖Dk和逆深度的方差Vk。系統假設每個像素x的逆深度值服從高斯分布N(Dk (x),Vk (x))。LSD-SLAM 的前臺線程采用直接法計算當前幀t與關鍵幀k之間相對運動,後臺線程對關鍵幀中每個半稠密抽取的像素點x(梯度顯著區域), 在It中沿極線搜索Ik (x)的對應點, 得到新的逆深度觀測值及其方差,然後采用EKF更新Dk和Vk 。LSD-SLAM采用位姿圖優化來閉合回環和處理大尺度場景。2015年,Engel等人對LSD-SLAM進行了功能拓展,使其能夠支持雙目相機[14]和全景相機[15]。
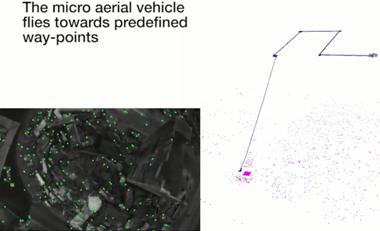
2014年,蘇黎世大學機器人感知組的Forster等人提出開源的SVO系統[16],該系統對稀疏的特征塊使用直接法配準(Sparse Model-based Image Alignment),獲取相機位姿,隨後根據光度不變假設構造優化方程對預測的特征位置進行優化(Feature Alignment),最後對位姿和結構進行優化(Motion-only BA和Structure-only BA),而在深度估計方面,構造深度濾波器,采用一個特殊的貝葉斯網絡[17]對深度進行更新。SVO的一個突出優點就是速度快,由於使用了稀疏的圖像塊,而且不需要進行特征描述子的計算,因此它可以達到很高的速度(作者在無人機的嵌入式ARM Cortex A9 4核1.6Ghz處理器平臺上可以達到55fps的速度),但是SVO缺點也很明顯,它沒有考慮重定位和閉環,不算是一個完整意義上的SLAM系統,丟失後基本就掛了,而且它的Depth Filter收斂較慢,結果嚴重地依賴於準確的位姿估計;2016年,Forster對SVO進行改進,形成SVO2.0[18]版本,新的版本做出了很大的改進,增加了邊緣的跟蹤,並且考慮了IMU的運動先驗信息,支持大視場角相機(如魚眼相機和反射式全景相機)和多相機系統,該系統目前也開源了可執行版本[19];值得一提的是,Foster對VIO的理論也進行了詳細的推導,相關的文獻[20]成為後續SLAM融合IMU系統的理論指導,如後面的Visual Inertial ORBSLAM等系統。
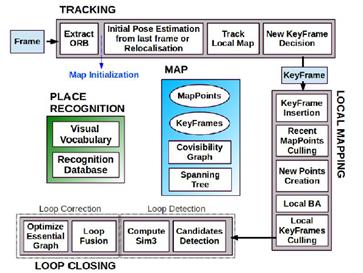
2015年,Mur-Artal 等提出了開源的單目ORB-SLAM[21],並於2016年拓展為支持雙目和RGBD傳感器的ORB-SLAM2[22],它是目前支持傳感器最全且性能最好的視覺SLAM系統之一,也是所有在KITTI數據集上提交結果的開源系統中排名最靠前的一個[23]。ORB-SLAM 延續了PTAM 的算法框架,增加了單獨的回環檢測線程,並對框架中的大部分組件都做了改進,歸納起來主要有以下幾點:1)ORB-SLAM追蹤、建圖、重定位和回環檢測各個環節都使用了統一的ORB 特征[24],使得建立的地圖可以保存載入重復利用;2)得益於共視圖(convisibility graph)的使用,將跟蹤和建圖操作集中在一個局部互見區域中,使其能夠不依賴於整體地圖的大小,能夠實現大範圍場景的實時操作;3)采用統一的BoW詞袋模型進行重定位和閉環檢測,並且建立索引來提高檢測速度;4)改進了PTAM只能手工選擇從平面場景初始化的不足,提出基於模型選擇的新的自動魯棒的系統初始化策略,允許從平面或非平面場景可靠地自動初始化。後來,Mur-Artal又將系統進行了拓展,形成了融合IMU信息的Visual Inertial ORB-SLAM[25],采用了Foster的論文[]提出的預積分的方法,對IMU的初始化過程和與視覺信息的聯合優化做了闡述。
2016年,LSD-SLAM的作者,TUM機器視覺組的Engel等人又提出了DSO系統[26]。該系統是一種新的基於直接法和稀疏法的視覺裏程計,它將最小化光度誤差模型和模型參數聯合優化方法相結合。為了滿足實時性,不對圖像進行光滑處理,而是對整個圖像均勻采樣。DSO不進行關鍵點檢測和特征描述子計算,而是在整個圖像內采樣具有強度梯度的像素點,包括白色墻壁上的邊緣和強度平滑變化的像素點。而且,DSO提出了完整的光度標定方法,考慮了曝光時間,透鏡暈影和非線性響應函數的影響。該系統在TUM monoVO、EuRoC MAV和ICL-NUIM三個數據集上進行了測試,達到了很高的跟蹤精度和魯棒性。

2017年,香港科技大學的沈紹劼老師課題組提出了融合IMU和視覺信息的VINS系統[27],同時開源手機和Linux兩個版本的代碼,這是首個直接開源手機平臺代碼的視覺IMU融合SLAM系統。這個系統可以運行在iOS設備上,為手機端的增強現實應用提供精確的定位功能,同時該系統也在應用在了無人機控制上,並取得了較好的效果。VINS-Mobile使用滑動窗口優化方法,采用四元數姿態的方式完成視覺和IMU融合,並帶有基於BoW的閉環檢測模塊,累計誤差通過全局位姿圖得到實時校正。

推薦閱讀
漫談 SLAM 技術(下)
手把手教你Serverless的沙龍來不來約?
雲服務器20元/月起,更享千元續費大禮包此文已由作者授權騰訊雲技術社區發布,轉載請註明原文出處
漫談 SLAM 技術(上)