
手寫數字識別的k-近鄰算法實現
阿新 • • 發佈:2017-12-17
保存 錯誤輸出 itl 圖1 換來 允許 more 原理 空間復雜度
(本文為原創,請勿在未經允許的情況下轉載)
前言
手寫字符識別是機器學習的入門問題,k-近鄰算法(kNN算法)是機器學習的入門算法。本文將介紹k-近鄰算法的原理、手寫字符識別問題分析、手寫字符識別的kNN實現、測試。
kNN算法原理
kNN算法是一種分類算法,即如何判定一組輸入數據屬於哪一類別的算法。kNN屬於監督學習算法,必須給定訓練樣本,樣本包括輸入樣本和輸出樣本。而無監督學習則不需要訓練樣本。
那麽最簡單的分類方法就是將輸入數據與樣本一一比對,並將相似性最強的前k個樣本選出,這k個樣本中的大多數屬於哪一類別,則判定輸入數據屬於該類別。
從圖形上看,就是找出了樣本空間中與輸入數據最近的k個數據,這些數據中的大多數屬於哪個類別,則輸入數據也屬於該類別。(當然,這是算法的原理,從邏輯上看問題不大,但是這個輸入數據是否應該和它的k個近鄰屬於同一類卻是不得而知的,但作為一個入門算法不考慮這種情況。)
手寫數字識別分析
- 圖像預處理:二值化、分割、統一標記。將這一過程成為預處理,是因為這一過程並不屬於kNN算法的內容。


圖1 樣本輸入(手寫體“4”和“5”) - 輸入數據格式化:由於是使用歐氏距離來尋找k-近鄰的,因此最好將輸入的圖像轉換為一個向量,以便於計算輸入數據與樣本數據的距離。
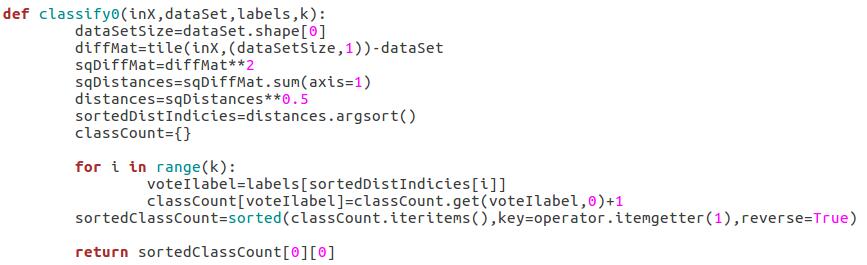
- 尋找k-近鄰:核心過程。計算歐氏距離並排序,取排前k的訓練樣本。
- 分類決策:前k個訓練樣本中的標簽統計,出現次數最多的標簽即為結果。
算法實現
- 圖像預處理:使用MATLAB對圖像進行處理,不屬於算法本身。
- 輸入數據格式化:對於已做好標記的圖片,輸入之後將矩陣轉換為向量。
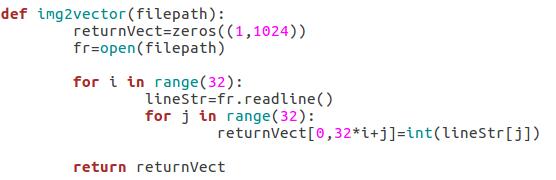
- 尋找k-近鄰:
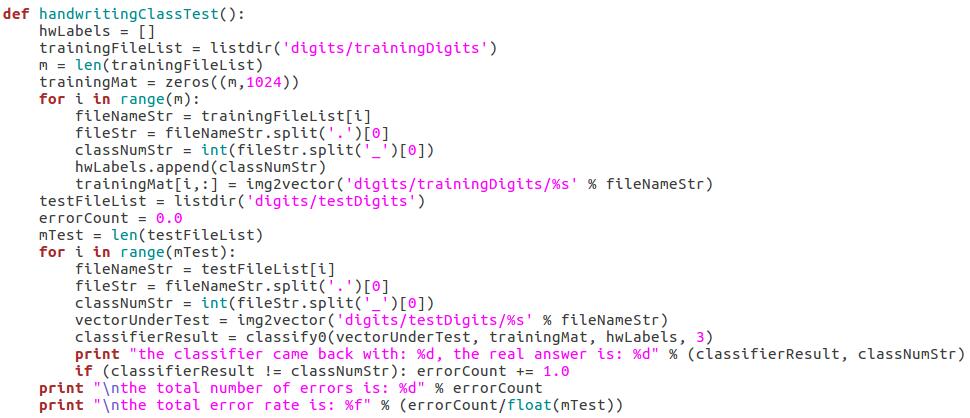
- 分類決策:
測試
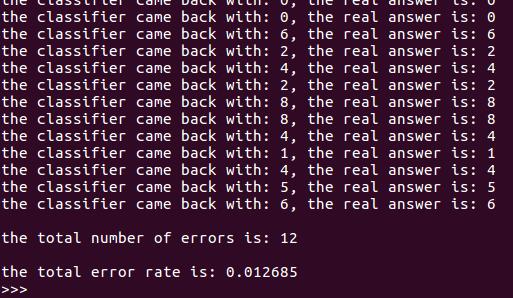
上圖展示了程序運行結果,在測試時共產生了12個錯誤輸出,錯誤率為1.27%。
結語
kNN算法是種簡單、有效的算法,但是該算法必須保存訓練數據集,如果訓練數據集很大,則會占用很多存儲空間。算法的時間復雜度和空間復雜度都並不令人滿意,因此簡單有效的算法往往會犧牲效率,程序員的自我犧牲換來高效的算法。
手寫數字識別的k-近鄰算法實現