
通過IDEA及hadoop平臺實現k-means聚類算法
阿新 • • 發佈:2017-12-20
綜合 tle tostring html map apache cnblogs cos textfile
有段時間沒有操作過,發現自己忘記一些步驟了,這篇文章會記錄相關步驟,並隨時進行補充修改。
1 基礎步驟,即相關環境部署及數據準備
數據文件類型為.csv文件,excel直接另存為即可,以逗號為分隔符
2 IDEA編輯代碼,打jar包
參考以下鏈接:
IntelliJ IDEA Windows下Spark開發環境部署
IDEA開發Spark的漫漫摸索(一)
IDEA開發Spark的漫漫摸索(二)
k-means聚類代碼參考:
package main.scala.yang.spark
import org.apache.log4j.{Level, Logger}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.clustering.KMeans
object KMeansBeijing {
def main(args: Array[String]): Unit = {
// 屏蔽不必要的日誌顯示在終端上
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
// 設置運行環境
val conf = new SparkConf().setMaster("local").setAppName("KMeansBeijing")
val sc = new SparkContext(conf)
// 裝載數據集
val data = sc.textFile("file:///home/hadoop/yang/USA/AUG_tag.csv", 1)
val parsedData = data.filter(!isColumnNameLine(_)).map(line => Vectors.dense(line.split(‘,‘).map(_.toDouble))).cache()
//
// 將數據集聚類,7個類,20次叠代,進行模型訓練形成數據模型
val numClusters = 4
val numIterations = 800
val model = KMeans.train(parsedData, numClusters, numIterations)
// 打印數據模型的中心點
println("Cluster centers:")
for (c <- model.clusterCenters) {
println(" " + c.toString)
}
// 使用誤差平方之和來評估數據模型
val cost = model.computeCost(parsedData)
println("Within Set Sum of Squared Errors = " + cost)
// // 使用模型測試單點數據
// println("Vectors 0.2 0.2 0.2 is belongs to clusters:" + model.predict(Vectors.dense("0.2 0.2 0.2".split(‘ ‘).map(_.toDouble))))
// println("Vectors 0.25 0.25 0.25 is belongs to clusters:" + model.predict(Vectors.dense("0.25 0.25 0.25".split(‘ ‘).map(_.toDouble))))
// println("Vectors 8 8 8 is belongs to clusters:" + model.predict(Vectors.dense("8 8 8".split(‘ ‘).map(_.toDouble))))
// 交叉評估1,只返回結果
val testdata = data.filter(!isColumnNameLine(_)).map(s => Vectors.dense(s.split(‘,‘).map(_.toDouble)))
val result1 = model.predict(testdata)
result1.saveAsTextFile("file:///home/hadoop/yang/USA/AUG/result1")
// 交叉評估2,返回數據集和結果
val result2 = data.filter(!isColumnNameLine(_)).map {
line =>
val linevectore = Vectors.dense(line.split(‘,‘).map(_.toDouble))
val prediction = model.predict(linevectore)
line + " " + prediction
}.saveAsTextFile("file:///home/hadoop/yang/USA/AUG/result2")
sc.stop()
}
private def isColumnNameLine(line: String): Boolean = {
if (line != null && line.contains("Electricity")) true
else false
}
}3 通過WinSCP將jar包上傳到hadoop平臺本地服務器上
註:直接拖拽即可
4 通過SecureCRT在hadoop平臺上執行相關命令
4.1 進入spark文件夾下

4.2 通過spark-submit命令提交任務(jar包)到集群
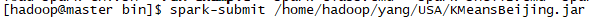
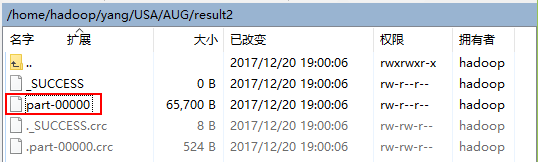
4.3 通過WinSCP查看結果
註:4.1和4.2可以綜合在一條命令中:
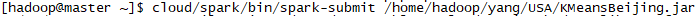
通過IDEA及hadoop平臺實現k-means聚類算法