
隨機森林(Random Forest)--- 轉載
1 什麽是隨機森林?
作為新興起的、高度靈活的一種機器學習算法,隨機森林(Random Forest,簡稱RF)擁有廣泛的應用前景,從市場營銷到醫療保健保險,既可以用來做市場營銷模擬的建模,統計客戶來源,保留和流失,也可用來預測疾病的風險和病患者的易感性。最初,我是在參加校外競賽時接觸到隨機森林算法的。最近幾年的國內外大賽,包括2013年百度校園電影推薦系統大賽、2014年阿裏巴巴天池大數據競賽以及Kaggle數據科學競賽,參賽者對隨機森林的使用占有相當高的比例。此外,據我的個人了解來看,一大部分成功進入答辯的隊伍也都選擇了Random Forest 或者 GBDT 算法。所以可以看出,Random Forest在準確率方面還是相當有優勢的。
那說了這麽多,那隨機森林到底是怎樣的一種算法呢?
如果讀者接觸過決策樹(Decision Tree)的話,那麽會很容易理解什麽是隨機森林。隨機森林就是通過集成學習的思想將多棵樹集成的一種算法,它的基本單元是決策樹,而它的本質屬於機器學習的一大分支——集成學習(Ensemble Learning)方法。隨機森林的名稱中有兩個關鍵詞,一個是“隨機”,一個就是“森林”。“森林”我們很好理解,一棵叫做樹,那麽成百上千棵就可以叫做森林了,這樣的比喻還是很貼切的,其實這也是隨機森林的主要思想--集成思想的體現。“隨機”的含義我們會在下邊部分講到。
其實從直觀角度來解釋,每棵決策樹都是一個分類器(假設現在針對的是分類問題),那麽對於一個輸入樣本,N棵樹會有N個分類結果。而隨機森林集成了所有的分類投票結果,將投票次數最多的類別指定為最終的輸出,這就是一種最簡單的 Bagging 思想。
2 隨機森林的特點
我們前邊提到,隨機森林是一種很靈活實用的方法,它有如下幾個特點:
- 在當前所有算法中,具有極好的準確率/It is unexcelled in accuracy among current algorithms;
- 能夠有效地運行在大數據集上/It runs efficiently on large data bases;
- 能夠處理具有高維特征的輸入樣本,而且不需要降維/It can handle thousands of input variables without variable deletion;
- 能夠評估各個特征在分類問題上的重要性/It gives estimates of what variables are important in the classification;
- 在生成過程中,能夠獲取到內部生成誤差的一種無偏估計/It generates an internal unbiased estimate of the generalization error as the forest building progresses;
- 對於缺省值問題也能夠獲得很好得結果/It has an effective method for estimating missing data and maintains accuracy when a large proportion of the data are missing
- ... ...
實際上,隨機森林的特點不只有這六點,它就相當於機器學習領域的Leatherman(多面手),你幾乎可以把任何東西扔進去,它基本上都是可供使用的。在估計推斷映射方面特別好用,以致都不需要像SVM那樣做很多參數的調試。具體的隨機森林介紹可以參見隨機森林主頁:Random Forest。
3 隨機森林的相關基礎知識
隨機森林看起來是很好理解,但是要完全搞明白它的工作原理,需要很多機器學習方面相關的基礎知識。在本文中,我們簡單談一下,而不逐一進行贅述,如果有同學不太了解相關的知識,可以參閱其他博友的一些相關博文或者文獻。
1)信息、熵以及信息增益的概念
這三個基本概念是決策樹的根本,是決策樹利用特征來分類時,確定特征選取順序的依據。理解了它們,決策樹你也就了解了大概。
引用香農的話來說,信息是用來消除隨機不確定性的東西。當然這句話雖然經典,但是還是很難去搞明白這種東西到底是個什麽樣,可能在不同的地方來說,指的東西又不一樣。對於機器學習中的決策樹而言,如果帶分類的事物集合可以劃分為多個類別當中,則某個類(xi)的信息可以定義如下:
![]()
I(x)用來表示隨機變量的信息,p(xi)指是當xi發生時的概率。
熵是用來度量不確定性的,當熵越大,X=xi的不確定性越大,反之越小。對於機器學習中的分類問題而言,熵越大即這個類別的不確定性更大,反之越小。
信息增益在決策樹算法中是用來選擇特征的指標,信息增益越大,則這個特征的選擇性越好。
2)決策樹
決策樹是一種樹形結構,其中每個內部節點表示一個屬性上的測試,每個分支代表一個測試輸出,每個葉節點代表一種類別。常見的決策樹算法有C4.5、ID3和CART。
3)集成學習
集成學習通過建立幾個模型組合的來解決單一預測問題。它的工作原理是生成多個分類器/模型,各自獨立地學習和作出預測。這些預測最後結合成單預測,因此優於任何一個單分類的做出預測。
隨機森林是集成學習的一個子類,它依靠於決策樹的投票選擇來決定最後的分類結果。你可以在這找到用python實現集成學習的文檔:Scikit 學習文檔。
4 隨機森林的生成
前面提到,隨機森林中有許多的分類樹。我們要將一個輸入樣本進行分類,我們需要將輸入樣本輸入到每棵樹中進行分類。打個形象的比喻:森林中召開會議,討論某個動物到底是老鼠還是松鼠,每棵樹都要獨立地發表自己對這個問題的看法,也就是每棵樹都要投票。該動物到底是老鼠還是松鼠,要依據投票情況來確定,獲得票數最多的類別就是森林的分類結果。森林中的每棵樹都是獨立的,99.9%不相關的樹做出的預測結果涵蓋所有的情況,這些預測結果將會彼此抵消。少數優秀的樹的預測結果將會超脫於蕓蕓“噪音”,做出一個好的預測。將若幹個弱分類器的分類結果進行投票選擇,從而組成一個強分類器,這就是隨機森林bagging的思想(關於bagging的一個有必要提及的問題:bagging的代價是不用單棵決策樹來做預測,具體哪個變量起到重要作用變得未知,所以bagging改進了預測準確率但損失了解釋性。)。下圖可以形象地描述這個情況:

有了樹我們就可以分類了,但是森林中的每棵樹是怎麽生成的呢?
每棵樹的按照如下規則生成:
1)如果訓練集大小為N,對於每棵樹而言,隨機且有放回地從訓練集中的抽取N個訓練樣本(這種采樣方式稱為bootstrap sample方法),作為該樹的訓練集;
從這裏我們可以知道:每棵樹的訓練集都是不同的,而且裏面包含重復的訓練樣本(理解這點很重要)。
為什麽要隨機抽樣訓練集?(add @2016.05.28)
如果不進行隨機抽樣,每棵樹的訓練集都一樣,那麽最終訓練出的樹分類結果也是完全一樣的,這樣的話完全沒有bagging的必要;
為什麽要有放回地抽樣?(add @2016.05.28)
我理解的是這樣的:如果不是有放回的抽樣,那麽每棵樹的訓練樣本都是不同的,都是沒有交集的,這樣每棵樹都是"有偏的",都是絕對"片面的"(當然這樣說可能不對),也就是說每棵樹訓練出來都是有很大的差異的;而隨機森林最後分類取決於多棵樹(弱分類器)的投票表決,這種表決應該是"求同",因此使用完全不同的訓練集來訓練每棵樹這樣對最終分類結果是沒有幫助的,這樣無異於是"盲人摸象"。
2)如果每個樣本的特征維度為M,指定一個常數m<<M,隨機地從M個特征中選取m個特征子集,每次樹進行分裂時,從這m個特征中選擇最優的;
3)每棵樹都盡最大程度的生長,並且沒有剪枝過程。
一開始我們提到的隨機森林中的“隨機”就是指的這裏的兩個隨機性。兩個隨機性的引入對隨機森林的分類性能至關重要。由於它們的引入,使得隨機森林不容易陷入過擬合,並且具有很好得抗噪能力(比如:對缺省值不敏感)。
隨機森林分類效果(錯誤率)與兩個因素有關:
- 森林中任意兩棵樹的相關性:相關性越大,錯誤率越大;
- 森林中每棵樹的分類能力:每棵樹的分類能力越強,整個森林的錯誤率越低。
減小特征選擇個數m,樹的相關性和分類能力也會相應的降低;增大m,兩者也會隨之增大。所以關鍵問題是如何選擇最優的m(或者是範圍),這也是隨機森林唯一的一個參數。
5 袋外錯誤率(oob error)
上面我們提到,構建隨機森林的關鍵問題就是如何選擇最優的m,要解決這個問題主要依據計算袋外錯誤率oob error(out-of-bag error)。
隨機森林有一個重要的優點就是,沒有必要對它進行交叉驗證或者用一個獨立的測試集來獲得誤差的一個無偏估計。它可以在內部進行評估,也就是說在生成的過程中就可以對誤差建立一個無偏估計。
我們知道,在構建每棵樹時,我們對訓練集使用了不同的bootstrap sample(隨機且有放回地抽取)。所以對於每棵樹而言(假設對於第k棵樹),大約有1/3的訓練實例沒有參與第k棵樹的生成,它們稱為第k棵樹的oob樣本。
而這樣的采樣特點就允許我們進行oob估計,它的計算方式如下:
(note:以樣本為單位)
1)對每個樣本,計算它作為oob樣本的樹對它的分類情況(約1/3的樹);
2)然後以簡單多數投票作為該樣本的分類結果;
3)最後用誤分個數占樣本總數的比率作為隨機森林的oob誤分率。
(文獻原文:Put each case left out in the construction of the kth tree down the kth tree to get a classification. In this way, a test set classification is obtained for each case in about one-third of the trees. At the end of the run, take j to be the class that got most of the votes every time case n was oob. The proportion of times that j is not equal to the true class of n averaged over all cases is the oob error estimate. This has proven to be unbiased in many tests.)
oob誤分率是隨機森林泛化誤差的一個無偏估計,它的結果近似於需要大量計算的k折交叉驗證。
6 隨機森林工作原理解釋的一個簡單例子
描述:根據已有的訓練集已經生成了對應的隨機森林,隨機森林如何利用某一個人的年齡(Age)、性別(Gender)、教育情況(Highest Educational Qualification)、工作領域(Industry)以及住宅地(Residence)共5個字段來預測他的收入層次。
收入層次 :
Band 1 : Below $40,000
Band 2: $40,000 – 150,000
Band 3: More than $150,000
隨機森林中每一棵樹都可以看做是一棵CART(分類回歸樹),這裏假設森林中有5棵CART樹,總特征個數N=5,我們取m=1(這裏假設每個CART樹對應一個不同的特征)。
CART 1 : Variable Age
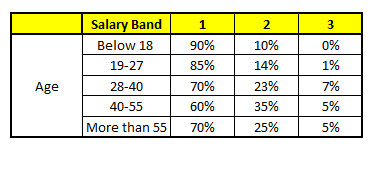
CART 2 : Variable Gender
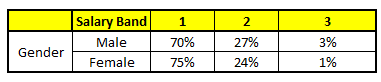
CART 3 : Variable Education
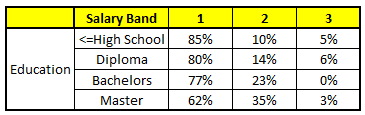
CART 4 : Variable Residence

CART 5 : Variable Industry
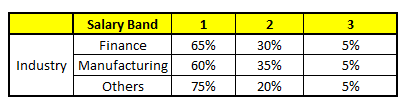
我們要預測的某個人的信息如下:
1. Age : 35 years ; 2. Gender : Male ; 3. Highest Educational Qualification : Diploma holder; 4. Industry : Manufacturing; 5. Residence : Metro.
根據這五棵CART樹的分類結果,我們可以針對這個人的信息建立收入層次的分布情況:
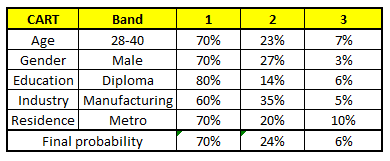
最後,我們得出結論,這個人的收入層次70%是一等,大約24%為二等,6%為三等,所以最終認定該人屬於一等收入層次(小於$40,000)。
7 隨機森林的Python實現
利用Python的兩個模塊,分別為pandas和scikit-learn來實現隨機森林。

from sklearn.datasets import load_iris from sklearn.ensemble import RandomForestClassifier import pandas as pd import numpy as np iris = load_iris() df = pd.DataFrame(iris.data, columns=iris.feature_names) df[‘is_train‘] = np.random.uniform(0, 1, len(df)) <= .75 df[‘species‘] = pd.Factor(iris.target, iris.target_names) df.head() train, test = df[df[‘is_train‘]==True], df[df[‘is_train‘]==False] features = df.columns[:4] clf = RandomForestClassifier(n_jobs=2) y, _ = pd.factorize(train[‘species‘]) clf.fit(train[features], y) preds = iris.target_names[clf.predict(test[features])] pd.crosstab(test[‘species‘], preds, rownames=[‘actual‘], colnames=[‘preds‘])
分類結果:

與其他機器學習分類算法進行對比:
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn.cross_validation import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import make_moons, make_circles, make_classification
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.lda import LDA
from sklearn.qda import QDA
h = .02 # step size in the mesh
names = ["Nearest Neighbors", "Linear SVM", "RBF SVM", "Decision Tree",
"Random Forest", "AdaBoost", "Naive Bayes", "LDA", "QDA"]
classifiers = [
KNeighborsClassifier(3),
SVC(kernel="linear", C=0.025),
SVC(gamma=2, C=1),
DecisionTreeClassifier(max_depth=5),
RandomForestClassifier(max_depth=5, n_estimators=10, max_features=1),
AdaBoostClassifier(),
GaussianNB(),
LDA(),
QDA()]
X, y = make_classification(n_features=2, n_redundant=0, n_informative=2,
random_state=1, n_clusters_per_class=1)
rng = np.random.RandomState(2)
X += 2 * rng.uniform(size=X.shape)
linearly_separable = (X, y)
datasets = [make_moons(noise=0.3, random_state=0),
make_circles(noise=0.2, factor=0.5, random_state=1),
linearly_separable
]
figure = plt.figure(figsize=(27, 9))
i = 1
# iterate over datasets
for ds in datasets:
# preprocess dataset, split into training and test part
X, y = ds
X = StandardScaler().fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.4)
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
# just plot the dataset first
cm = plt.cm.RdBu
cm_bright = ListedColormap([‘#FF0000‘, ‘#0000FF‘])
ax = plt.subplot(len(datasets), len(classifiers) + 1, i)
# Plot the training points
ax.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=cm_bright)
# and testing points
ax.scatter(X_test[:, 0], X_test[:, 1], c=y_test, cmap=cm_bright, alpha=0.6)
ax.set_xlim(xx.min(), xx.max())
ax.set_ylim(yy.min(), yy.max())
ax.set_xticks(())
ax.set_yticks(())
i += 1
# iterate over classifiers
for name, clf in zip(names, classifiers):
ax = plt.subplot(len(datasets), len(classifiers) + 1, i)
clf.fit(X_train, y_train)
score = clf.score(X_test, y_test)
# Plot the decision boundary. For that, we will assign a color to each
# point in the mesh [x_min, m_max]x[y_min, y_max].
if hasattr(clf, "decision_function"):
Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()])
else:
Z = clf.predict_proba(np.c_[xx.ravel(), yy.ravel()])[:, 1]
# Put the result into a color plot
Z = Z.reshape(xx.shape)
ax.contourf(xx, yy, Z, cmap=cm, alpha=.8)
# Plot also the training points
ax.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=cm_bright)
# and testing points
ax.scatter(X_test[:, 0], X_test[:, 1], c=y_test, cmap=cm_bright,
alpha=0.6)
ax.set_xlim(xx.min(), xx.max())
ax.set_ylim(yy.min(), yy.max())
ax.set_xticks(())
ax.set_yticks(())
ax.set_title(name)
ax.text(xx.max() - .3, yy.min() + .3, (‘%.2f‘ % score).lstrip(‘0‘),
size=15, horizontalalignment=‘right‘)
i += 1
figure.subplots_adjust(left=.02, right=.98)
plt.show()

這裏隨機生成了三個樣本集,分割面近似為月形、圓形和線形的。我們可以重點對比一下決策樹和隨機森林對樣本空間的分割:
1)從準確率上可以看出,隨機森林在這三個測試集上都要優於單棵決策樹,90%>85%,82%>80%,95%=95%;
2)從特征空間上直觀地可以看出,隨機森林比決策樹擁有更強的分割能力(非線性擬合能力)。
隨機森林(Random Forest)--- 轉載