
libco協程原理簡要分析
此文簡要分析一下libco協程的關鍵原理。
在分析前,先簡單過一些協程的概念,以免有新手誤讀了此篇文章。
協程是用戶態執行單元,它的創建,執行,上下文切換,掛起,銷毀都是在用戶態中完成,對linux系統而言,其實協程和進程(註:在linux系統中,進程是擁有獨立地址空間的線程)一樣,都是CPU的執行單元,只是進程是站在操作系統的層面來看,操作系統幫我們實現了這一抽象概念,而協程是站在用戶的應用程序層面來看,協程的實現得靠我們自己。我們常說使用協程可以做到以阻塞式的編碼方式實現異步非阻塞的效果,這是因為我們在用戶程序層面實現了調度器,當協程要阻塞的時候切換上下文,執行其余就緒的協程。
下面簡要說一下實現一個協程庫需要哪幾個模塊。
1 首先當然是操作系統的執行單元,對於一個執行單元來說,最基本的其實也就兩點,一是指令,二是內存空間,指令定義了操作,內存用於保存指令中需要的數據,基於對指令和內存的抽象,我們這裏先牽強的稱之為協程。
2 有了執行單元後,當然就需要調度器來負責調度這些執行單元,如某個協程要阻塞了,就保存其上下文,然後運行下一個就緒狀態的協程,當然調度器也是在一個協程單元中運行。
3 最後為了實現阻塞式編碼實現非阻塞的效果,需要實現異步I/O,而異步IO也恰是調度協程的觸發器。
協程庫中有了這三個模塊基本就完成了。這裏有一個關鍵的點,那就是當前運行的協程要阻塞了,我們將其上下文保存,切換至下一個就緒狀態的協程,這裏該如何實現?
要回答這個問題,我們得先想想什麽操作會引起當前協程阻塞?協程或者說所有的執行單元其實都是指令和數據的有序排列,指令的執行依賴於數據,因此協程阻塞的話想必是因數據而起,說白了就是I/O操作(當然還有sleep操作,這個先以特例看待)。為了避免當前協程阻塞導致整個進程都阻塞掉,我們可以使用多路I/O模型,例如epoll,將所有的I/O操都作通過epoll模型來進行,一旦有協程的需要進行IO,就保存好它的上下文環境,加入阻塞隊列,然後再從就緒隊列中取出下一個協程運行,待所有工作協程都陷入阻塞時,再通過epoll進行多路IO操作。
至於如何保存與恢復上下文這一點正是此文接下來要分析的。
我們先簡要看一下協程上下文的定義
//coctx.h
struct coctx_t
{
#if defined(__i386__)
void *regs[ 8 ];
#else
void *regs[ 14 ];
#endif
size_t ss_size;
char *ss_sp;
}; 該結構保存著協程的上下文,在這裏先不解釋各個變量的含義,將其拿出來只是為了解釋協程切換的關鍵函數:coctx_swap,因為調用該函數時將傳入兩個coctx_t類型指針。
協程上下文切換的關鍵實現位於coctx_swap.S文件中。初學者可能會疑惑這是什麽文件,這裏簡單解釋一下,我們寫的源代碼能變成最終的可執行文件,是經過多個步驟的,分別是預處理->編譯->匯編->鏈接4個過程,其中編譯這一過程是將源代碼轉成匯編代碼,那麽為什麽這裏直接提供一個匯編代碼文件,而不是一個.c或.cpp文件呢?因為這個函數跟我們用c/cpp寫出的函數經過gnu編譯器編譯後生成的函數結構不一致,另外c/cpp的語法糖也無法實現對寄存器(主要是rsp和rip寄存器)的控制。
這裏只看x86_64架構下的實現
.globl coctx_swap
#if !defined( __APPLE__ ) && !defined( __FreeBSD__ )
.type coctx_swap, @function
#endif
coctx_swap:
leaq 8(%rsp),%rax
leaq 112(%rdi),%rsp
pushq %rax
pushq %rbx
pushq %rcx
pushq %rdx
pushq -8(%rax) //ret func addr
pushq %rsi
pushq %rdi
pushq %rbp
pushq %r8
pushq %r9
pushq %r12
pushq %r13
pushq %r14
pushq %r15
movq %rsi, %rsp
popq %r15
popq %r14
popq %r13
popq %r12
popq %r9
popq %r8
popq %rbp
popq %rdi
popq %rsi
popq %rax //ret func addr
popq %rdx
popq %rcx
popq %rbx
popq %rsp
pushq %rax
xorl %eax, %eax
ret先簡單解釋一下頭部的代碼:
.globl coctx_swap //.global 聲明coctx_swap是全局可見的
#if !defined( __APPLE__ ) && !defined( __FreeBSD__ )
.type coctx_swap, @function //gnu匯編器定義函數時的規則
#endif
coctx_swap: //coctx_swap函數內容開始
leaq 8(%rsp),%rax
leaq 112(%rdi),%rsp
...上面已經提過了,該函數實際被調用時,傳入了兩個參數,均為coctx_t類型指針。接下來我們看該函數的上半段:coctx_swap:
leaq 8(%rsp),%rax
leaq 112(%rdi),%rsp
pushq %rax
pushq %rbx
pushq %rcx
pushq %rdx
pushq -8(%rax) //ret func addr
pushq %rsi
pushq %rdi
pushq %rbp
pushq %r8
pushq %r9
pushq %r12
pushq %r13
pushq %r14
pushq %r15
... lea是取址指令,b,w,l,q是操作屬性限定符,分別表示1字節,2字節,4字節,8字節。在x86_64架構下,函數調用時,參數傳遞將從左到右分別存入rdi,rsi,rdx,rcx,r8,r9,當這6個不夠用的時候才會借用棧。
此處簡要提一下x86_64架構下gnu編譯器編譯後的c/cpp函數調用過程:
1 傳參,主要是傳遞給寄存器。當寄存器不夠用時,會叢右到左壓棧,然後再傳參給寄存器
2 將返回地址壓棧,該地址一般指向上一函數中的下一條指令
3 修改rip寄存器(指令寄存器)為調用函數的起始地址,新的函數開始了
4 將上個函數的棧幀基址(rbp寄存器用於存放棧幀基址)壓入棧中
5 將rbp寄存器中的值修改為rsp寄存中的值,即開啟了新的棧幀
其中2,3是一般由call指令做的(當然也可以拆分為push,jump兩個指令),4,5為被調函數裏面的邏輯。
函數返回時是一個逆向的過程,即恢復到上個函數的棧幀即可。
其中rsp寄存器為棧頂的地址,由於棧空間是向下增長的,每次push,pop操作都會對其減少和增加對應的字節數。因此上半段相當於是把當前的各寄存器值存入了第一個參數傳入的協程上下文的regs數組中,結果如下:
//low | regs[0]: r15 |
// | regs[1]: r14 |
// | regs[2]: r13 |
// | regs[3]: r12 |
// | regs[4]: r9 |
// | regs[5]: r8 |
// | regs[6]: rbp |
// | regs[7]: rdi |
// | regs[8]: rsi |
// | regs[9]: ret | //函數的返回地址
// | regs[10]: rdx |
// | regs[11]: rcx |
// | regs[12]: rbx |
//hig | regs[13]: rsp | //該值為上個棧幀在調用該函數前的值其實從這段代碼中也能推出來了,傳入的第一個參數必然就是當前工作協程的上下文變量,那麽相應的,傳入的第二個參數必然就是接下來要執行的工作協程。接下來看下半段代碼:
movq %rsi, %rsp
popq %r15
popq %r14
popq %r13
popq %r12
popq %r9
popq %r8
popq %rbp
popq %rdi
popq %rsi
popq %rax //ret func addr
popq %rdx
popq %rcx
popq %rbx
popq %rsp
pushq %rax
xorl %eax, %eax
ret第一行即把rsp(存儲棧頂的地址,改變它的地址,就相當於改變了棧空間)替換為rsi寄存器中的值,上面提過了rsi保存著第二個參數中傳入進來的上下文變量,即接下來要運行的工作協程的上下文。接著是一系列的賦值行為(註意棧空間是向下增長的),將接下來要運行的工作協程的上下文中的regs數組中的各值恢復到各寄存器中。將返回地址壓入棧中,清0rax寄存器的低32位後(該寄存器一般用於存儲函數返回值,這行代碼並不是要拿它作為返回值使用,因為c/cpp代碼在聲明該函數時,它並沒有返回值,個人感覺是出於程序安全考慮),執行ret指令(該指令用於將棧頂的返回地址彈出給rip寄存器,這也是push %rax 將返回地址壓入棧中的原因),於是下一個工作協程開始運行了。
有沒有感覺漏了些什麽?
是的,漏了協程的上下文初始化過程。我們看一下其初始化函數:
//coctx.cpp
enum
{
kRDI = 7,
kRSI = 8,
kRETAddr = 9,
kRSP = 13,
};
int coctx_make( coctx_t *ctx,coctx_pfn_t pfn,const void *s,const void *s1 )
{
char *sp = ctx->ss_sp + ctx->ss_size;
sp = (char*) ((unsigned long)sp & -16LL );
memset(ctx->regs, 0, sizeof(ctx->regs));
ctx->regs[ kRSP ] = sp - 8;
ctx->regs[ kRETAddr] = (char*)pfn;
ctx->regs[ kRDI ] = (char*)s;
ctx->regs[ kRSI ] = (char*)s1;
return 0;
}其中,下面的兩行代碼最為重要
ctx->regs[ kRSP ] = sp - 8;
ctx->regs[ kRETAddr] = (char*)pfn;第一行是將rsp寄存器替換為了該協程私有的棧空間地址,這樣就保證了每個協程具備獨立的棧空間。
為什麽替換了rsp寄存器就保證了該協程將使用自己的棧空間地址呢?
因為棧空間的分配和回收,是通過rsp寄存器來控制的,如我要分配4個字節時,可執行sub $0x4,%rsp,回收4個字節時,可執行add $0x4,%rsp,因此當替換了rsp寄存器的值時,即替換了棧空間第二行是將返回地址(即下一條執行指令)替換為了用戶創建協程時傳入的開始函數地址。
當然一個函數的執行少不了傳參,因此接下來的兩行代碼,就把參數賦值給了regs數組中對應與rdi寄存器和rsi寄存器的位置
ctx->regs[ kRDI ] = (char*)s; //rdi寄存器保存從左到右的第一個參數
ctx->regs[ kRSI ] = (char*)s1; //rsi寄存器保存從左到右的第二個參數到此,核心部分均分析完畢。接下來再回顧核心函數coctx_swap的代碼,上面我已經提過了,這個函數的結構和普通的c/cpp寫出的函數經gnu編譯器編譯後生成的函數結構不一致,在接下來的代碼中,我會在註釋裏將其精簡掉的部分寫出來。
.globl coctx_swap
#if !defined( __APPLE__ ) && !defined( __FreeBSD__ )
.type coctx_swap, @function
#endif
coctx_swap:
//push %rbp //將上個棧幀的基址壓入棧中
//movq %rsp,%rbp //將rbp賦值為當前的棧頂的值,即開啟了新的棧幀
//保存當前工作線程的上下文
leaq 8(%rsp),%rax
leaq 112(%rdi),%rsp
pushq %rax
pushq %rbx
pushq %rcx
pushq %rdx
pushq -8(%rax) //函數返回地址,即下一條指令的執行地址
pushq %rsi
pushq %rdi
pushq %rbp
pushq %r8
pushq %r9
pushq %r12
pushq %r13
pushq %r14
pushq %r15
//恢復下一個工作協程的上下文
movq %rsi, %rsp
popq %r15
popq %r14
popq %r13
popq %r12
popq %r9
popq %r8
popq %rbp
popq %rdi
popq %rsi
popq %rax //函數返回地址,即下一條指令的執行地址
popq %rdx
popq %rcx
popq %rbx
popq %rsp
pushq %rax
xorl %eax, %eax
//leaveq 該指令將rbp賦值給rsp,再彈出棧頂的上個棧幀的基址,並將其賦值給rbp寄存器,從而恢復上個棧幀調用該函數前的結構。相當於movq %ebp, %esp和popq %ebp兩條指令
ret //相當於popq %rip最後再額外提一點,libco協程庫的性能如何?其實可以看到其切換成本非常的低,每次切換只有三十多條指令。但真正影響切換性能的其實並不是這關鍵性的上下文切換代碼,而是切換之後可能帶來的cache缺失問題!要知道對於現在的cpu來說,一次總線周期已經足夠cpu執行幾十條指令了。關於cpu cache的知識,可以查看我的另一篇文章,從死循環說起。關於libco如何hook第三方庫,實現無縫接入的原理,可以參考我的另一篇文章,libco hook原理簡析。
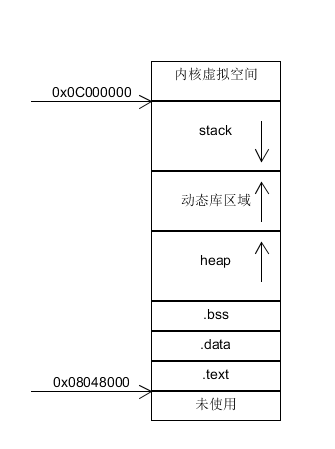
末尾附上c/cpp程序函數調用過程時的棧幀結構以及i386架構下的c/c++程序內存結構,輔助初學者理解。
此圖為c/cpp程序的函數調用棧示意圖,在x86_64架構下,當寄存器足夠存放參數時,是不會對參數進行壓棧的,因此參數1到n(對應函數參數列表是從右到左)是可選的,當把上個棧幀的基址壓入棧中時,新的棧幀就開始了。
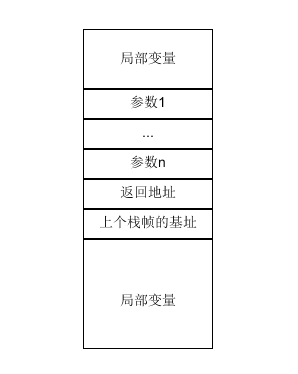
下圖為32位系統(linux)下的c/cpp程序的內存結構簡易圖,32位系統尋址能力為4G,其中0x0C000000-0xFFFFFFFF為內核空間,用戶空間只有3G,箭頭標明了內存的增長方向,其中堆和動態庫都是向上增長的,棧是向下增長的
libco協程原理簡要分析