
高可用集群介紹
阿新 • • 發佈:2018-03-01
高可用 可用性 自動切換 HA 一,高可用集群概念
1,什麽是高可用性?
“高可用性”(High Availability)通常來描述一個系統經過專門的設計,從而減少停工時間,而保持其服務的高度可用性;
主要是避免軟件、硬件、人為造成的故障對業務的影響降低到最小程度,以保證服務不間斷地運行;
基本可用性 99% 87.6小時
較高可用性 99.9% 8.8小時
具有故障自動恢復能力的可用性 99.99% 53分鐘
極高可用性 99.999% 5分鐘
(2)負載均衡服務器的高可用性
為了屏蔽負載均衡服務器的失效,需要建立一個備份機。主服務器和備份機上都運行High Availability監控程序,通過傳送諸如“I am alive”這樣的信息來監控對方的運行狀況。當備份機不能在一定的時間內收到這樣的信息時,它就接管主服務器的服務IP並繼續提供服務;當備份管理器又從主管理器收到“I am alive”這樣的信息時,它就釋放服務IP地址,這樣的主管理器就開始再次進行集群管理的工作了。為在主服務器失效的情況下系統能正常工作,我們在主、備份機之間實現負載集群系統配置信息的同步與備份,保持二者系統的基本一致。
自動偵測(Auto-Detect)階段由主機上的軟件通過冗余偵測線,經由復雜的監聽程序。邏輯判斷,來相互偵測對方運行的情況,所檢查的項目有:主機硬件(CPU和周邊)、主機網絡、主機操作系統、數據庫引擎及其它應用程序、主機與磁盤陣列連線。為確保偵測的正確性,而防止錯誤的判斷,可設定安全偵測時間,包括偵測時間間隔,偵測次數以調整安全系數,並且由主機的冗余通信連線,將所匯集的訊息記錄下來,以供維護參考。
(4)自動切換(Auto-Switch)階段 某一主機如果確認對方故障,則正常主機除繼續進行原來的任務,還將依據各種容錯備援模式接管預先設定的備援作業程序,並進行後續的程序及服務。
(6)高可用集群資源(HA Resource)和集群資源類型
集群資源是集群中使用的規則、服務和設備等,如VIP、httpd服務、STONITH設備等。類型如下:
Primitive:主資源,在某一時刻只能運行在某個節點上,如VIP。
group:組,使得多個資源同時停/啟等,一般只包含primitive資源。
clone:克隆,可以在多個節點運行的資源
master/slave:特殊的clone資源,運行在兩個節點上,一主一從
(7)自動切換選擇規則
根據資源的傾向(資源粘性、位置約束的分數比較)進行轉移;
資源的傾向(資源定位的依據):
A、資源粘性:資源對節點傾向程度,資源是否傾向於當前節點。score,正值傾向於當前節點(還要和位置約束結合)。
B、資源約束(Constraint):資源和資源之間的關系
a、排列約束 (colocation):資源間的依賴/互斥性,定義資源是否運行在同一節點上。score,正值表示要運行在同一節點上,負值則不可。
b、位置約束(location):每個節點都有一個score值,正值則傾向於本節點,負值傾向於其他節點,所有節點score比較,傾向於最大值的節點。
c、順序約束(order):定義資源執行動作的次序,例如vip應先配置,httpd服務後配置。特殊的score值,-inf 負無窮,inf 正無窮。
也就是說資源粘性定義資源對資源當前所在節點的傾向性,而位置約束定義資源對集群中所有節點的傾向性。如webip的資源粘性為100,位置約束對node1為200,當webip在node2上時,node2上線資源會轉移到node1,因為當前節點node2粘性100小於對node1的位置約束200;如webip的資源粘性為200,位置約束對node1為100,當webip在node2上時,node1上線資源不會轉移到node1,繼續留在node2上,因為當前節點node2粘性200大於對node1的位置約束100。
(8)處理不合法的集群節點
如果集群沒有對其進行Fecning/Stonith隔離前,可以進行相關配置(without_quorum_policy),有如下配置選項:
stop:直接停止服務;
ignore:忽略,以前運行什麽服務現在還運行什麽(雙節點集群需要配置該選項);
Freeze:凍結,保持事先建立的連接,但不再接收新的請求;
suicide:kill掉服務。
(9)集群腦裂(Split-Brain)和資源隔離(Fencing)
腦裂是因為集群分裂導致的,集群中有節點因為處理器忙或者其他原因暫時停止響應時,與其他節點間的心跳出現故障,但這些節點還處於active狀態,其他節點可能誤認為該節點"已死",從而爭奪共享資源(如共享存儲)的訪問權,分裂為兩部分獨立節點。
腦裂後果:兩個節點爭搶共享資源,結果會導致系統混亂,數據損壞。
腦裂解決:直接停止服務,或者忽略,但完全解決還需要資源隔離(Fencing)。
資源隔離(Fencing):
當不能確定某個節點的狀態時,通過fencing把對方幹掉,確保共享資源被完全釋放
節點級別:
STONITH(shoot the other node in the head,爆頭。硬件方式),直接控制故障節點的電源。
資源級別:
例如:FC SAN switch(軟件方式)可以實現在存儲資源級別拒絕某節點的訪問
3,工作方式
(1)主從方式 (非對稱方式)
工作原理:主機工作,備機處於監控準備狀況;當主機宕機時,備機接管主機的一切工作,待主機恢復正常後,按使用者的設定以自動或手動方式將服務切換到主機上運行,數據的一致性通過共享存儲系統解決。
(2)雙機雙工方式(互備互援)
工作原理:兩臺主機同時運行各自的服務工作且相互監測情況,當任一臺主機宕機時,另一臺主機立即接管它的一切工作,保證工作實時,應用服務系統的關鍵數據存放在共享存儲系統中。
(3)集群工作方式(多服務器互備方式)
工作原理:多臺主機一起工作,各自運行一個或幾個服務,各為服務定義一個或多個備用主機,當某個主機故障時,運行在其上的服務就可以被其它主機接管。
4,高可用結構圖
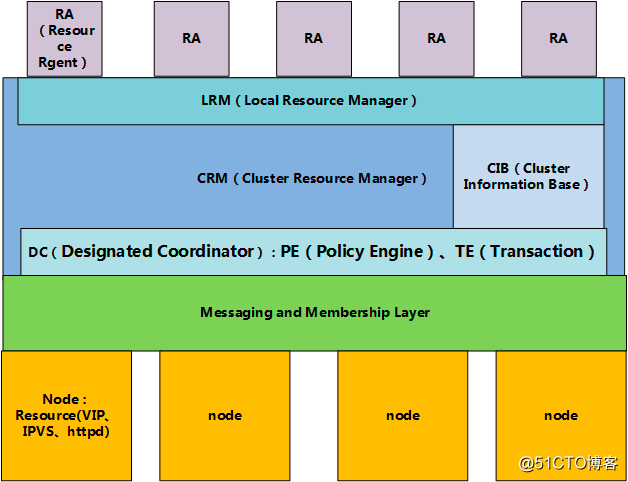
(1)Messaging and Membership Layer 信息傳遞層,傳遞集群信息的一種機制,通過監聽UDP 694號端口,可通過單播、組播、廣播的方式,實時快速傳遞信息,傳遞的內容為高可用集群的集群事務,例如:心跳信息,資源事務信息等等
(2)成員關系(Membership)層,這層最重要的作用是主節點(DC)通過Cluster Consensus Menbership Service(CCM或者CCS)這種服務由Messaging層提供的信息,來產生一個完整的成員關系。這層主要實現承上啟下的作用,承上,將下層產生的信息生產成員關系圖傳遞給上層以通知各個節點的工作狀態;啟下,將上層對於隔離某一設備予以具體實施。
(3)CRM(Cluster Resource Manager)集群資源管理器層,它主要是用來提供那些不具有高可用的服務提供高可用性的。它需要借助Messaging Layer來實現工作,因此工作在Messaging Layer上層。
資源管理器的主要工作是收集messaging Layer傳遞的節點信息,並負責信息的計算和比較,並做出相應的動作,如服務的啟動、停止和資源轉移、資源的定義和資源分配。
在每一個節點上都包含一個CRM,且每個CRM都維護這一個CIB(Cluster Information Base,集群信息庫),只有在主節點上的CIB是可以修改的,其他節點上的CIB都是從主節點那裏復制而來的。
CRM會推選出一個用於計算和比較的節點,叫DC(Designated coordinator)指定協調節點,計算由PE(Policy Engine)策略引擎實現,計算出結果後的動作控制由TE(Transition Engine)事務引擎實現。
在每個節點上都有一個LRM(local resource manager)本地資源管理器,是CRM的一個子功能,接收TE傳遞過來的事務,在節點上采取相應動作,如運行RA腳本等。
(4)LRM(Local Resource Manager)本地資源管理層
(5)RA(Resource Rgent)資源代理層,簡單的說就是能夠集群資源進行管理的腳本,如啟動start,停止stop、重啟restart和查詢狀態信息status等操作的腳本。LRM本地資源管理器負責運行。
資源代理分為:
Legacy heartbeat(heatbeat v1版本的資源管理);
LSB(Linux Standard Base),主要是/etc/init.d/*目錄下的腳,start/stop/restart/status;
OCF(Open Cluster Famework),比LSB更專業,更加通用,除了上面的四種操作,還包含monitor、validate-all等集群操作
STONITH:實現節點隔離
5,高可用常用組合案例
heartbeat v2+haresource(或crm) (說明:一般常用於CentOS 5.X)
heartbeat v3+pacemaker (說明:一般常用於CentOS 6.X)
corosync+pacemaker (說明:現在最常用的組合)
cman + rgmanager (說明:紅帽集群套件中的組件,還包括gfs2,clvm)
keepalived+lvs (說明:常用於lvs的高可用)
1,什麽是高可用性?
“高可用性”(High Availability)通常來描述一個系統經過專門的設計,從而減少停工時間,而保持其服務的高度可用性;
主要是避免軟件、硬件、人為造成的故障對業務的影響降低到最小程度,以保證服務不間斷地運行;
2,高可用性知識點
(1)計算機的高可用性
計算機系統的可用性用平均無故障時間(MTTF)來度量,即計算機系統平均能夠正常運行多長時間,才發生一次故障。系統的可用性越高,平均無故障時間越長。
可維護性用平均維修時間(MTTR)來度量,即系統發生故障後維修和重新恢復正常運行平均花費的時間。系統的可維護性越好,平均維修時間越短。
計算機系統的可用性定義為:MTTF/(MTTF+MTTR) * 100%。由此可見,計算機系統的可用性定義為系統保持正常運行時間的百分比。
基本可用性 99% 87.6小時
較高可用性 99.9% 8.8小時
具有故障自動恢復能力的可用性 99.99% 53分鐘
極高可用性 99.999% 5分鐘
(2)負載均衡服務器的高可用性
為了屏蔽負載均衡服務器的失效,需要建立一個備份機。主服務器和備份機上都運行High Availability監控程序,通過傳送諸如“I am alive”這樣的信息來監控對方的運行狀況。當備份機不能在一定的時間內收到這樣的信息時,它就接管主服務器的服務IP並繼續提供服務;當備份管理器又從主管理器收到“I am alive”這樣的信息時,它就釋放服務IP地址,這樣的主管理器就開始再次進行集群管理的工作了。為在主服務器失效的情況下系統能正常工作,我們在主、備份機之間實現負載集群系統配置信息的同步與備份,保持二者系統的基本一致。
自動偵測(Auto-Detect)階段由主機上的軟件通過冗余偵測線,經由復雜的監聽程序。邏輯判斷,來相互偵測對方運行的情況,所檢查的項目有:主機硬件(CPU和周邊)、主機網絡、主機操作系統、數據庫引擎及其它應用程序、主機與磁盤陣列連線。為確保偵測的正確性,而防止錯誤的判斷,可設定安全偵測時間,包括偵測時間間隔,偵測次數以調整安全系數,並且由主機的冗余通信連線,將所匯集的訊息記錄下來,以供維護參考。
(4)自動切換(Auto-Switch)階段 某一主機如果確認對方故障,則正常主機除繼續進行原來的任務,還將依據各種容錯備援模式接管預先設定的備援作業程序,並進行後續的程序及服務。
(6)高可用集群資源(HA Resource)和集群資源類型
集群資源是集群中使用的規則、服務和設備等,如VIP、httpd服務、STONITH設備等。類型如下:
Primitive:主資源,在某一時刻只能運行在某個節點上,如VIP。
group:組,使得多個資源同時停/啟等,一般只包含primitive資源。
clone:克隆,可以在多個節點運行的資源
master/slave:特殊的clone資源,運行在兩個節點上,一主一從
(7)自動切換選擇規則
根據資源的傾向(資源粘性、位置約束的分數比較)進行轉移;
資源的傾向(資源定位的依據):
A、資源粘性:資源對節點傾向程度,資源是否傾向於當前節點。score,正值傾向於當前節點(還要和位置約束結合)。
B、資源約束(Constraint):資源和資源之間的關系
a、排列約束 (colocation):資源間的依賴/互斥性,定義資源是否運行在同一節點上。score,正值表示要運行在同一節點上,負值則不可。
b、位置約束(location):每個節點都有一個score值,正值則傾向於本節點,負值傾向於其他節點,所有節點score比較,傾向於最大值的節點。
c、順序約束(order):定義資源執行動作的次序,例如vip應先配置,httpd服務後配置。特殊的score值,-inf 負無窮,inf 正無窮。
也就是說資源粘性定義資源對資源當前所在節點的傾向性,而位置約束定義資源對集群中所有節點的傾向性。如webip的資源粘性為100,位置約束對node1為200,當webip在node2上時,node2上線資源會轉移到node1,因為當前節點node2粘性100小於對node1的位置約束200;如webip的資源粘性為200,位置約束對node1為100,當webip在node2上時,node1上線資源不會轉移到node1,繼續留在node2上,因為當前節點node2粘性200大於對node1的位置約束100。
(8)處理不合法的集群節點
如果集群沒有對其進行Fecning/Stonith隔離前,可以進行相關配置(without_quorum_policy),有如下配置選項:
stop:直接停止服務;
ignore:忽略,以前運行什麽服務現在還運行什麽(雙節點集群需要配置該選項);
Freeze:凍結,保持事先建立的連接,但不再接收新的請求;
suicide:kill掉服務。
(9)集群腦裂(Split-Brain)和資源隔離(Fencing)
腦裂是因為集群分裂導致的,集群中有節點因為處理器忙或者其他原因暫時停止響應時,與其他節點間的心跳出現故障,但這些節點還處於active狀態,其他節點可能誤認為該節點"已死",從而爭奪共享資源(如共享存儲)的訪問權,分裂為兩部分獨立節點。
腦裂後果:兩個節點爭搶共享資源,結果會導致系統混亂,數據損壞。
腦裂解決:直接停止服務,或者忽略,但完全解決還需要資源隔離(Fencing)。
資源隔離(Fencing):
當不能確定某個節點的狀態時,通過fencing把對方幹掉,確保共享資源被完全釋放
節點級別:
STONITH(shoot the other node in the head,爆頭。硬件方式),直接控制故障節點的電源。
資源級別:
例如:FC SAN switch(軟件方式)可以實現在存儲資源級別拒絕某節點的訪問
3,工作方式
(1)主從方式 (非對稱方式)
工作原理:主機工作,備機處於監控準備狀況;當主機宕機時,備機接管主機的一切工作,待主機恢復正常後,按使用者的設定以自動或手動方式將服務切換到主機上運行,數據的一致性通過共享存儲系統解決。
(2)雙機雙工方式(互備互援)
工作原理:兩臺主機同時運行各自的服務工作且相互監測情況,當任一臺主機宕機時,另一臺主機立即接管它的一切工作,保證工作實時,應用服務系統的關鍵數據存放在共享存儲系統中。
(3)集群工作方式(多服務器互備方式)
工作原理:多臺主機一起工作,各自運行一個或幾個服務,各為服務定義一個或多個備用主機,當某個主機故障時,運行在其上的服務就可以被其它主機接管。
4,高可用結構圖
(1)Messaging and Membership Layer 信息傳遞層,傳遞集群信息的一種機制,通過監聽UDP 694號端口,可通過單播、組播、廣播的方式,實時快速傳遞信息,傳遞的內容為高可用集群的集群事務,例如:心跳信息,資源事務信息等等
(2)成員關系(Membership)層,這層最重要的作用是主節點(DC)通過Cluster Consensus Menbership Service(CCM或者CCS)這種服務由Messaging層提供的信息,來產生一個完整的成員關系。這層主要實現承上啟下的作用,承上,將下層產生的信息生產成員關系圖傳遞給上層以通知各個節點的工作狀態;啟下,將上層對於隔離某一設備予以具體實施。
(3)CRM(Cluster Resource Manager)集群資源管理器層,它主要是用來提供那些不具有高可用的服務提供高可用性的。它需要借助Messaging Layer來實現工作,因此工作在Messaging Layer上層。
資源管理器的主要工作是收集messaging Layer傳遞的節點信息,並負責信息的計算和比較,並做出相應的動作,如服務的啟動、停止和資源轉移、資源的定義和資源分配。
在每一個節點上都包含一個CRM,且每個CRM都維護這一個CIB(Cluster Information Base,集群信息庫),只有在主節點上的CIB是可以修改的,其他節點上的CIB都是從主節點那裏復制而來的。
CRM會推選出一個用於計算和比較的節點,叫DC(Designated coordinator)指定協調節點,計算由PE(Policy Engine)策略引擎實現,計算出結果後的動作控制由TE(Transition Engine)事務引擎實現。
在每個節點上都有一個LRM(local resource manager)本地資源管理器,是CRM的一個子功能,接收TE傳遞過來的事務,在節點上采取相應動作,如運行RA腳本等。
(4)LRM(Local Resource Manager)本地資源管理層
(5)RA(Resource Rgent)資源代理層,簡單的說就是能夠集群資源進行管理的腳本,如啟動start,停止stop、重啟restart和查詢狀態信息status等操作的腳本。LRM本地資源管理器負責運行。
資源代理分為:
Legacy heartbeat(heatbeat v1版本的資源管理);
LSB(Linux Standard Base),主要是/etc/init.d/*目錄下的腳,start/stop/restart/status;
OCF(Open Cluster Famework),比LSB更專業,更加通用,除了上面的四種操作,還包含monitor、validate-all等集群操作
STONITH:實現節點隔離
5,高可用常用組合案例
heartbeat v2+haresource(或crm) (說明:一般常用於CentOS 5.X)
heartbeat v3+pacemaker (說明:一般常用於CentOS 6.X)
corosync+pacemaker (說明:現在最常用的組合)
cman + rgmanager (說明:紅帽集群套件中的組件,還包括gfs2,clvm)
keepalived+lvs (說明:常用於lvs的高可用)
相關鏈接:
http://www.linux-ha.org/wiki/Main_Page
百度百科介紹:
https://baike.baidu.com/item/%E9%AB%98%E5%8F%AF%E7%94%A8%E6%80%A7/909038?fr=aladdin
高可用集群:
http://blog.csdn.net/tjiyu/article/details/52643096
https://www.cnblogs.com/rwxwsblog/p/6652872.html
高可用集群介紹