
mapreduce 詞頻統計
阿新 • • 發佈:2018-04-10
大數據 hadoop
- 基於八股文的形式編寫mapreduce 程序
- 打包jar 與測試運行處理
- wordcount 為例 理解mapreduce 並行計算原理
基於八股文的形式編寫mapreduce 程序
mapreduce java 代碼
package org.apache.hadoop.studyhdfs.mapredce; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; /** * * @author zhangyy * */ public class WordCountMapReduce extends Configured implements Tool{ // step 1: mapper class /** * public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> */ public static class WordCountMapper extends // Mapper<LongWritable,Text,Text,IntWritable>{ // map output value private final static IntWritable mapOutputValue = new IntWritable(1) ; // map output key private Text mapOutputKey = new Text(); @Override public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { System.out.println("map-input-key =" + key + " : map-input-value = " + value); // line value String lineValue = value.toString(); // split String[] strs = lineValue.split(" ") ; // iterator for(String str: strs){ // set map output key mapOutputKey.set(str); // output context.write(mapOutputKey, mapOutputValue); } } } // step 2: reducer class /** * public class Reducer<KEYIN,VALUEIN,KEYOUT,VALUEOUT> */ public static class WordCountReducer extends // Reducer<Text,IntWritable,Text,IntWritable>{ private IntWritable outputValue = new IntWritable() ; @Override public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { // temp: sum int sum = 0 ; // iterator for(IntWritable value: values){ // total sum += value.get() ; } // set output value outputValue.set(sum); // output context.write(key, outputValue); } } // step 3: driver public int run(String[] args) throws Exception { // 1: get configuration // Configuration configuration = new Configuration(); Configuration configuration = super.getConf() ; // 2: create job Job job = Job.getInstance(// configuration, // this.getClass().getSimpleName()// ); job.setJarByClass(this.getClass()); // 3: set job // input -> map -> reduce -> output // 3.1: input Path inPath = new Path(args[0]) ; FileInputFormat.addInputPath(job, inPath); // 3.2: mapper job.setMapperClass(WordCountMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); // ===========================Shuffle====================================== // 1) partitioner // job.setPartitionerClass(cls); // 2) sort // job.setSortComparatorClass(cls); // 3) combine job.setCombinerClass(WordCountReducer.class); // 4) compress // set by configuration // 5) group // job.setGroupingComparatorClass(cls); // ===========================Shuffle====================================== // 3.3: reducer job.setReducerClass(WordCountReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // set reducer number // job.setNumReduceTasks(3); // 3.4: output Path outPath = new Path(args[1]); FileOutputFormat.setOutputPath(job, outPath); // 4: submit job boolean isSuccess = job.waitForCompletion(true); return isSuccess ? 0 : 1 ; } public static void main(String[] args) throws Exception { // run job // int status = new WordCountMapReduce().run(args); // 1: get configuration Configuration configuration = new Configuration(); // ===============================Compress=================================== // configuration.set("mapreduce.map.output.compress", "true"); // configuration.set(name, value); // ===============================Compress=================================== int status = ToolRunner.run(// configuration, // new WordCountMapReduce(), // args ) ; // exit program System.exit(status); } }
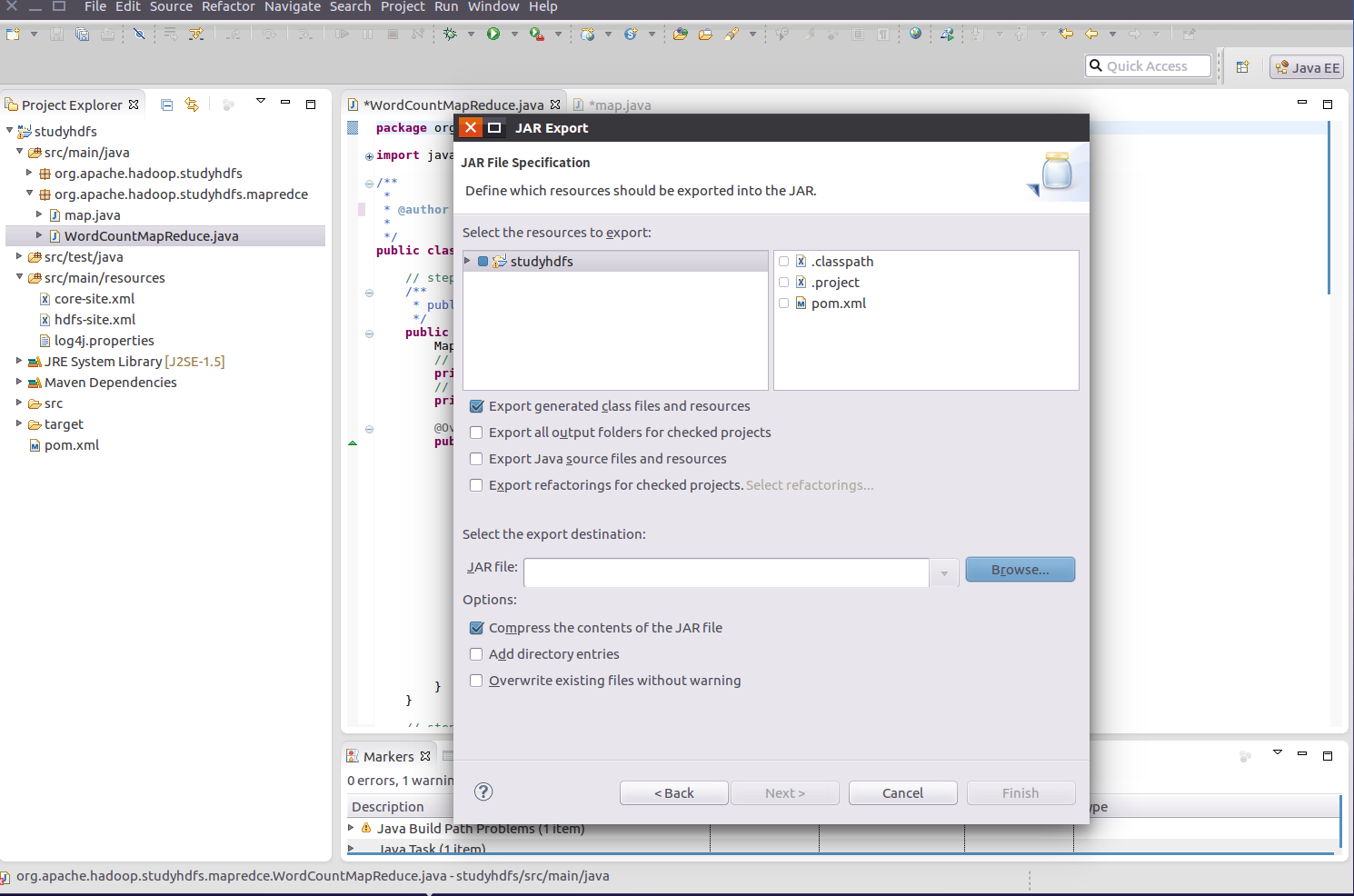
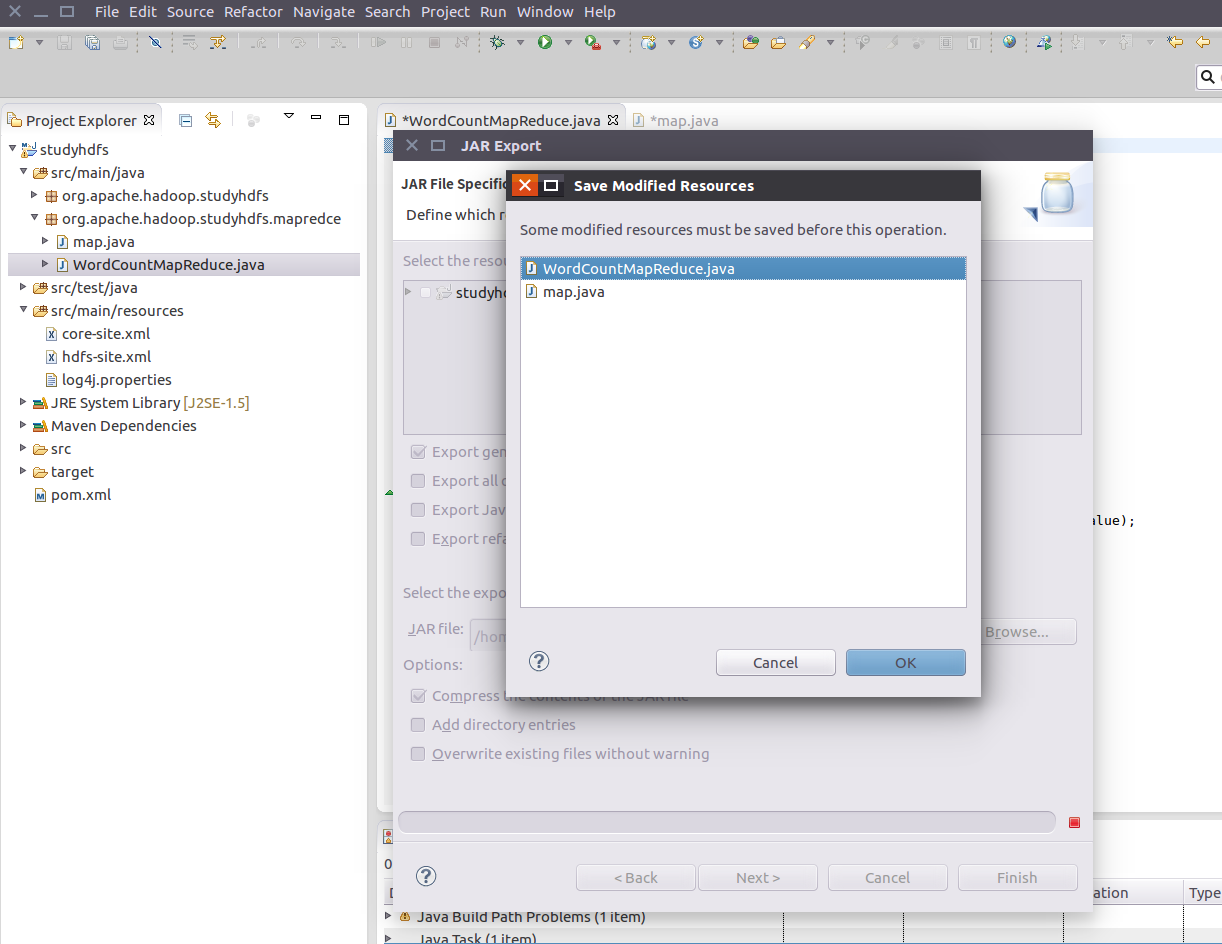
打包成為jar 包
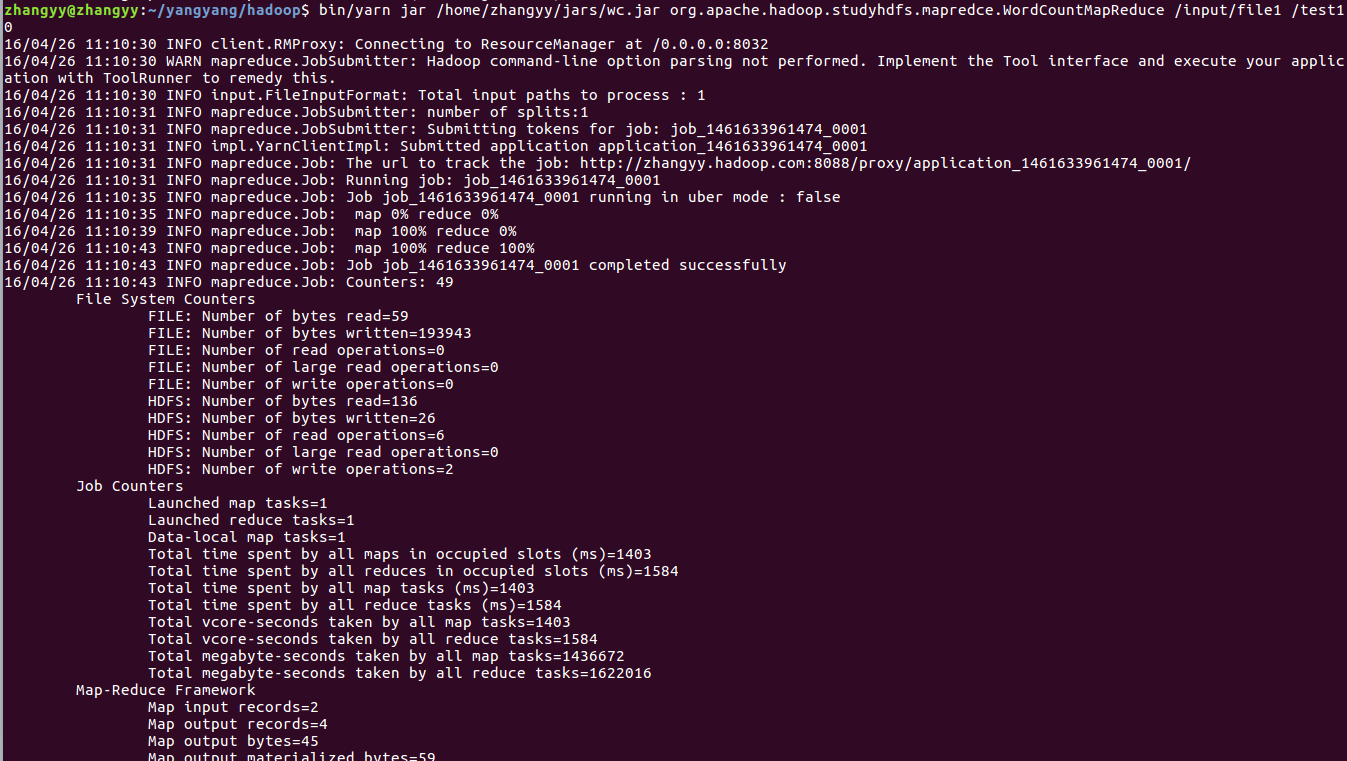
運行jar 包輸出結果
mapreduce 詞頻統計