
MySQL語法執行工作原理
目錄
[TOC]
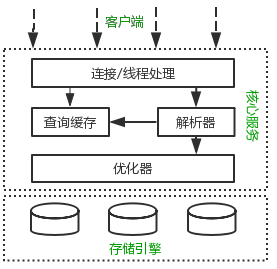
一、MySQL語法執行工作原理
客戶端請求由Nginx等負載均衡服務器轉交給Tomcat,Tomcat從MySQL中撈取數據,如果請求的數據在MySQL緩存中,那麽MySQL會將緩存中撈取到的數據返回給客戶端,如果緩存中沒有請求的數據,那麽MySQL會通過解析器解析SQL語法是否有問題(用戶權限問題),在SQL語法沒有問題的情況下,將SQL轉交給優化器,看SQL是否通過索引等來進行查詢,再通過存儲引擎在磁盤中撈取數據。
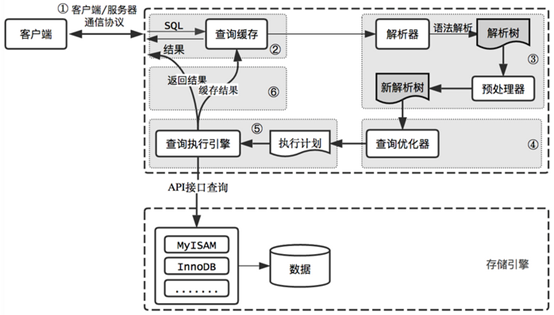
詳細流程如下,對於IE-->TOMCAT-->MySQL的流程,客戶端請求在到達Tomcat後,經歷路程如下:
① 先在Tomcat的JVM中撈取數據,如果撈取到對應數據,請求直接返回;
② 在MySQL緩存(緩存數據集、SQL語法、表定義、表權限、字段)中查詢數據,若查詢到,MySQL在將緩存中查詢到的數據返回給應用緩存時,會校驗一遍用戶權限,此時校驗用戶權限不會走解析器;若沒有命中緩存,就會來到解析和預處理環節。
③ 將SQL交給MySQL的第二層對SQL語句的語法進行解析,該層包括解析器以及預處理器。這裏的解析可以分為硬解析和軟解析,在SQL語法沒有問題的情況下,執行下一步操作。
解析器: 也叫語法解析器,SQL語句經過解析器解析之後,會生成一顆對應的解析數,在解析器中,MySQL會使用語法規則驗證和解析查詢,例如是否使用錯誤的關鍵字、使用關鍵字的順序是否正確、驗證引號是否能正確匹配等。
預處理器: 在預處理其中,進一步解析解析數是否合法並生成一顆新的解析數。例如:檢查數據表和數據列是否存在,SQL語句的名字和別名是否有歧義,之後預處理器還會校驗用戶權限(權限校驗一般會很快,除非服務器上有非常多的權限設置)。
硬解析: 通過硬件監聽,例如SELECT * FROM STUDENT WHERE id=‘test001‘,解析SQL語句以及對應操作用戶的權限,對於一個類型的SQL,在第一次查詢的過程中,都是硬解析,查詢速度較慢。
軟解析: 在查詢SELECT * FROM STUDENT WHERE id=‘test002‘
④ 在生成了解析樹之後,便來到查詢優化器這一層,在查詢優化器中,將解析數轉化為執行計劃,一般一條查詢語句可以由多種執行計劃完成,優化器的工作是從這些執行方式中找到性能最好的執行計劃。
全表掃描: SELECT * FROM TABLE_NAME WHERE ...,將一張表無論什麽樣的數據,都全部一次性從硬盤中撈出來,這樣的方式,在表中數據量較大的情況下,磁盤IO會比較大,造成CPU使用率較高(監聽IO事件)。
索引掃描: 主鍵索引、普通索引、唯一性索引、全文索引(介紹鏈接:https://www.cnblogs.com/qianzf/p/7131760.html)
⑤ 找到最優的執行計劃以後,MySQL調用查詢執行引擎(InnoDB、MyISAM)在磁盤中撈取數據。
1.1 案例
案例1:
存在一張表,表名為table1,字段有id,name,age等字段,id為主鍵;同時存在第二張表,表名為table2,表字段以及數據和table1一樣,但是無主鍵,無索引,現有下列SQL
SELECT * FROM table1 WHERE id = 1;
SELECT * FROM table2 WHERE id = 1;
SELECT * FROM table1;
SELECT * FROM table2; 上述SQL語句,均會通過I/O從磁盤中撈取一張表的全部數據,無論是否使用WHERE語句,是否使用索引,但是使用索引之後,數據庫會通過索引到緩存中撈取數據,查詢效率特別高。
案例2:
場景:
存在一張表,表名為table1,字段有id,name,age等字段,如果先到兩條SQL如下:
SELECT * FROM table1 WHERE id = 1;SELECT * FROM table1 WHERE id = 2;第一條SQL類似語法到達MySQL完成解析返回結果後,第二條SQL是否能夠命中緩存?
分析:
對於SQL語句到達MySQL在緩存中撈取數據時,會將這條SQL進行hash操作,這條SQL即使大小寫不同,語法一樣,但變量不同,都不會命中MySQL的緩存,此時,第二條SQL會到解析器中,但是,MySQL已經在解析器和預處理器中分析了第一條SQL的語法,得到了對應的解析計劃,而第二條SQL和第一條SQL的語法相同,只是變量變化,所以在MySQL緩存中,仍然緩存了這條SQL的解析計劃,在第二條SQL進入解析器時,會在MySQL緩存中撈取語法解析結果,如果命中,那麽就會走軟解析的路線,提高SQL語句的查詢性能。
二、從MySQL語法執行原理談性能測試
2.1 混合場景測試以及長時間穩定性測試的必要性
由於數據庫的緩存機制和鎖機制,在混合業務線以及大並發的過程中,當增刪改查業務線並行的情況下,會出現資源爭用的現象,進行混合場景測試,可以觀察是否出現死鎖現象,而如果數據庫緩存設置不合理,在混合場景以及長時間的穩定性測試的過程中,實時的大數據量查詢過程中,前面查詢得到的數據庫緩存被過早的清除掉,導致數據庫頻繁的對SQL語句進行解析,增大系統I/O以及數據庫查詢的時間,影響系統性能,綜上所述,對典型交易做混合場景測試以及長時間穩定性測試來驗證測試過程中對資源爭用情況的處理是否合理,緩存空間配置是否充足,從而完成系統的高可靠性以及高可用性測試。所以,對於SQL語句而言,統一大小寫是十分重要的。
2.2 數據庫緩存設置大小和性能的關系
如2.1所述,數據庫緩存設置太小,數據庫緩存清理過快,影響系統性能,此外,對於基於MySQL主從庫容災集群部署的系統如果數據庫緩存配置的比較大,在一臺數據庫服務器宕機的情況下,除了在切換的瞬間查詢效率比較慢外,建立緩存後,可以保證查詢的部分性能。
三、數據庫服務器緩存配置策略
一般來說,數據庫緩存越大,數據庫的性能越好,所以在物理內存足夠大的情況下,可以盡量配置多一點的內存給數據庫。如果物理額內存8G,可以配置65%給數據庫,如果物理內存4G,可以配置1/3給數據庫,對於2G的物理內存,看情況進行配置。一般而言,在將SQL語法等問題都排除了,再來考慮數據庫的內存配置問題。
四、各數據庫集群部署方式
Oracle
自帶集群部署方式(RAC)。
MySQL
MySQL本身不支持集群部署,但是通過第三方工具,可以做到主從配置的方式完成集群部署。
PostgreSQL
可使用PostgreSQL自帶的工具(pgpool),完成集群部署。
MySQL語法執行工作原理