
深度學習-機器學習 第一篇
簡介
前置聲明:本專欄的所有文章皆為本人學習時所做筆記而整理成篇,轉載需授權且需註明文章來源,禁止商業用途,僅供學習交流.(歡迎大家提供寶貴的意見,共同進步)
正文:
機器學習,顧名思義,就是研究計算機如何學習和模擬人類的行為,並根據已學得的知識對該行為進行增強和改進。
舉例來說,假設郵箱收到了一封新郵件,通常我們可以通過郵件裏是否含有廣告、不相關信息以及亂碼等特征,人為的來判斷這封郵件是否是一封垃圾郵件。

如上述可知,機器學習模擬人類的行為,所以它同樣依據這些郵件內容的特征來判斷一封郵件是否是垃圾郵件。那麽計算機是如何判斷郵件內容裏那些是廣告和垃圾信息的呢? 我們知道,在我們剛出生的時候,大家都不知道世間那些事情是好的,那些事情是壞的,都是爸爸媽媽告訴我們說:打人是不對的,幫助他人才是該做的。同理,尚未學習的計算機剛開始也不能獨立思考,為了讓它區分垃圾郵件和正常郵件,所以我們必須需要告訴它,郵件裏的內容那些是廣告和垃圾信息,那些是正常的內容。這一過程是機器學習的核心過程,通過這一核心過程,計算機便有了初步的對於郵件垃圾與否的“知識”,正如我們學了加減乘除後便可以做簡單的運算。
機器學習的核心過程一般分為包含如下模塊:
- 訓練數據集:訓練數據集是機器學習的“課本”,如郵件訓練數據集,其中包含了各種各樣的郵件,其中每個郵件都有一個標識,用來表示其為正常郵件還是垃圾郵件。典型的數據格式如:郵件1,1;郵件2,0,;郵件3,1;其中0表示正常郵件,1表示垃圾郵件,因此可以看出郵件1和3為垃圾郵件,郵件2為正常郵件;
- 學習算法:計算機通過機器學習算法對訓練數據集進行分析,並建立最終的模型。即通過對“課本”的學習,建立一套自己的解題方案。如通過對郵件數據集的學習後,當收到新郵件時,通過模型便可判斷該郵件是否是垃圾郵件。模型的最終生成以及其性能的高低依據選擇的機器算法而定。
- 測試模型:通過某些測試數據[類別未知]對模型進行測試,如輸入多封新郵件測試模型能夠將郵件正確分類的效果,若達不到預期效果則需要調整學習算法的參數。
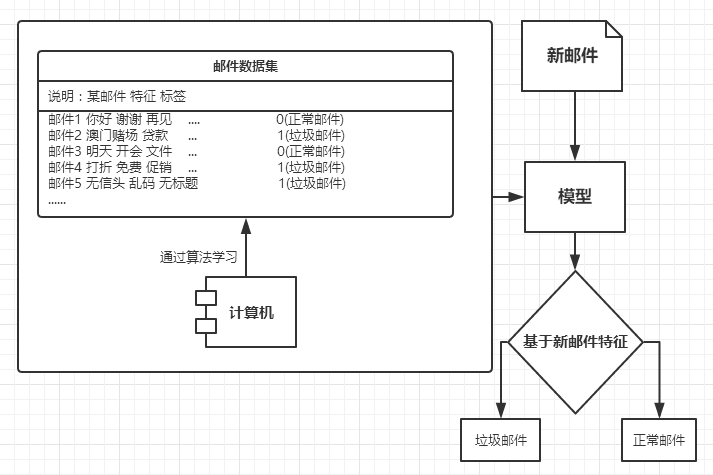
機器學習算法有很多,大致分為監督學習算法和無監督學習算法。
監督學習:訓練數據集的類別已知,如上文提到的郵件訓練數據集,通過對訓練數據集的學習生成模型。好比面前有一位老師告訴了你題目的方法和答案,,當你了解了老師教你的方法時,面對的新的題目便可自行解答。
監督學習的算法:
- 分類算法 —— K-近鄰算法、決策樹、樸素貝葉斯算法、Logistic回歸、etc.
- 預測算法 —— 局部加權線性回歸、線性回歸、支持向量、Ridge回歸、Lasso最小回歸系數估計、etc.
無監督學習:數據集的類別未知,如草原上一群未被標記的動物,起初不知道這些動物該如何分類,但通過觀察這些動物的特征便可知道,可以將體格壯的分為一類(大型動物),食草的分為一類(食草動物)以及爬行的分為一類(爬行動物)等,因此無監督學習也是通過對數據集的特征進行分析,根據特征相似性對數據集進行分類。
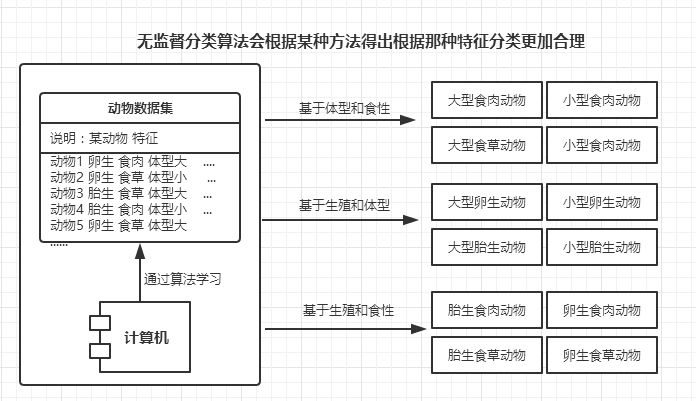
無監督學習算法:K-均值、最大期望算法、DBSCAN、Parzen窗設計、etc.
[上述提到的機器算法會在後續中一 一講解]
總之,機器學習通過算法對訓練數據集進行學習,生成最終的模型,並用此模型模擬人類行為對新輸入進行判斷。
機器學習模型除了可以分辨垃圾郵件外,還可以做很多事情,比如根據對超市顧客購物清單的學習分析,可知買了尿布的顧客會順便買一罐啤酒,因此超市可將尿布和啤酒放在一起從而提高銷量;通過對圖書館借書記錄的分析,可以將相似的書籍推薦給讀者;對購買產品記錄的分析,網站會提示買家該產品的最佳搭配產品或者提示買家其他顧客除了購買該產品還購買了哪些與之搭配的產品;通過對房子的特征及其房價的數據分析,可以預測某種房子的房價;通過對文本的分析對大量的文章進行自動分類......。機器學習可以做很多自動化的事情,從而提高效率。
在學習機器學習算法的理論及代碼實現前,需要如下幾個前提:
- 高等數學、線性代數、概率論與數理統計的基礎 (至少了解概念)
- 編程基礎 (Java、C++、Python 等都可作為實現機器學習算法的語言) [建議:Python,Python包含眾多的科學計算包,更容易更方便實現其算法]
Python機器學習環境搭建
若未接觸過Python,需要看下Python的基礎語法,不過代碼裏面我會寫上詳細註釋。
正如安裝Java一樣,我們需要去官方網站下載JDK,Python類似,Python分為2.7和3.6版本,本專欄選擇使用2.7版本。
安裝好Python後,還需要安裝機器學習所需要的Python科學計算包 ,例如:numpy+mkl、scipy、matplotlib等。不過這裏我們並不安裝原始的Python版本,而是安裝anaconda,它是Python的一個發行版本,安裝好它後就不用再去下載上述Python包,其本身已經包含了,比較方便。
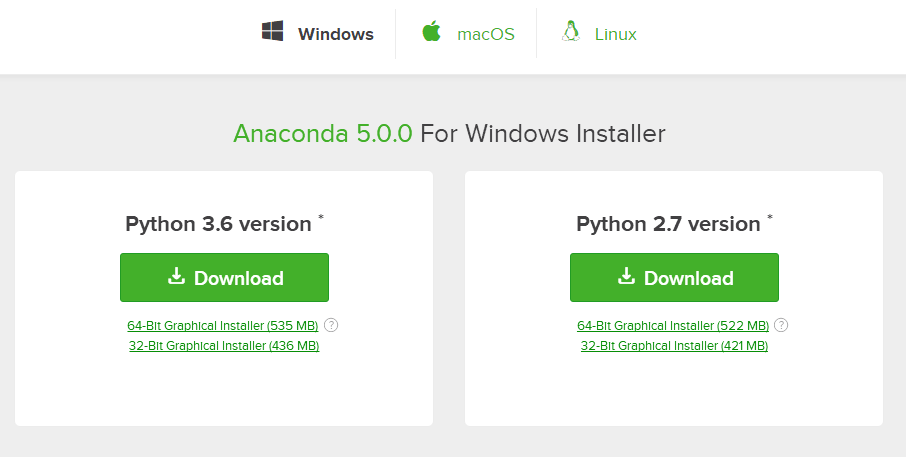
anaconda下載地址:Downloads 選擇Python 2.7 version下載
安裝步驟在此略過。
安裝好後打開Anaconda Navigator 如圖:

啟動後如圖所示:
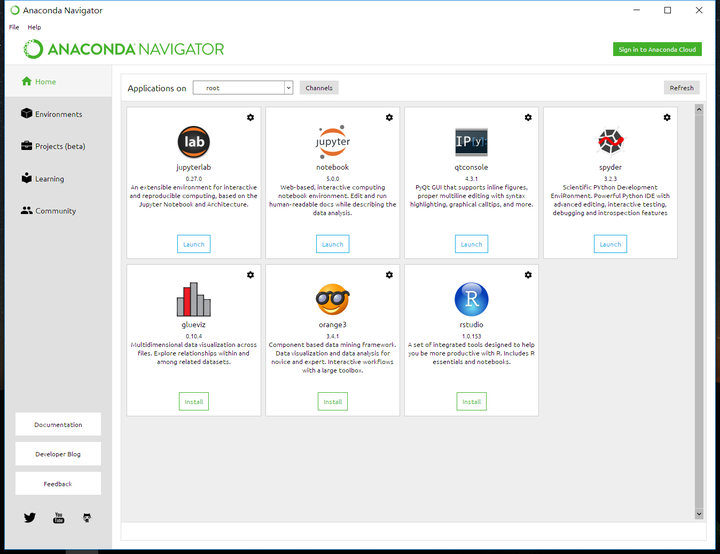
lauch spyder,spyder是Anaconda下的一個Python集成開發環境,正如Java之於Eclipse,.net之於Visual Studio .其他工具後續再說。

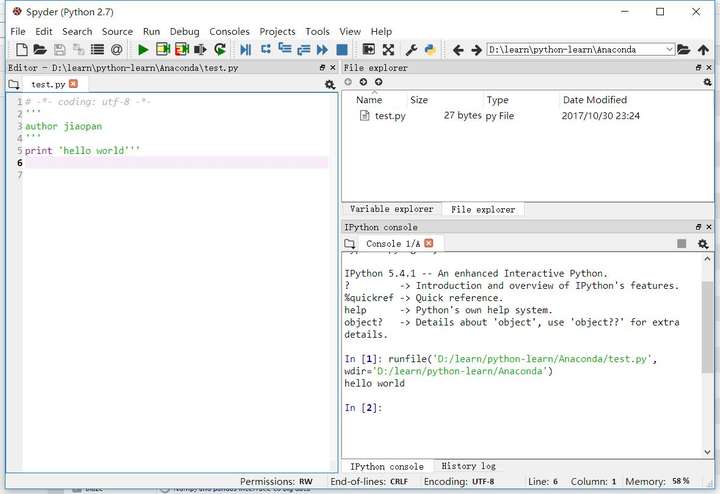
當然按照慣例 輸出 hello world
機器學習的簡介和Python開發環境的搭建到此結束,後續將會依次講解機器學習的算法、數學知識以及算法的推導過程。
2017/10/30 阿弎
深度學習-機器學習 第一篇