
原始碼學習【HashMap第一篇】HashMap到底是怎麼put的?
HashMap到底是怎麼put 的?
這是我的專欄的第一篇,有任何錯誤,希望大家不吝賜教,共同學習。
寫這個專欄主要是自己學習原始碼的過程,如果對別人能有所幫助,不勝開心~
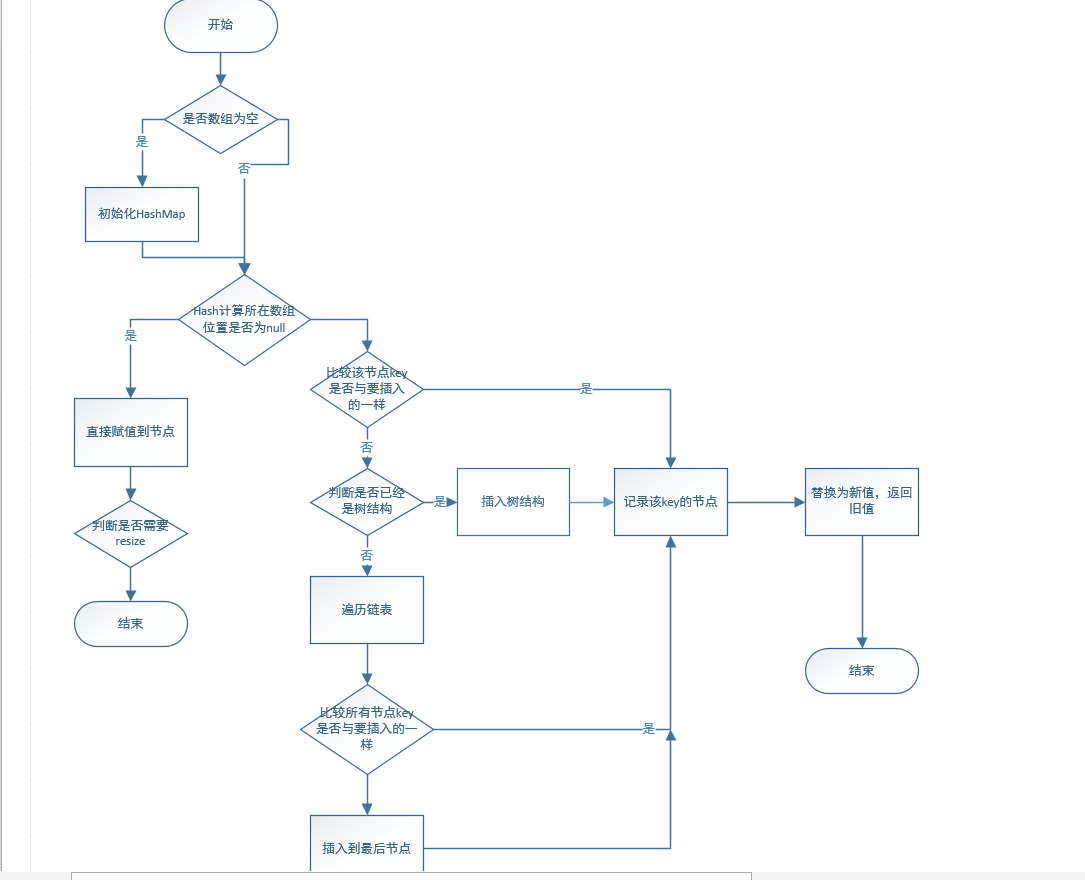
Put的流程:
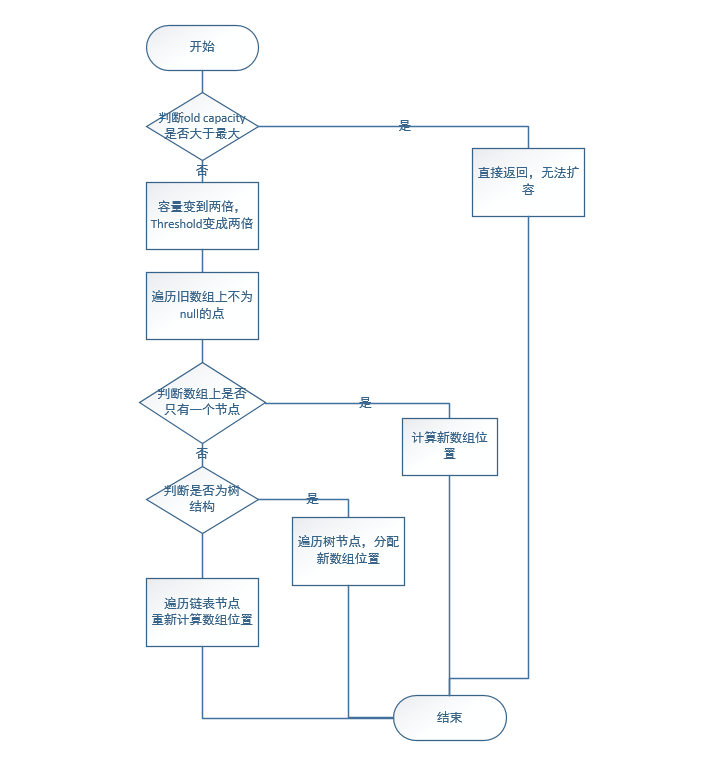
resize流程圖:
關於HashMap中的紅黑樹這裡不做討論,後續可能會進行原始碼分析
直接上原始碼,jdk1.8 put
程式碼片段一
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { // putVal(hash(key), key, value, false, true); // hash是key的hash值,具體演算法見方法,key是put時的key,value是put的value,onlyIfAbSent = false,evict = true; Node<K,V>[] tab; Node<K,V> p; int n, i; // 如果為該Map為空尚未初始化,則呼叫resize進行初始化,n = 初始化後table的大小16。 //==========================resize過程見程式碼片段二=================================== if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; // 如果在計算出來的table陣列的第i個位置上,p = null 還沒有節點,則建立一個節點即可。(i = (n - 1) & hash),這個計算方法是完成了類似%的操作,並且因為n-1始終是2進位制的1111...,所以在table陣列上的位置均分。 // p = table[i]; if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); // 如果在第i個位置上已有節點,即p!=null則進入else方法塊。 else { Node<K,V> e; K k; // 陣列table第i個元素的第一個節點 的hash值 = 要put的key的hash值,要put的key如果等於在這個節點上的key(包括null情況,這也就說明,hashMap的key可以為null,但是隻能有一個)。 // 在這種情況下則將當前節點用e指代 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; // 如果p(table第i個元素的第一個節點 的hash值 ) 為 TreeNode,則將新節點放入HashMap裡自定義的紅黑樹。putTreeVal方法會自己完成樹的平衡 else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); // table第i個元素的第一個節點 不滿足上述情況(第一個節點和put進來的key不一樣 + 不為TreeNode),則進入這個方法塊。 else { //遍歷table第i個元素上的連結串列,從頭開始遍歷,見第一行e = p.next 和for迴圈最後一行p = e。 for (int binCount = 0; ; ++binCount) { //遍歷到p 的next節點為null的時候,則 p.next指向新節點。(所以hashMap的連結串列上有新節點時都是在連結串列尾部插入。) //e = p.next ;p.next = newNode 這句則是將當前節點記錄,用e指代。 if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); //插入到binCount到7的時候,即連結串列上的元素為第八個,插入了第九個的時候,則將這個連結串列轉變為紅黑樹,使用treeifyBin方法。 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } //如果迴圈到一個節點,且滿足 【hash值 = 要put的key的hash值,要put的key如果等於在這個節點上的key(包括null情況,這也就說明,hashMap的key可以為null,但是隻能有一個)】 // 則將當前節點記錄,用e指代。 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } //由上面的程式碼執行完,則e肯定是指代了一個當前節點,key與要put的key一致,如果已有值,則value 是oldValue,如果沒有,則是新的value // 下面的程式碼執行結束,則返回一個value(如果已有則為old,否則為插入的)可以使用map.put(k,v) == v 來判斷hashMap以前有沒有儲存過這個key。 //並返回。 if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; //預留方法,LinkedList使用 afterNodeAccess(e); return oldValue; } } // 如果是【在第i個位置上已有節點,即p!=null則進入else方法塊。】這個條件,則會在上面return,所以在這裡的程式碼都是第i個節點上沒有資料的情況才會執行,即resize這個方法只會在往陣列的一個新位置上插入資料的時候才會觸發(其實是廢話,resize就是table的size不夠的情況)。 ++modCount; //size為table陣列上有資料的數量,如果size大於threshold時則擴容。 if (++size > threshold) //=====================================這裡擴容時的resize見程式碼片段三==================================== resize(); //預留方法,LinkedList使用 afterNodeInsertion(evict); //返回null。 return null; }
程式碼片段二
// 在初始化的時候的呼叫場景 final Node<K,V>[] resize() { //空 Node<K,V>[] oldTab = table; // 0 int oldCap = (oldTab == null) ? 0 : oldTab.length; //0 int oldThr = threshold; int newCap, newThr = 0; //不進去 if (oldCap > 0) { if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; } else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1; // double threshold } //不進去 else if (oldThr > 0) // initial capacity was placed in threshold newCap = oldThr; //進去,設定容量為預設容量為16 ,threshold = 12 else { // zero initial threshold signifies using defaults newCap = DEFAULT_INITIAL_CAPACITY; newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); } //不進去,已被賦值 if (newThr == 0) { float ft = (float)newCap * loadFactor; newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); } //繼續賦值,threshold是成員變數 threshold = newThr; //創建出一個newTab,陣列大小為 newCap = 16 @SuppressWarnings({"rawtypes","unchecked"}) Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; //將變數 table 設定為剛才創建出來的newTab。 table 是成員變數。 //總結一下,這個方法在初始化的時候只是將table設定為初始化的大小為16的陣列,threshold =12。 table = newTab; //不進去 if (oldTab != null) { for (int j = 0; j < oldCap; ++j) { Node<K,V> e; if ((e = oldTab[j]) != null) { oldTab[j] = null; if (e.next == null) newTab[e.hash & (newCap - 1)] = e; else if (e instanceof TreeNode) ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); else { // preserve order Node<K,V> loHead = null, loTail = null; Node<K,V> hiHead = null, hiTail = null; Node<K,V> next; do { next = e.next; if ((e.hash & oldCap) == 0) { if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } else { if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); if (loTail != null) { loTail.next = null; newTab[j] = loHead; } if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; } } } } } return newTab; }
程式碼片段三
final Node<K,V>[] resize() { //將要擴容的table,容量到達0.75*capacity Node<K,V>[] oldTab = table; //當前的capacity int oldCap = (oldTab == null) ? 0 : oldTab.length; //當前的threshold int oldThr = threshold; //設定新的容量和threshold int newCap, newThr = 0; //擴容時進入 if (oldCap > 0) { //如果已經到達int最大值,則只能這樣了...直接返回不擴容(所以,也不是到了就擴容,畢竟有上限)。 if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; } //如果還沒到,則新的容量設定為老的容量的2倍,threshold也變成以前的兩倍(16->32...) else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1; // double threshold } else if (oldThr > 0) // initial capacity was placed in threshold newCap = oldThr; else { // zero initial threshold signifies using defaults newCap = DEFAULT_INITIAL_CAPACITY; newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); } //不進去,已被賦值 if (newThr == 0) { float ft = (float)newCap * loadFactor; newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); } threshold = newThr; //建立一個新的陣列,容量為新容量(2倍老容量) @SuppressWarnings({"rawtypes","unchecked"}) Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; //這裡將成員變數設定為新的陣列(在這時候如果put,則可能會有問題,想想) table = newTab; //擴容時進入 if (oldTab != null) { //遍歷舊的陣列 for (int j = 0; j < oldCap; ++j) { Node<K,V> e; //用e指向舊陣列的遍歷到的位置,如果不為空,則進入,為空則不用管。 if ((e = oldTab[j]) != null) { oldTab[j] = null; //如果e.next==null,則是隻有一個元素,則只需要將這個元素 e 平移到新陣列上即可。newTab[e.hash & (newCap - 1)] = e if (e.next == null) newTab[e.hash & (newCap - 1)] = e; //如果這個位置上的儲存結構是樹結構,則進行分割這個樹結構到新陣列上,與下面的else情況類似,分為在新陣列的老位置還是新位置。 else if (e instanceof TreeNode) ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); //除此的情況,不是隻有1個元素,且不是樹結構(連結串列大小小於8),則進入。 else { // preserve order //這裡的處理我第一次看到的時候覺得很是佩服。 //定義兩個Node,一個低位Node loHead ,一個高位Node hiNode,為什麼高,為什麼低下面說。 Node<K,V> loHead = null, loTail = null; Node<K,V> hiHead = null, hiTail = null; Node<K,V> next; // 迴圈遍歷e開頭的連結串列,直到 e 的最後一個節點 do { next = e.next; //遍歷過程中,如果 e 滿足 (e.hash & oldCap) == 0 則將這個節點放到 loHead連結串列。 //這裡這麼處理的原因是 oldCap 一定是2的冪次方,在2進位制下為10000....這種,所以當e.hash如果滿足(e.hash & oldCap) == 0 時則說明,e的高位也為0。而newCap-1 的二進位制是1111111...(與oldCap的長度一樣) //比如16擴容後變成32 ,則oldCap = 10000,newCap -1 = 11111; //在這種情況下,前面說過e的高位為0。其實e.hash &(newCap -1)實際上的最高位肯定 =0 ,而如果高位等於0,則e.hash &(newCap -1) == e.hash &(oldCap -1),這個元素則新舊陣列table中的位置肯定是一個。 // 所以還在第j 個位置。 //如果不為0 ,則高位為1,則e.hash &(newCap -1) = e.hash &(oldCap -1) + 10000...(oldCap的二進位制) if ((e.hash & oldCap) == 0) { if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } // 不滿足的 (e.hash & oldCap) != 0 則將這個節點放到 hiTail 連結串列。 else { if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); //遍歷完畢,if滿足部分進入陣列的原有位置 j ,else 滿足部分進入 陣列新位置 j+oldCap 。 if (loTail != null) { loTail.next = null; newTab[j] = loHead; } if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; } } } } } //返回新陣列,結束擴容。 return newTab; }
相關推薦
原始碼學習【HashMap第一篇】HashMap到底是怎麼put的?
HashMap到底是怎麼put 的? 這是我的專欄的第一篇,有任何錯誤,希望大家不吝賜教,共同學習。 寫這個專欄主要是自己學習原始碼的過程,如果對別人能有所幫助,不勝開心~ Put的流程: resize流程圖: 關於HashMap中的紅黑樹這裡不做討論,後續
python學習【第三篇】基本數據類型
ini ati 絕對值 ef6 ict trunc any 替換 不包含 Number(數字) int(整型) 在32位機器上,整數的位數為32位,取值範圍為-2**31~2**31-1,即-2147483648~2147483647 在64位系統上,整數的位數為6
MySQL數據庫學習【第三篇】增刪改查操作
自增id 命令 位置參數 modify 刪除一行 style 主鍵 客戶端 drop 註意:1.如果你在cmd中書命令的時候,輸入錯了就用\c跳出 2.\s查看配置信息 一、操作文件夾(庫) 增:create database db1 charset utf8;
MySQL數據庫學習【第五篇】完整性約束
png 唯一約束 not null 會話 glob -- delet 初始 -a 一、介紹 約束條件與數據類型的寬度一樣,都是可選參數 作用:用於保證數據的完整性和一致性主要分為: PRIMARY KEY (PK) 標識該字段為該表的主鍵,可以唯一的標識記錄 FO
MySQL數據庫學習【第七篇】單表查詢
not null for 比較運算符 創建 字符串 直接 過濾 field gpo 先創建表 #創建表 create table employee( id int not null unique auto_increment, name varchar(20) not
MySQL數據庫學習【第九篇】索引原理與慢查詢優化
xxx 結構 復合 unix select查詢 全文搜索 等等 學習 獲取數據 一、介紹 1.什麽是索引? 一般的應用系統,讀寫比例在10:1左右,而且插入操作和一般的更新操作很少出現性能問題,在生產環境中,我們遇到最多的,也是最容易出問題的,還是一些復雜的查詢操作,因此對
MySQL數據庫學習【第十篇】(視圖、觸發器、事物)
註意 onf action 聲明 concat_ws base 循環 5-0 print 一、視圖 視圖是一個虛擬表(非真實存在),其本質是【根據SQL語句獲取動態的數據集,並為其命名】,用戶使用時只需使用【名稱】即可獲取結果集,可以將該結果集當做表來使用。 使用視圖我們可
Python學習【第2篇】:Python之數據類型
msg ear sleep abc 命令 play bbbb 朋友 == 數字類型和字符串類型 1.bin()函數將十進制轉換成而進制 2.oct()函數將十進制轉換成八進制 3.hex()函數將十進制轉換成十六進制 十六進制表示:0-9 a b c
Python學習【第2篇】:Python之數據類型(2)
append 但是 iss 代碼 key 常用方法 uber ner ces 元組 #為何要有元組,存放多個值,元組不可變,更多的是用來做查詢 t=(1,[1,3],‘sss‘,(1,2)) #t=tuple((1,[1,3],‘sss‘,(1,2))) #
python學習【第四篇】python函數
none 表達 return語句 開頭 bject 內容 python函數 實現 模塊 一、函數的介紹 函數是組織好的,可重復使用的,用來實現單一,或相關聯功能的代碼段。 函數能提高應用的模塊性,和代碼的重復利用率。你已經知道Python提供了許多內建函數,比如print(
python學習【第四篇】python函數 (二)
運行時 本質 接收參數 hello 函數 作用域 返回 高階函數 clas 一、裝飾器 裝飾器:本質就是函數,功能是為其它函數添加附加功能 裝飾器的原則: 不修改被修飾函數的源代碼 不修改被修飾函數的調用方式 裝飾器的知識儲備: 裝飾器 = 高階函數 + 函數嵌套
Python學習【第4篇】:元組魔法
vaule 根據 取值 保留 列表 tuple 樣書 key值 推薦 tu = (111,"xiaoxing",(11,22),[(33,44)],45,)#1.書寫格式#一般寫元組的時候推薦在最後加入逗號,#元組中的一級元素不可被修改,不能增加或者刪除print(tu)#
python學習【第九篇】python面向對象編程
同名方法 ron 重寫 結構 程序 如果 覆蓋 -a base 一、面向對象了解 面向對象編程——Object Oriented Programming,簡稱OOP,是一種程序設計思想。OOP把對象作為程序的基本單元,一個對象包含了數據和操作數據的函數。 Pytho
Python學習【第5篇】:數據類型和變量總結
style 不可變 nbsp 重新 class 數據 發現 舉例 convert 字符串,數字,列表,元組,字典 可變不可變 1.可變:列表 如: p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 11.0px Menlo; col
【博弈論第一篇】三姬分金(帝王為何殺功臣)
帝王為何殺功臣,大副如何謀位船長,傻B的另一種解釋…… 三姬分金 假設有A,B,C三個人,分100枚金幣。怎麼分呢?我們定一個規則,按順序提議,就是A先提議,B,再C,並且如果未超半數以上,不包括半數,同意提議,自己也有投票權。 前提假設: 三人很聰明,追求
【全網第一篇】Gibson Env 搭建復現和使用解讀
專案網址:http://gibson.vision 論文:http://gibson.vision/Gibson_CVPR2018.pdf 官方github連結:https://github.com/StanfordVL/GibsonEnv 入選 CVPR2018 年的專案 Gibs
Flask學習【第3篇】:藍圖、基於DBUtils實現資料庫連線池、上下文管理等 基於DBUtils實現資料庫連線池
基於DBUtils實現資料庫連線池 小知識: 1、子類繼承父類的三種方式 class Dog(Animal): #子類 派生類 def
Flask學習【第2篇】:Flask基礎 Flask基礎
Flask基礎 知識點回顧 1、flask依賴wsgi,實現wsgi的模組:wsgiref,werkzeug,uwsgi 2、例項化Flask物件,裡面是有引數的 app = Fla
Flask學習【第7篇】:Flask中的wtforms使用 flask中的wtforms使用
flask中的wtforms使用 一、簡單介紹flask中的wtforms WTForms是一個支援多個web框架的form元件,主要用於對使用者請求資料進行驗證。 安裝: pip3 install
Flask學習【第11篇】:整合Flask中的目錄結構 整合Flask中的目錄結構
整合Flask中的目錄結構 一、SQLAlchemy-Utils 由於sqlalchemy中沒有提供choice方法,所以藉助SQLAlchemy-Utils元件提供的choice方法