
Scrapy-redis改造scrapy實現分布式多進程爬取
阿新 • • 發佈:2018-05-03
ads 爬取 eml rip push pri ruby lis article
一.基本原理:
Scrapy-Redis則是一個基於Redis的Scrapy分布式組件。它利用Redis對用於爬取的請求(Requests)進行存儲和調度(Schedule),並對爬取產生的項目(items)存儲以供後續處理使用。scrapy-redi重寫了scrapy一些比較關鍵的代碼,將scrapy變成一個可以在多個主機上同時運行的分布式爬蟲。
參考Scrapy-Redis官方github地址
二.準備工作:
1.安裝並啟動redis,Windows和lunix可以參考這篇
2.scrapy+Python環境安裝
3.scrapy_redis環境安裝
$ pip install scrapy-redis
$ pip install redis 三.改造scrapy爬蟲:
1.首先在settings.py中配置redis(在scrapy-redis 自帶的例子中已經配置好)
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = True
SCHEDULER_QUEUE_CLASS = ‘scrapy_redis.queue.SpiderPriorityQueue‘
REDIS_URL = None # 一般情況可以省去
REDIS_HOST = ‘127.0.0.1‘ # 也可以根據情況改成 localhost
REDIS_PORT = 6379 2.item.py的改造
from scrapy.item import Item, Field
from scrapy.loader import ItemLoader
from scrapy.loader.processors import MapCompose, TakeFirst, Join
class ExampleItem(Item):
name = Field()
description = Field()
link = Field()
crawled = Field()
spider = Field()
url = Field()
class ExampleLoader(ItemLoader):
default_item_class = ExampleItem
default_input_processor = MapCompose(lambda s: s.strip())
default_output_processor = TakeFirst()
description_out = Join() 3.spider的改造。star_turls變成了redis_key從redis中獲得request,繼承的scrapy.spider變成RedisSpider。
from scrapy_redis.spiders import RedisSpider
class MySpider(RedisSpider):
"""Spider that reads urls from redis queue (myspider:start_urls)."""
name = ‘myspider_redis‘
redis_key = ‘myspider:start_urls‘
def __init__(self, *args, **kwargs):
# Dynamically define the allowed domains list.
domain = kwargs.pop(‘domain‘, ‘‘)
self.allowed_domains = filter(None, domain.split(‘,‘))
super(MySpider, self).__init__(*args, **kwargs)
def parse(self, response):
return {
‘name‘: response.css(‘title::text‘).extract_first(),
‘url‘: response.url,
}四.啟動爬蟲:
$ scrapy crawl myspider可以輸入多個來觀察多進程的效果。。打開了爬蟲之後你會發現爬蟲處於等待爬取的狀態,是因為list此時為空。所以需要在redis控制臺中添加啟動地址,這樣就可以愉快的看到所有的爬蟲都動起來啦。
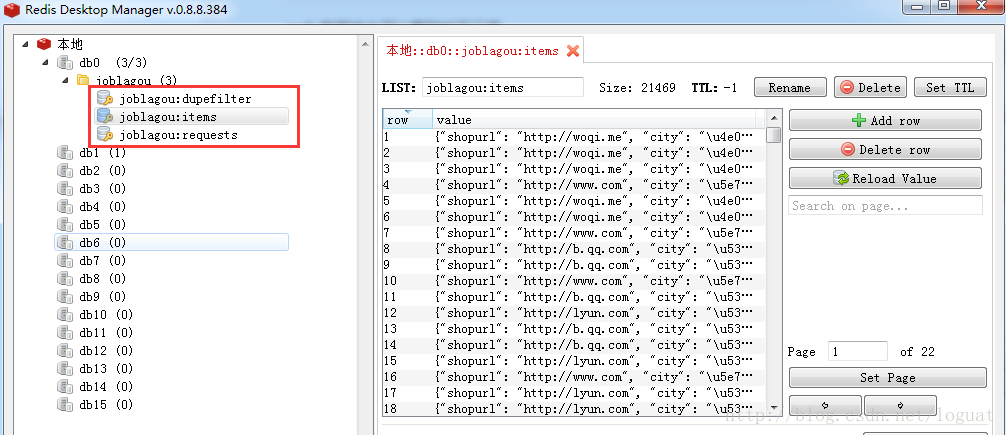
lpush mycrawler:start_urls http://www.***.comredis數據庫中可以看到如下三項,第一個為已過濾並下載的request,第二個公用item,第三個為待處理request。
Scrapy-redis改造scrapy實現分布式多進程爬取